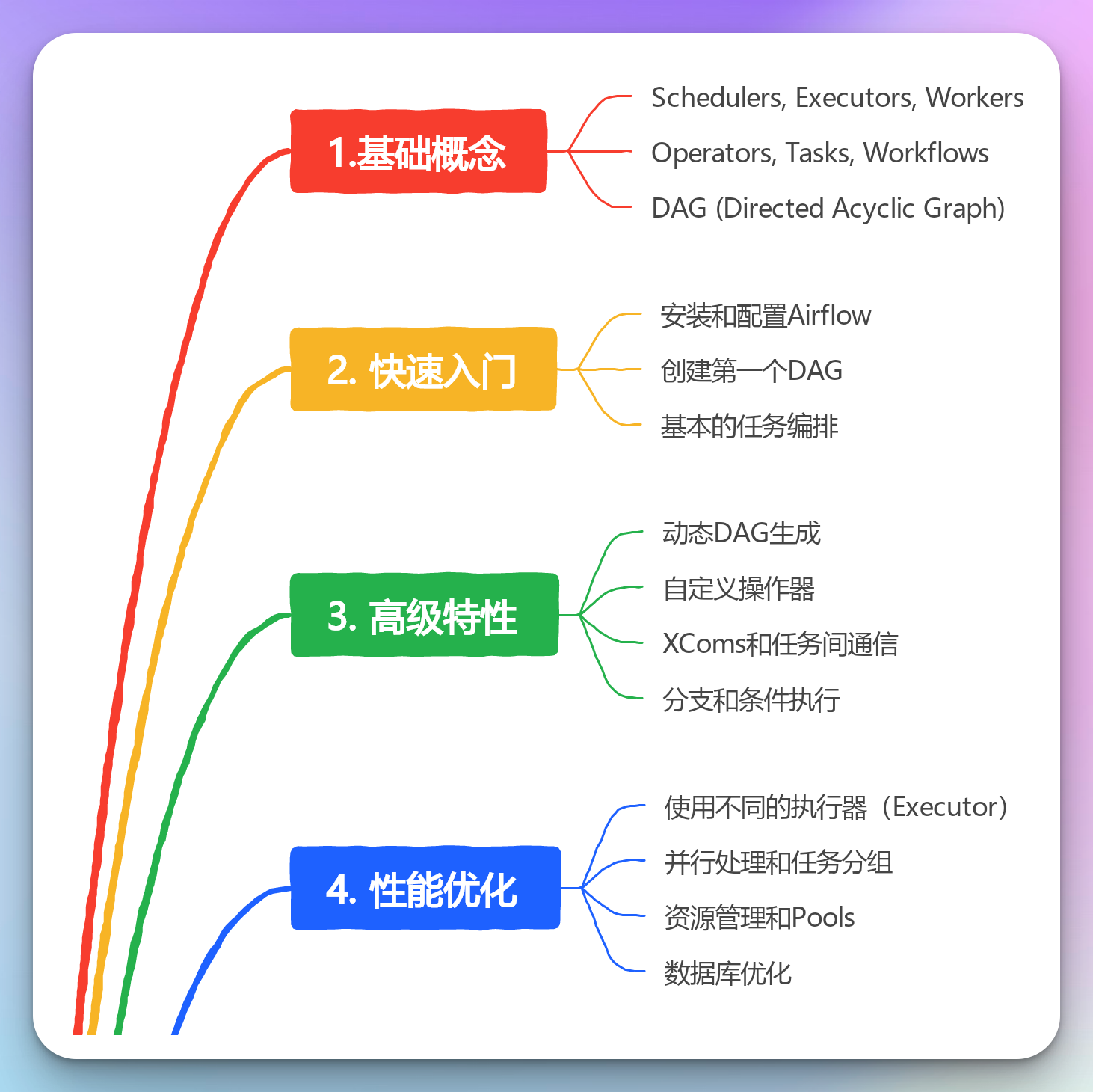
引言
还记得第一次面对Linux命令行时的茫然吗?黑乎乎的终端,闪烁的光标,还有那些看起来像外星文的命令。
作为一个从0基础开始跨行到大数据领域的开发者,我深深体会到了学习Linux的重要性和挑战。今天,我想和大家分享我的学习经验,告诉你如何以"糙快猛"的方式征服Linux,在不完美中进步,在实践中成长。

