学习日期:2024.7.22
内容摘要:TCP的流量控制与拥塞控制
流量控制
一般来说,我们总是希望数据传输的快一些,但是如果数据传输的太快,接收方可能就来不及接收,这就会导致数据的丢失,流量控制正是为了避免这一现象。
所谓流量控制,其实就是让发送方的发送速率不要太快,让接收方来得及接收,所以一定是接收方给发送方流量控制。用滑动窗口机制可以很方便的在TCP上实现对发送方的流量控制。
下面我们举一个例子,在这个例子中,为了方便讨论,我们不考虑拥塞控制,而是认为接收窗口与发送窗口大小相等。

如图,一开始流量窗口是400,A向B发送数据,B给A流量控制。图中第三部分,201~300的字节数据丢失了,B就在确认时,ack=201,意思是201号字节之前的数据都收到了,而rwnd=300的意思是,调整接收窗口为300。

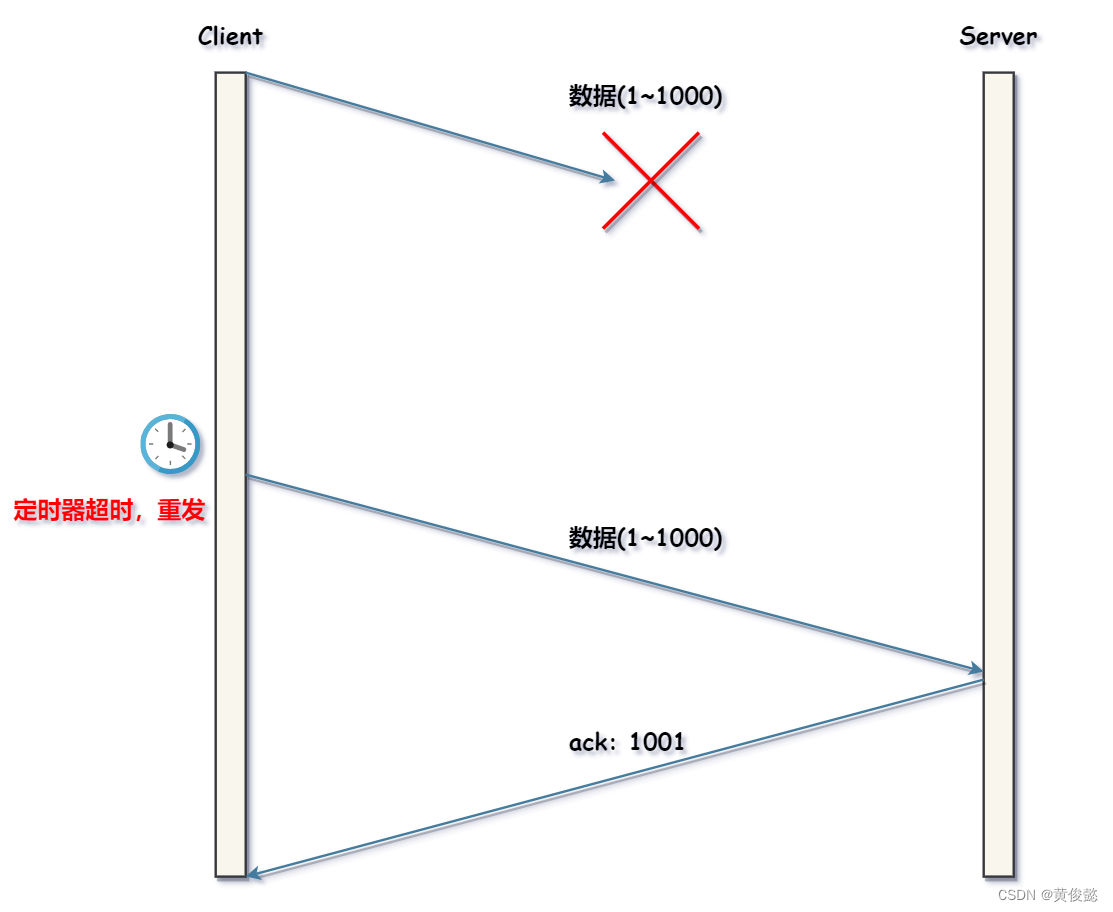
于是,发送窗口被调节为201之后的300个字节,如上图蓝色阴影所示。然后A会从301开始发送(接着上次的)然后发完401~500之后,窗口内的数据已经全部发完,不能再发送新数据了。待重传计时器超时后,A就会开始超时重传旧数据

如图,当主机A超时重传201~300的数据后,主机b就能对收到的501以前的数据进行累计确认,再把接收窗口调整成为100。主机A的发送窗口会调整为501~600,发完这部分数据后,主机A就不能再发送数据了。此时主机B对601号以前的数据进行了累计确认,ACK=1的意思是确认收到,ack=601的意思是601以前的数据,rwnd=0是接收窗口调整为了0。
因为此时接收窗口是0,所以就不能发送一般的TCP报文了,直到B通知A,接收窗口不为0。

