0、汇总
1.可以使用 Maven 命令、CURL 命令、IDEA 手动创建 Flink 项目;
2.可以使用 Maven Shade 插件将必需的依赖项打包进应用程序 jar 中;
3.应该在 Flink 集群的 lib 文件夹内配置需要的(核心)依赖项;
4.应该将程序中(核心)依赖项的生效范围置为 provided(需要对它们编译,但不应将它们打包进项目生成的应用程序 JAR 文件中),避免与集群一些依赖项的版本冲突;
4.flink-connector- 是一个精简 JAR,仅包括连接器代码,但不包含最终的第三方依赖项;flink-sql-connector- 是一个包含连接器第三方依赖项的 uber JAR;
5.uber/fat JAR 主要与 SQL 客户端一起使用,但也可以在任何 DataStream/Table 应用程序中使用它们;
6.某些连接器可能没有相应的 flink-sql-connector- 组件,因为它们不需要第三方依赖项。
7.Flink 发行版的 lib 目录里包括常用模块在内的各种 JAR 文件,若要禁止加载只需将它们从 classpath 中的 lib 目录中删除即可;
8.Flink 在 opt 文件夹下提供了额外的可选依赖项,可以通过移动这些 JAR 文件到 lib 目录来启用这些依赖项;
9.如果只使用 Flink 的 Java API,可以使用任何 Scala 版本;如果使用 Flink 的 Scala API,则需要选择与应用程序的 Scala 匹配的 Scala 版本;
10.2.12.8 之后的 Scala 版本与之前的 2.12.x 版本二进制不兼容,使 Flink 项目无法将 2.12.x 版本直接升级到 2.12.8 以上;为此,需要在构建时添加 -Djapicmp.skip 以跳过二进制兼容性检查;
11.Flink 发行版默认包含执行 Flink SQL 任务的必要 JAR 文件(位于 lib 目录),但默认情况下不包含 Table Scala API,需手动添加;
12.要将 Flink 与 Hadoop 一起使用,需要有一个包含 Hadoop 依赖项的 Flink 系统,而不是添加 Hadoop 作为应用程序依赖项,通过
[export HADOOP_CLASSPATH=`hadoop classpath`] Flink 将使用 HADOOP_CLASSPATH 环境变量指定的 Hadoop 依赖项;
13.如果在 IDE 开发或测试期间需要 Hadoop 依赖项(用于 HDFS 访问),应该限定这些依赖项的使用范围(如 test 或 provided)。
14.StreamExecutionEnvironment 包含了 ExecutionConfig,它允许在运行时设置作业特定的配置;
15.通过 getRuntimeContext() 方法在 Rich* function 中可以访问到 ExecutionConfig;
16.打包后程序运行时,JAR 文件 manifest 中的 program-class 属性会优先于 main-class 属性;对于 JAR manifest 中两个属性都不存在的情况,命令行和 web 界面支持手动传入类名参数;
17.使用 savepoints 时,应该考虑设置最大并行度,此设置会限定整个程序的并行度上限,当作业从一个 savepoint 恢复时,可以改变特定算子或者整个程序的并行度;
18.默认的最大并行度等于 operatorParallelism + (operatorParallelism / 2) 值四舍五入到大于等于该值的一个整型值,并且这个整型值是 2 的幂次方,默认最大并行度下限为 128,上限为 32768;
19.为最大并行度设置一个非常大的值将会降低性能,因为一些 state backends 需要维持内部的数据结构,而这些数据结构将会随着 key-groups 的数目而扩张(key-group 是状态重新分配的最小单元);
20.从之前的作业恢复时,改变该作业的最大并行度将会导致状态不兼容;
21.设置 Job 的并行度,可以从算子层面(operator)、执行环境层面(env)、客户端层面(-P)、系统层面(flink-conf.yaml);
22、当 Lambda 表达式使用 Java 泛型时,需要显式地声明类型信息;使用显式的 ".returns(...)" 、使用类来替代、使用匿名类来替代,使用 Tuple 的子类如 DoubleTuple 来替代;
23、建议始终以 parallelism > 1 的方式在本地测试 pipeline,以识别只有在并行执行 pipeline 时才会出现的 bug。
24、可以通过 Parametertool、Commons CLI、argparse4j 来获取外部配置参数;
25、可以通过 ParameterTool 读取来自 .properties 文件、命令行、系统属性的配置参数;
26、可以在 ExecutionConfig 中注册全局作业参数,在 rich 函数中通过 getRuntimeContext().getGlobalJobParameters() 获取全局作业参数。
27、可以在 process 方法中,通过 Context 将数据发送到由 OutputTag 标识的旁路输出中,用来拆分数据;