Linux:大数据的基石
首先,让我们明确一个概念:Linux是什么?
Linux是一种自由和开放源代码的类Unix操作系统,是大数据生态系统的基础设施。它以其稳定性、安全性和灵活性,成为了大数据处理、存储和分析的首选平台。
对于大数据开发者来说,掌握Linux就像武林高手练就了一身硬功夫。它不仅是你日常工作的环境,更是你构建、部署和维护大数据系统的得力助手。

我的Linux学习之路:从懵懂到"叉会腰"
还记得我刚开始学习Linux的时候,那感觉就像是被扔进了深海。命令行?文件系统?进程管理?这些概念就像是一个个水母,看起来美丽却难以捕捉。但是,我选择了"糙快猛"的学习方式,这让我在短时间内从一个"旱鸭子"变成了能在Linux海洋中自由游动的"鱼"。

糙快猛的实践案例
举个例子,当我第一次尝试在Linux上部署Hadoop集群时,我遇到了这样一个错误:
$ ./start-dfs.sh
Starting namenodes on [localhost]
localhost: Permission denied (publickey,password).
Starting datanodes
localhost: Permission denied (publickey,password).
Starting secondary namenodes [big-data-1]
big-data-1: Permission denied (publickey,password).

看到这个错误,我的第一反应是慌乱。但我很快调整心态,开始"糙快猛"地解决问题:
- 糙:不求完美,先解决眼前的问题。我快速Google了一下错误信息。
- 快:找到可能的解决方案后,立即尝试。我尝试了设置SSH免密登录。
- 猛:大胆尝试,不怕出错。即使不太懂原理,我也勇敢地输入了以下命令:
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
执行完这些命令后,我再次尝试启动Hadoop,竟然成功了!那一刻,我感觉自己简直可以"叉会腰"了。
学习Linux的"糙快猛"之道

基于我的经验,我总结出了学习Linux的几个关键点:
从基础开始,但不要纠结
- 学习基本的Linux命令(如ls, cd, mkdir, rm等)
- 理解文件系统结构
- 但不要试图一次性掌握所有内容
实践,实践,再实践
- 搭建你自己的Linux环境(可以使用虚拟机或WSL)
- 尝试完成一个小项目,比如搭建一个简单的Web服务器
拥抱错误,从错误中学习
- 不要害怕看到错误信息
- 学会阅读和理解错误日志
- 使用Google和Stack Overflow寻求帮助

利用现代工具,但不要完全依赖
- 使用ChatGPT等AI助手来解答疑惑
- 但要记住,理解原理比直接得到答案更重要
建立你的Linux知识体系
- 从Shell脚本开始,逐步深入到系统管理
- 学习版本控制(如Git),这在Linux环境中非常重要
- 尝试自动化你的工作流程
本章小结
记住,学习Linux和大数据开发是一个持续的过程。不要期望一蹴而就,而是要在实践中不断进步。正如我们在大数据处理中经常说的:
def learn_linux():
while True:
try:
practice()
learn_from_mistakes()
improve()
except Perfection:
break
else:
continue
learn_linux()
这个简单的Python代码片段展示了学习Linux的精髓:持续实践,从错误中学习,不断改进。只有当你达到"完美"时才会跳出循环,但实际上,这个循环永远不会结束,因为在技术的世界里,永远有新的东西要学习。
所以,准备好了吗?让我们一起以"糙快猛"的姿态,征服Linux,在大数据的海洋中畅游吧!
什么是"糙快猛"学习法?