但是这样可能导致一个问题,如果主机B的接收窗口扩大了,它想通知主机A,但这个通告在传输过程中丢失了,这会怎么样呢?
主机A会一直等待主机B告诉它传输窗口已经打开了,而主机B会一直等待主机A发送消息,双方会无限等待下去,这样就会导致死锁。A以为B在忙一直等,B以为自己告诉A了,双方又不交流,就死锁了。
为了解决这个问题,TCP规定,如果收到0窗口通知,发送方就要启动一个持续计时器,每隔一段时间发送一个0窗口探测报文,仅携带1字节数据。就好比A隔一段时间问一下B,“在吗?”,如果B的接收窗口还没调大,就回ACK=1表示收到(确认通信能完成),rwnd=0表示接收窗口为0,就是还在忙。如果可以了,就是rwnd=xxx,这样就能够避免死锁了。
拥塞控制
在某段时间中,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络性能就要变坏,这种情况就叫做拥塞。类比生活中就是堵车,大家都想去一个地方(访问一个处理机),但是路就那么宽,那么就塞车了。
在计算机网络中的链路容量、交换节点中的缓存和处理机等,都叫做“网络的资源”。
若出现拥塞而不进行控制,整个网络的吞吐量将随着输入负荷的增大而下降。

如图,理想的拥塞控制是绿线,在达到阈值前,输入负载始终等于吞吐量,达到之后,吞吐量始终保持最高。这好比公路在达到承载能力上限之前,始终能满负荷运转,而达到之后,即使再多的车来,也能保持以最大限度运转,但塞过车的都知道这是不可能的。
如果无拥塞控制,就是红线,随着车越来越多,大家全部都动不了,最后所有车都堵在路上,吞吐量为0。而实际的拥塞控制,就是要尽量接近理想的拥塞控制。
TCP的拥塞控制主要有慢开始,拥塞避免,快重传,快恢复。
为了方便讨论,我们假定:
①数据是单方向传送的,另一个方向只传送确认
②接收方的缓存空间足够大,因而发送方发送窗口的大小以网络的拥塞程度决定,不考虑接收窗口
③以最大报文段MSS的个数为讨论问题的单位,而非字节
慢开始和拥塞避免

传输轮次:发送方给接收方发送后,到接收方给发送方发回对应的确认报文段的时间,其实就是往返时间RTT,这个时间并不是恒定的,会根据具体的网络情况波动。
慢开始算法的过程很简单,一开始拥塞窗口cwnd为1,发送窗口等于拥塞窗口,之后每轮次2,4,8,16这样指数级增大,直到拥塞窗口大于慢开始门限。然后采用拥塞避免算法,其实就是改为每轮次都线性+1,直到发生超时重传(认为此时网络已经开始拥塞),就把慢开始门限值调节为拥塞时的一半,然后从头再来一遍 慢开始—>拥塞避免。

如图,慢开始门限起初是16,先用慢开始算法,从1开始指数增长到16,然后触发门限值,开始拥塞避免,每次线性+1,直到拥塞窗口为24时,发生了超时重传。此时把门限设置为24的一半,即12,然后从头再慢开始一次,8->16时,改为到门限12,然后从12开始线性增长。
但是这样有个问题,超时重传不一定是网络拥塞,有可能只是报文段在网络中丢失了,这会导致发送方超时重传,并误认为网络发生了拥塞。所以引入了快重传算法。
快重传
所谓“快重传”,就是要发送方尽快进行重传,而不是等到超时重传计时器超时再重传
①要求接收方不要等到字节要发送数据时顺带确认,而要立刻发送确认
②即使收到了失序的报文段,也要对已收到报文段发出重复确认
③发送方一旦收到3个连续的重复确认,就立刻重传相应的报文段,而不是等待超时重传计时器超时

