目录
前言
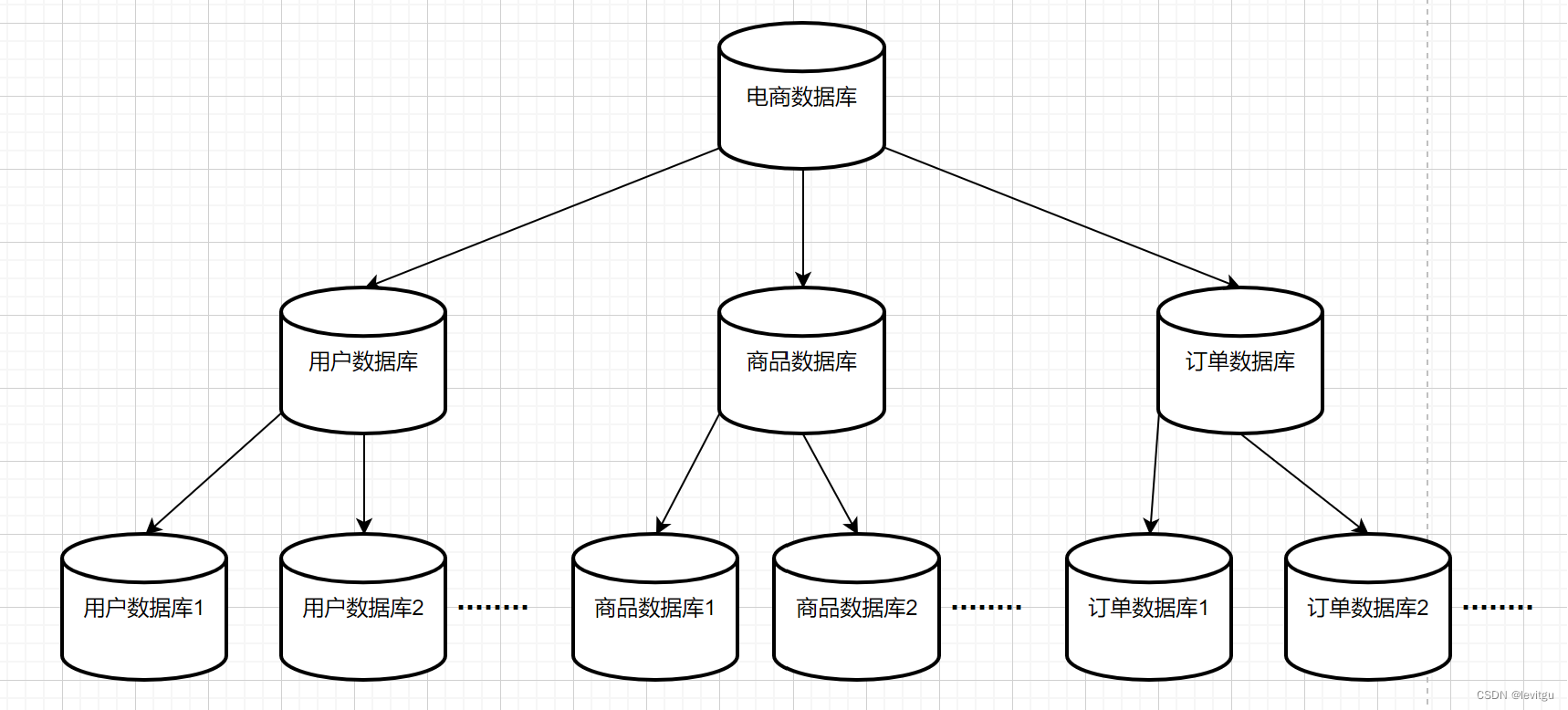
如果单表的数据量过大,则会影响查询效率。想要解决这个问题,显然,直接拆分就完事了。一张表的数据量过多,那么进行分表,将数据分散到多张表中,每张表中的数据自然就不多了,问题就迎刃而解了。
针对单表数据量大的情况,分库分表就是一个通用的解决方案。可以细分为三种:
- 只分表不分库:主要用于解决单表数据量大问题
- 只分库不分表:主要用于解决数据库并发量大问题
- 分库分表:解决并发量大且数据量大问题
在实际工作中,虽然没有遇到过并发量过大需要分库,也没遇到过单表数据量过大不得不分表的情况,但是在实践中也设计过分表,主要是缓解老板对数据持续增长导致单表数据量过大影响查询效率的焦虑,就在设计表结构时做了冗余设计,考虑了以后数据量过大的问题,就预先对数据量会比较多的表进行了分表。
如何分表
定下来要分表的技术方案后,那么就要考虑怎么分表了,按什么来分?