"糙快猛"学习法强调:
- 糙:不追求完美,先掌握核心概念
- 快:快速实践,在使用中学习
- 猛:勇于尝试,不怕犯错
这种方法特别适合在工作中学习Linux,因为它允许我们在实际问题中成长,而不是陷入理论的海洋。
Linux学习路线图
1. 基础命令(1-2周)

首先,我们需要掌握一些基本的Linux命令。这些命令将是我们日常工作的基石。
- 文件操作:
ls,cd,cp,mv,rm - 文本处理:
cat,grep,sed,awk - 系统信息:
top,df,du,free
实践任务:创建一个脚本,自动统计日志文件中的错误信息。
#!/bin/bash
# error_count.sh
grep "ERROR" /var/log/myapp.log | awk '{print $1}' | sort | uniq -c
2. Shell脚本(2-3周)
学会编写Shell脚本可以大大提高我们的工作效率。
- 变量和环境变量
- 条件语句和循环
- 函数
实践任务:编写一个脚本,监控Hadoop集群的磁盘使用情况。
#!/bin/bash
# hadoop_disk_monitor.sh
THRESHOLD=80
for node in $(hdfs dfsadmin -report | grep 'Name:' | awk '{print $2}')
do
usage=$(ssh $node 'df -h | grep "/hadoop" | awk '{print $5}' | cut -d'%' -f1')
if [ $usage -gt $THRESHOLD ]; then
echo "Warning: $node disk usage is $usage%"
fi
done
3. 系统管理(3-4周)
了解Linux系统管理对于维护大数据集群至关重要。
- 用户和权限管理
- 进程管理
- 网络配置
实践任务:配置一个新的Hadoop数据节点。
# 1. 创建Hadoop用户
sudo adduser hadoop
# 2. 配置SSH无密码登录
su - hadoop
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
# 3. 安装Java和Hadoop
sudo apt update
sudo apt install openjdk-8-jdk
# 下载并解压Hadoop
tar -xzf hadoop-3.3.1.tar.gz
4. 性能优化(4-6周)

学习如何优化Linux系统性能,这对于大数据处理至关重要。
- 内存管理和调优
- I/O优化
- 网络性能优化
实践任务:优化Hadoop集群的内存使用。
# 编辑Hadoop配置文件
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
# 添加或修改以下配置
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>40960</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
5. 故障排除(持续学习)

学习如何诊断和解决Linux系统问题。
- 日志分析
- 系统监控
- 常见问题排查
实践任务:创建一个检查Hadoop服务状态的脚本。
#!/bin/bash
# check_hadoop_services.sh
services=("namenode" "datanode" "resourcemanager" "nodemanager")
for service in "${services[@]}"
do
if pgrep -f $service > /dev/null
then
echo "$service is running"
else
echo "$service is not running"
echo "Starting $service..."
$HADOOP_HOME/sbin/hadoop-daemon.sh start $service
fi
done
实战项目:构建一个大数据日志分析系统

现在,让我们把学到的知识整合起来,构建一个实际的项目。
项目概述
我们将创建一个系统,收集多个服务器的日志,存储到HDFS,然后使用Spark进行分析。
步骤1:日志收集
使用rsyslog将日志集中到一个服务器。
# 在日志服务器上配置rsyslog
# 编辑 /etc/rsyslog.conf
$ModLoad imudp
$UDPServerRun 514
# 重启rsyslog
sudo systemctl restart rsyslog
步骤2:将日志导入HDFS
创建一个脚本,定期将日志文件移动到HDFS。
#!/bin/bash
# move_logs_to_hdfs.sh
log_dir="/var/log"
hdfs_dir="/logs/$(date +%Y-%m-%d)"
# 创建HDFS目录
hdfs dfs -mkdir -p $hdfs_dir
# 移动日志文件到HDFS
for log_file in $log_dir/*.log
do
hdfs dfs -put $log_file $hdfs_dir
rm $log_file
done
步骤3:使用Spark分析日志
编写一个Spark作业来分析日志。
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, regexp_extract
spark = SparkSession.builder.appName("LogAnalysis").getOrCreate()
# 读取日志文件
logs = spark.read.text("/logs/2024-07-21/*.log")
# 提取有用的信息
parsed_logs = logs.select(
regexp_extract('value', r'^(\S+)', 1).alias('ip'),
regexp_extract('value', r'.*\[(.*)\]', 1).alias('date'),
regexp_extract('value', r'.*"(\S+)\s+(\S+)\s+(\S+)"', 2).alias('url'),
regexp_extract('value', r'.*"\s+(\d+)', 1).cast('integer').alias('status')
)
# 分析结果
error_count = parsed_logs.filter(col('status') >= 400).count()
top_urls = parsed_logs.groupBy('url').count().orderBy('count', ascending=False).limit(10)
# 输出结果
print(f"Total errors: {error_count}")
top_urls.show()
实际工作场景与问题解决
在大数据开发中,我们经常会遇到各种各样的问题。以下是一些常见场景和相应的Linux解决方案:

场景1:Hadoop集群内存不足
问题:Hadoop作业频繁失败,日志显示内存不足。
解决方案:
- 检查系统内存使用情况:
free -h
top
- 查看Hadoop配置中的内存设置:
cat $HADOOP_HOME/etc/hadoop/yarn-site.xml | grep memory
- 调整Yarn内存配置:
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
# 修改以下配置
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>40960</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
- 重启Yarn服务:
$HADOOP_HOME/sbin/stop-yarn.sh
$HADOOP_HOME/sbin/start-yarn.sh
场景2:磁盘空间不足
问题:HDFS报告空间不足,但Linux文件系统显示还有可用空间。
解决方案:
- 检查HDFS使用情况:
hdfs dfs -df -h
- 检查Linux文件系统使用情况:
df -h
- 清理HDFS中的临时文件和过期数据:
hdfs dfs -rm -r /tmp/*
hdfs dfs -expunge
- 如果问题持续,可能需要添加新的数据节点或扩展现有节点的存储。
场景3:Spark作业执行缓慢
问题:Spark作业执行时间异常长。
解决方案:
检查Spark UI,查看作业的详细信息和瓶颈。
使用
top命令检查系统资源使用情况:
top
- 检查并优化Spark配置:
vi $SPARK_HOME/conf/spark-defaults.conf
# 调整以下参数
spark.executor.memory 4g
spark.driver.memory 4g
spark.executor.cores 2
- 如果数据倾斜是问题所在,考虑在Spark代码中使用重分区操作:
df = df.repartition(100)
学习技巧和最佳实践

建立个人知识库:使用工具如Notion或简单的Markdown文件,记录你学到的每个Linux命令和解决方案。
模拟实际环境:使用虚拟机或Docker容器搭建一个小型Hadoop集群,进行实践。
参与开源项目:尝试为Hadoop、Spark等项目贡献代码,这将极大地提升你的Linux和大数据技能。
定期复习:每周花一些时间回顾你的笔记和学习内容,巩固知识。
教是最好的学:尝试向他人解释Linux概念,或写技术博客分享你的学习心得。
进阶学习路径
当你掌握了基础知识后,可以考虑以下进阶主题:
容器化技术:学习Docker和Kubernetes,了解如何容器化大数据应用。
自动化运维:学习Ansible或Puppet,实现大数据集群的自动化部署和管理。
云计算平台:了解如何在AWS、GCP或Azure上部署和管理Linux服务器和大数据服务。
安全性:深入学习Linux安全配置,包括SELinux、防火墙设置等。
性能调优:学习更高级的性能调优技术,如使用perf进行系统性能分析。
实践项目:构建实时日志分析系统