28、可以在 DataStream 运算结果上使用 getSideOutput(OutputTag) 方法获取旁路输出流。
29、转换算子
Map[DataStream → DataStream]:输入一个元素,转换后输出一个元素;
FlatMap[DataStream → DataStream]:输入一个元素,转换后产生零个、一个或多个元素;
Filter[DataStream → DataStream]:为每个元素执行一个boolean function,并保留那些 function 输出值为 true 的元素;
KeyBy[DataStream → KeyedStream]:在逻辑上将流划分为不相交的分区,具有相同 key 的记录都分配到同一个分区;在内部 keyBy() 是通过哈希分区实现的;当类为 POJO 类,却没有重写 hashCode() 方法而是依赖于 Object.hashCode() 实现或它是任意类的数组时不能作为 key;
Reduce[KeyedStream → DataStream]:在相同 key 的数据流上“滚动”执行 reduce,将当前元素与最后一次 reduce 得到的值组合然后输出新值;
Window[KeyedStream → WindowedStream]:在已经分区的 KeyedStreams 上定义 Window,Window 根据某些特征对每个 key Stream 中的数据进行分组;
WindowAll[DataStream → AllWindowedStream]:在 DataStream 上定义 Window,Window 根据某些特征对所有流事件进行分组,注意所有记录都将收集到 windowAll 算子对应的一个任务中[并行度为1];
WindowReduce[WindowedStream → DataStream]:对窗口应用 reduce function 并返回 reduce 后的值;
Union[DataStream* → DataStream]:将两个或多个数据流联合来创建一个包含所有流中数据的新流,如果一个数据流和自身进行联合,这个流中的每个数据将在合并后的流中出现两次;
Window Join[DataStream,DataStream → DataStream]:根据指定的 key 和窗口 join 两个数据流;
Interval Join[KeyedStream,KeyedStream → DataStream]:根据 key 相等并且在指定的时间范围内(e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound)的条件将分别属于两个 keyed stream 的元素 e1 和 e2 Join 在一起;
Window CoGroup[DataStream,DataStream → DataStream]:根据指定的 key 和窗口将两个数据流组合在一起;
Connect[DataStream,DataStream → ConnectedStream]:“连接” 两个数据流并保留各自的类型,connect 允许在两个流的处理逻辑之间共享状态;
CoMap, CoFlatMap[ConnectedStream → DataStream]:在连接的数据流上进行 map 和 flatMap;
Cache[DataStream → CachedDataStream]:把算子的结果缓存起来,目前只支持批模式下运行的作业;算子的结果在算子第一次执行的时候会被缓存起来,之后的作业中会复用该算子缓存的结果;如果算子的结果丢失了,它会被原来的算子重新计算并缓存;
30、物理分区算子
Global Partitioner[DataStream → DataStream]:将数据输出到下游的0号分区中;
Custom Partitioner[DataStream → DataStream]:使用自定义的 Partitioner 为每个元素选择目标分区;
Shuffle Partitioner[DataStream → DataStream]:将元素随机均匀的输出到下游的分区中;
Rebalance Partitioner[DataStream → DataStream]:将元素以循环的方式输出到下游的分区中;
Rescale Partitioner[DataStream → DataStream]:基于上下游算子的并行度,将元素以循环的方式输出到下游的分区中;
Broadcast Partitioner[DataStream → DataStream]:将所有元素广播到下游的每个分区中;
31、算子链和资源组
将两个算子链接在一起,可以使它们在同一个线程中执行,从而提升性能;Flink 默认会将能链接的算子尽可能的进行链接;
可以调用 StreamExecutionEnvironment.disableOperatorChaining() 方法对整个作业禁用算子链;
可以调用 startNewChain() 方法基于当前算子创建一个新的算子链[只能在 DataStream 转换操作后调用,因为只对前一次的数据转换生效];
可以调用 disableChaining() 方法禁止和当前算子链接在一起[只能在 DataStream 转换操作后调用,因为只对前一次的数据转换生效];