分表字段
分表字段需要根据实际的业务情况来确定,以公司的业务为例,公司的产品是一个多租户的互联办公saas平台,每个企业相当于一个租户,不同的企业之间数据相互隔离。所有的业务中基本上都会有一个企业id,所以在进行分表时,就是根据企业id来进行分表的。
这么分表的一个好处就是,同一个企业下的所有数据都会分配到同一张表下,这样能够避免分表带来的跨表分页查询,联表查询,排序问题。
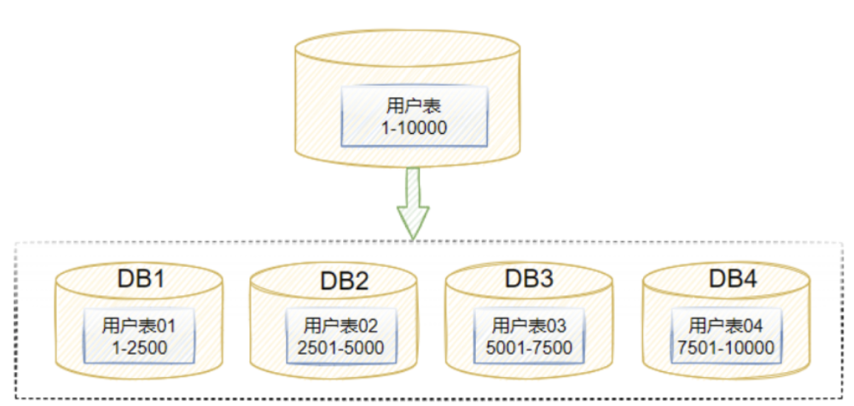
分表数量
确定了分表的字段,接下来就要确定分表的数量了,同样是根据实际业务情况,预估数据量的大小来确定分表的数量,但是数量一定要是2的整数幂。
类似于HashMap的扩容算法
选择2的整数幂作为扩容的大小是因为HashMap内部的计算哈希索引的方法是通过对数组长度取余,使用2的整数幂作为数组长度,可以通过位运算实现取余操作,这比使用除法运算更加高效。
同理,使用2的整数幂来分表,就能够使用位运算来提高效率。
JDK1.8 的HashMap在扩容时,不需要重新计算元素的hash进行元素迁移。
而是用原先位置key的hash值与原数组的长度(oldCap)进行"与"操作。
- 如果结果是0,那么当前元素的桶位置不变。
- 如果结果为1,那么桶的位置就是原位置+原数组 长度
同理,在二次分表时,不用将原有的数据全部都再分一遍。只需将分表字段的hash值与原分表数量进行与(&)操作。
- 如果结果为0,那么数据不用迁移
- 如果结果为1,则将数据迁移到 原分表索引号 + 原分表数量(例如:二次分表前只有 2 张分表 t0 t1;那么二次分表后就会有 4 张分表 t0 t1 t2 t3;如果 t0 中的某条数据分表字段的hash值与原分表数量(2)的与(&)操作结果为1,那么这条数据就要迁移到 0 + 2,也就 t3 这张表中)
分表算法
确定了分表字段和分表数量后,就可以确定分表算法了
实际上就是根据分表数量取模而已,分表数量时2的整数幂的话,则可以用位运算代理
如果分表字段本身就是数值,那么就可以直接对分表字段进行取模
若分表字段不是纯数值,则需要先进行一遍hash后,再进行取模
以上是根据实际业务确定的分表字段后的分表方案
实际上有些业务可以通过一些关键字来分表,比如 日期,地区 等等来进行分表,按这些关键字来分表的,其实就不需要考虑什么分表字段和分表数量了,不需要取模得到分表索引了。每个关键字做后缀就是一张分表了。
分表带来的问题
跨库事务
如果涉及到跨库事务,最省事的方法实际上就是直接上分布式事务中间件了,比如 Seata
本文只讨论分表的情况,跨库事务实际项目中没有实践过,个人感觉分布式事务实在是太重了,不到万不得已真的不想引入。(这题我不会)
分页查询,排序问题
确定好分表字段后,可以确保业务上的关键查询的数据都在同一张表下,这些问题就可以转换为单表下的分页查询,排序问题了。
但是这并不是一劳永逸的,以上解决的只是使用分表字段的关键查询,若是要用非分表字段来做查询,这些问题时避免不了的。如果业务上一定存在这些查询的话,那么就需要将这些数据同步到 ES 中来做查询了。
联表问题
显然,在分表数量不多的时候,在代码中直接一张张表去做联表查询,然后再汇总,确实能够解决,但是分表的数量一旦多起来,就显得很笨了,使用 shardingsphere 中间件实际上是同样的,只不过是由自己手动写代码变成了 shardingsphere 来做
针对联表问题,使用数据冗余来解决是相对优雅的,利用空间来换取时间。
或者也可以将数据同步到 ES 中,交给 ES 来做查询
二次分表
使用2的整数幂来扩容分表数量,详情参考上面如何分表的描述
一致性ID
传统单表的ID是通过自增主键来生成,但是分表后由多张表显然就无法使用自增ID了,虽然可以每张表使用不同的步长来做自增主键,但是面临二次分表的话,所有的主键又得重新更改了,而且步长也得做调整,这种方案显然只能用在一开始就确定不用二次分表的业务场景中。
使用UUID的话,虽然保证了一致性,但是不是有序的ID,每次插入都有可能导致底层数据结构重新排序一遍,严重影响效率。
最好的方法就是使用现成的雪花算法,生成的ID总共有64个bit
1 bit 符号位 41 bit 时间戳位 10 bit 工作进程位置 12 bit 序列号位
每毫秒最多生成 1024 * 4096 = 4194304 个ID
在一般的小公司的业务中,使用雪花算法确实有点杀鸡用宰牛刀的感觉,实际上自己也可以基于时间戳来生成一个一致性ID,应付小公司的业务绰绰有余了,代码能跑就行,早点下班。