为了将我们学到的知识付诸实践,让我们一起完成一个实际的项目:构建一个实时日志分析系统。这个项目将涵盖Linux系统管理、Shell脚本编写、大数据工具使用等多个方面。
项目概述
我们将创建一个系统,实时收集多个服务器的日志,使用Kafka进行数据流处理,然后用Spark Streaming进行实时分析,最后将结果存储到Elasticsearch中以便可视化。
步骤1:配置日志收集
- 在每台服务器上安装和配置Filebeat:
# 下载和安装Filebeat
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.13.0-amd64.deb
sudo dpkg -i filebeat-7.13.0-amd64.deb
# 配置Filebeat
sudo vi /etc/filebeat/filebeat.yml
# 添加以下配置
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
output.kafka:
hosts: ["kafka1:9092", "kafka2:9092"]
topic: "logs"
# 启动Filebeat
sudo systemctl start filebeat
步骤2:设置Kafka集群
- 安装和配置Kafka:
# 下载Kafka
wget https://downloads.apache.org/kafka/2.8.0/kafka_2.13-2.8.0.tgz
tar -xzf kafka_2.13-2.8.0.tgz
cd kafka_2.13-2.8.0
# 启动Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties &
# 启动Kafka服务器
bin/kafka-server-start.sh config/server.properties &
# 创建topic
bin/kafka-topics.sh --create --topic logs --bootstrap-server localhost:9092
步骤3:创建Spark Streaming作业
- 创建一个新的Scala项目,添加以下依赖:
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-sql" % "3.1.2",
"org.apache.spark" %% "spark-streaming" % "3.1.2",
"org.apache.spark" %% "spark-streaming-kafka-0-10" % "3.1.2",
"org.elasticsearch" %% "elasticsearch-spark-30" % "7.13.0"
)
- 创建Spark Streaming作业:
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.sql.SparkSession
object LogAnalysis {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder.appName("LogAnalysis").getOrCreate()
val ssc = new StreamingContext(spark.sparkContext, Seconds(5))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "log_analysis_group",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("logs")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)
)
val lines = stream.map(_.value)
// 进行日志分析
val errorCounts = lines.filter(_.contains("ERROR")).map((_ , 1)).reduceByKey(_ + _)
// 将结果保存到Elasticsearch
errorCounts.foreachRDD { rdd =>
rdd.saveToEs("log_stats/errors")
}
ssc.start()
ssc.awaitTermination()
}
}
步骤4:配置Elasticsearch和Kibana
- 安装和启动Elasticsearch:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.0-linux-x86_64.tar.gz
tar -xzf elasticsearch-7.13.0-linux-x86_64.tar.gz
cd elasticsearch-7.13.0
bin/elasticsearch
- 安装和启动Kibana:
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.13.0-linux-x86_64.tar.gz
tar -xzf kibana-7.13.0-linux-x86_64.tar.gz
cd kibana-7.13.0-linux-x86_64
bin/kibana
- 在Kibana中创建索引模式和可视化。
高级故障排除技巧

在处理复杂的Linux和大数据系统时,我们常常会遇到一些棘手的问题。以下是一些高级故障排除技巧:
1. 使用strace跟踪系统调用
当程序行为异常但没有明显错误信息时,strace可以帮助我们了解程序在系统级别的行为:
strace -f -e trace=network,read,write java -jar myapp.jar
这将跟踪myapp.jar的网络、读取和写入系统调用。
2. 使用tcpdump分析网络问题
当遇到网络相关问题时,tcpdump可以帮助我们捕获和分析网络流量:
sudo tcpdump -i eth0 -n port 9092
这将捕获eth0接口上9092端口(Kafka的默认端口)的所有流量。
3. 使用jstat分析Java应用性能
对于Java应用(如Hadoop、Spark等),jstat可以帮助我们监控JVM的性能:
jstat -gcutil <pid> 1000 10
这将每秒输出一次指定进程的GC统计信息,共输出10次。
4. 使用perf进行系统级性能分析
perf是一个强大的Linux性能分析工具:
sudo perf top -p <pid>
这将实时显示指定进程的CPU使用情况。
5. 使用sar分析系统资源使用情况
sar可以帮助我们了解系统随时间变化的资源使用情况:
sar -u 1 10 # CPU使用情况
sar -r 1 10 # 内存使用情况
sar -b 1 10 # I/O和传输速率
这些命令将每秒收集一次数据,共收集10次。
最佳实践和注意事项
日志管理:集中化日志管理对于大规模系统至关重要。考虑使用ELK栈(Elasticsearch, Logstash, Kibana)或Graylog。
监控:实施全面的监控策略。Prometheus + Grafana是一个很好的选择。
自动化:尽可能自动化日常任务。考虑使用Ansible或Puppet进行配置管理。
安全性:定期更新系统和应用,使用强密码,限制SSH访问,配置防火墙。
备份:实施可靠的备份策略,并定期测试恢复过程。
文档:保持文档的更新,记录系统配置、变更历史和故障排除步骤。
本章结语