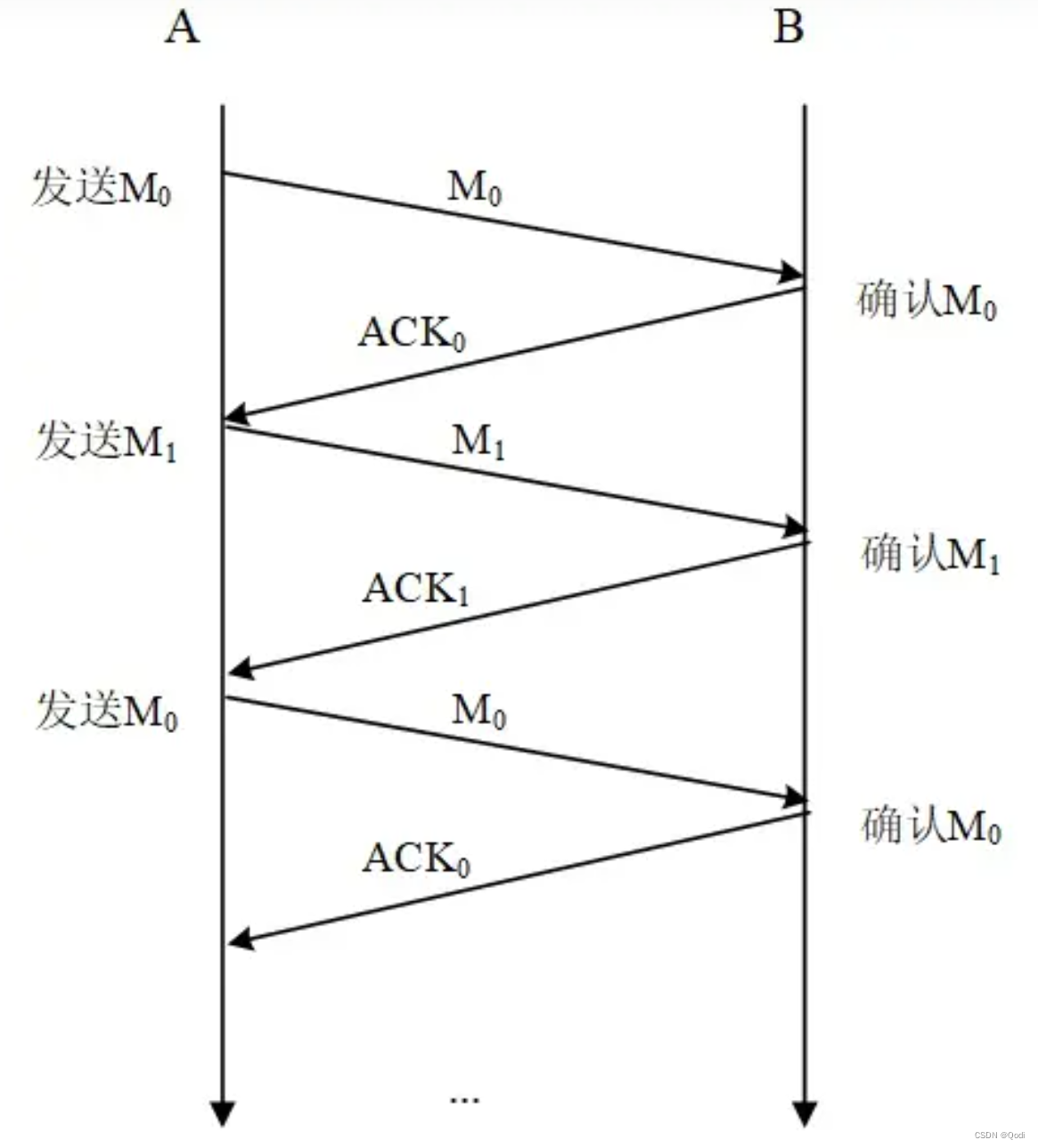
如图,我们还是把发送方和接收方分别命名为A和B
A发送M1,B收到后立刻确认M1,A在收到M1确认前就发送M2,B确认M2,A发送M3,但是此时M3丢失,B不知道,自然不会确认。
于是A发送M4,B发现这不是按顺序到达的报文,于是重复确认自己收到的最晚的一条信息M2,A继续发送M5,B发现这不是按顺序到达的报文,重复确认M2,A发送M6后同理,此时A连续收到了三次对M2的确认,于是A重复发送M3,无需等待M3的超时重传计时器。
B在收到M3后,已经有了M1到M6的报文,所以B确认M6,A就知道B已经收到了M1到M6的报文。
快恢复
快恢复和快重传搭配使用,发送方一旦收到了3个重复确认,就知道现在只是丢失了个别的报文段,于是不使用慢开始算法,而是用快恢复算法,其实就是慢开始算法跳过了“慢开始”部分,而是直接把慢开始门限值和拥塞窗口调整为当前窗口的一半,然后开始执行拥塞避免算法。
说人话就是,拥塞窗口直接减半,然后依旧每次+1线性增长。

如图,第一次慢开始到达门限16,然后线性增长到24,发生超时重传,门限改为12,慢开始到12,然后线性增长到16,然后发生快重传,快恢复到8,继续线性增长。
感谢您看到这里,如果满意的话麻烦您点个赞支持一下,主页还有更多内容分享。
内容总结自bilibili用户 湖科大教书匠的《计算机网络微课堂》和中国工信出版集团《图解TCP/IP》




![[Linux][<span style='color:red;'>网络</span>][TCP][四][<span style='color:red;'>流量</span><span style='color:red;'>控制</span>][<span style='color:red;'>拥塞</span><span style='color:red;'>控制</span>]详细讲解](https://img-blog.csdnimg.cn/direct/fd0591a58d9e46429d622c3c99d17d92.png)