通过这个实践项目和高级故障排除技巧,我们可以看到Linux知识在大数据领域的实际应用。记住,"糙快猛"的学习方法并不意味着忽视细节,而是鼓励我们在实践中学习,不断迭代和改进。
在你的Linux和大数据学习之旅中,保持好奇心和实践精神至关重要。不要害怕犯错,因为每一个错误都是一次学习的机会。同时,也要记得与社区分享你的知识和经验,因为教学相长往往是最好的学习方式。
最后,让我们用一个简单的Shell脚本来表达持续学习和改进的理念:
#!/bin/bash
function learn_and_improve() {
while true; do
echo "1. 学习新知识"
echo "2. 实践项目"
echo "3. 分析问题"
echo "4. 优化系统"
echo "5. 分享经验"
echo "6. 休息"
read -p "选择你的下一步 (1-6): " choice
case $choice in
1) echo "学习中..." ; sleep 2 ;;
2) echo "实践中..." ; sleep 2 ;;
3) echo "分析中..." ; sleep 2 ;;
4) echo "优化中..." ; sleep 2 ;;
5) echo "分享中..." ; sleep 2 ;;
6) echo "休息中..." ; sleep 5 ;;
*) echo "无效选择,请重新选择" ;;
esac
done
}
learn_and_improve
记住,在Linux和大数据的世界里,学习是一个永无止境的过程。保持"糙快猛"的态度,但也要懂得何时放慢脚步,深入思考。祝你在这个充满挑战和机遇的技术世界中不断进步,享受学习和成长的乐趣!
高级性能优化策略

在大数据环境中,系统性能直接影响到数据处理的效率。以下是一些高级的性能优化策略:
1. 文件系统优化
选择合适的文件系统对于大数据工作负载至关重要。
XFS vs Ext4
对于大文件和高并发写入,XFS通常表现更好:
# 创建XFS文件系统
mkfs.xfs /dev/sdb
# 挂载时启用日志优化
mount -o logbsize=256k /dev/sdb /data
调整文件系统参数
# 增加inode数量,适用于存储大量小文件的场景
mkfs.ext4 -N 2000000 /dev/sdc
# 禁用atime更新,减少不必要的I/O
mount -o noatime /dev/sdb /data
2. 内核参数调优
适当调整内核参数可以显著提升系统性能。
# 编辑sysctl配置文件
vi /etc/sysctl.conf
# 增加文件描述符限制
fs.file-max = 2097152
# 增加网络队列长度
net.core.netdev_max_backlog = 250000
# 增加TCP最大连接数
net.core.somaxconn = 4096
# 应用更改
sysctl -p
3. I/O调度器优化
为SSD选择合适的I/O调度器可以提升性能:
# 对于SSD,使用noop或deadline调度器
echo noop > /sys/block/sda/queue/scheduler
# 永久化设置
echo 'ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="noop"' > /etc/udev/rules.d/60-schedulers.rules
4. 网络优化
在分布式系统中,网络性能至关重要:
# 增加TCP缓冲区大小
sysctl -w net.ipv4.tcp_rmem="4096 87380 16777216"
sysctl -w net.ipv4.tcp_wmem="4096 65536 16777216"
# 启用TCP BBR拥塞控制算法(内核版本 >= 4.9)
sysctl -w net.core.default_qdisc=fq
sysctl -w net.ipv4.tcp_congestion_control=bbr
5. NUMA awareness
在NUMA架构的系统中,确保进程使用本地内存可以提升性能:
# 安装numactl
apt-get install numactl
# 运行Java应用时绑定到特定的NUMA节点
numactl --cpunodebind=0 --membind=0 java -jar myapp.jar
大规模分布式系统中的Linux应用
在管理大规模分布式系统时,Linux知识变得尤为重要。以下是一些关键概念和技巧:
1. 配置管理
使用配置管理工具可以大大简化大规模系统的管理:
# Ansible playbook 示例
- name: Configure Hadoop nodes
hosts: hadoop_cluster
tasks:
- name: Install Java
apt:
name: openjdk-8-jdk
state: present
- name: Copy Hadoop configuration
template:
src: hadoop-site.xml.j2
dest: /etc/hadoop/hadoop-site.xml
- name: Start Hadoop services
systemd:
name: hadoop-{{item}}
state: started
loop:
- namenode
- datanode
2. 容器化和编排
使用Docker和Kubernetes可以简化部署和扩展:
# Kubernetes Deployment 示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: spark-worker
spec:
replicas: 3
selector:
matchLabels:
app: spark-worker
template:
metadata:
labels:
app: spark-worker
spec:
containers:
- name: spark-worker
image: spark:latest
command: ["/bin/sh"]
args: ["-c", "/spark/sbin/start-worker.sh spark://spark-master:7077"]
3. 日志聚合
在分布式系统中,集中化日志管理变得尤为重要:
# Filebeat 配置示例
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/hadoop/*.log
- /var/log/spark/*.log
output.elasticsearch:
hosts: ["elasticsearch:9200"]
4. 监控和告警
实施全面的监控策略对于保证系统健康至关重要:
# Prometheus 配置示例
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'hadoop'
static_configs:
- targets: ['hadoop-namenode:9870', 'hadoop-datanode:9864']
- job_name: 'spark'
static_configs:
- targets: ['spark-master:8080', 'spark-worker:8081']
5. 自动化运维
使用脚本自动化日常运维任务:
#!/bin/bash
# 自动化数据备份脚本
# 设置变量
BACKUP_DIR="/mnt/backup"
HADOOP_DIR="/user/hadoop"
DATE=$(date +%Y%m%d)
# 创建备份目录
mkdir -p $BACKUP_DIR/$DATE
# 使用distcp进行备份
hadoop distcp $HADOOP_DIR $BACKUP_DIR/$DATE
# 删除7天前的备份
find $BACKUP_DIR -type d -mtime +7 -exec rm -rf {} \;
# 检查备份状态并发送邮件通知
if [ $? -eq 0 ]; then
echo "Backup completed successfully" | mail -s "Hadoop Backup Status" admin@example.com
else
echo "Backup failed" | mail -s "Hadoop Backup Status" admin@example.com
fi
持续学习和职业发展
在快速发展的技术领域,持续学习至关重要。以下是一些建议:
参与开源项目:贡献代码到Hadoop、Spark等项目,这可以极大地提升你的技能。
关注技术博客:定期阅读Netflix Tech Blog、Uber Engineering Blog等,了解业界最新实践。
参加技术会议:如Strata Data Conference、Spark Summit等,与其他专业人士交流。
考取相关认证:如Linux Foundation Certified System Administrator (LFCS)、Cloudera Certified Administrator for Apache Hadoop (CCAH)等。
实践、实践、再实践:在自己的个人项目中应用所学知识,这是最有效的学习方式。
结语
通过深入探讨高级性能优化策略和大规模分布式系统中的Linux应用,我们可以看到Linux在大数据领域的重要性和深度。"糙快猛"的学习方法让我们能够快速上手,但真正的掌握需要持续的学习和实践。
记住,每一个复杂的问题都是由简单的问题组成的。当你面对看似insurmountable的挑战时,试着将其分解成小的、可管理的部分。使用我们讨论过的工具和技术,一步一步地解决问题。
最后,让我们用一个Python脚本来模拟这个持续学习和问题解决的过程:
import random
import time
def learn_linux_bigdata():
skills = ["Linux基础", "Shell脚本", "性能优化", "分布式系统", "容器化", "自动化运维"]
problems = ["内存溢出", "网络延迟", "磁盘I/O瓶颈", "数据倾斜", "集群扩展"]
while True:
print("\n新的一天开始了!")
# 学习新技能
new_skill = random.choice(skills)
print(f"今天学习了新技能:{new_skill}")
time.sleep(1)
# 解决问题
problem = random.choice(problems)
print(f"遇到了问题:{problem}")
time.sleep(1)
print("正在思考解决方案...")
time.sleep(2)
print("问题解决!")
# 复盘和总结
print("回顾今天的收获,记录在学习笔记中")
time.sleep(1)
print("休息一下,准备迎接明天的挑战")
time.sleep(3)
if __name__ == "__main__":
learn_linux_bigdata()
这个脚本虽然简单,但它反映了我们在Linux和大数据领域学习和工作的日常:不断学习新知识,解决各种问题,然后总结经验。记住,在这个过程中保持耐心和好奇心,相信通过持续的努力,你一定能成为Linux和大数据领域的专家!
祝你在Linux和大数据的学习之路上收获满满,享受技术带来的乐趣和挑战!
思维导图
同系列文章
用粗快猛 + 大模型问答 + 讲故事学习方式快速掌握大数据技术知识