可以调用 slotSharingGroup() 方法为当前算子配置 slot 共享组,Flink 会将同一个 slot 共享组的算子放在同一个 slot 中,而将不在同一个 slot 共享组的算子保留在其它 slot 中,可用于隔离 slot;slot 共享组的默认名称是“default”,可以调用 slotSharingGroup(“default”) 来显式地将算子放入该组;
32、Task 和 Slot 数量的计算
当算子 A 被设置在单独的 SharingGroup 中时,算子 A 有几个并行度就需要几个 slot;
当多个算子能被算子链连在一起时,算子有几个并行度就需要几个 slot;
当算子 A 不能被算子链 B 连在一起,且算子 A 被设置在与算子链 B 相同的 SharingGroup 中时,算子 A 的并行度大于算子链 B 的并行度部分会占用额外的 slot 数;
能被算子链连在一起的算子,可以在同一个线程中执行,只创建一个 Task;
不能被算子链连在一起的算子,每个并行度需要单独创建一个 Task 执行;
33、算子链连接的条件
上下游的并行度一致;
下游节点的入度为1(即下游节点没有来自其它节点的输入);
上下游节点都在同一个 slotSharingGroup 中;
下游节点的 chain 策略为 ALWAYS;
上游节点的 chain 策略为 ALWAYS 或 HEAD;
两个节点间数据分区方式是 Forward Partition;
用户没有禁用算子链;
34、名字和描述
name 主要用在用户界面、线程名、日志、指标等场景,名字需要尽可能简洁,避免对外部系统产生大的压力;description 主要用在执行计划展示及用户界面展示等场景;
建议为算子设置 name\description\uid\parallelism\maxParallelism 参数;
35.Flink 窗口在 keyed streams 要调用 keyBy(...) 后再调用 window(...),而 non-keyed streams 直接调用 windowAll(...);
36.Keyed Windows 使用示例
stream
.keyBy(...) <- 仅 keyed 窗口需要
.window(...) <- 必填项:"assigner"
[.trigger(...)] <- 可选项:"trigger" (省略则使用默认 trigger)
[.evictor(...)] <- 可选项:"evictor" (省略则不使用 evictor)
[.allowedLateness(...)] <- 可选项:"lateness" (省略则为 0)
[.sideOutputLateData(...)] <- 可选项:"output tag" (省略则不对迟到数据使用 side output)
.reduce/aggregate/apply() <- 必填项:"function"
[.getSideOutput(...)] <- 可选项:"output tag"
37.Non-Keyed Windows 使用示例
stream
.windowAll(...) <- 必填项:"assigner"
[.trigger(...)] <- 可选项:"trigger" (else default trigger)
[.evictor(...)] <- 可选项:"evictor" (else no evictor)
[.allowedLateness(...)] <- 可选项:"lateness" (else zero)
[.sideOutputLateData(...)] <- 可选项:"output tag" (else no side output for late data)
.reduce/aggregate/apply() <- 必填项:"function"
[.getSideOutput(...)] <- 可选项:"output tag"
38.一个窗口在第一个属于它的元素到达时就会被创建,然后在时间(event 或 processing time)超过窗口的“结束时间戳 + 用户定义的 allowed lateness“时被完全删除;
39.Flink 仅保证删除基于时间的窗口,其他类型的窗口不做保证, 比如全局窗口;
40.每个窗口会设置自己的 Trigger 和 function (ProcessWindowFunction、ReduceFunction、或 AggregateFunction),该 function 决定如何计算窗口中的内容,而 Trigger 决定窗口中的数据何时可以被 function 计算;
41.Trigger 还可以在 window 被创建后、删除前的这段时间内定义何时清理(purge)窗口中的数据;此处数据仅指窗口内的元素,不包括窗口的 meta data,即窗口在 purge 后仍然可以加入新的数据。
42.可以指定一个 Evictor,在 trigger 触发之后,Evictor 可以在窗口函数的前后删除数据;
43.在定义窗口前需确定 stream 是 keyed 还是 non-keyed,keyBy(...) 会将无界 stream 分割为逻辑上的 keyed stream;
对于 keyed stream,数据的任何属性都可以作为 key,使用 keyed stream 允许窗口计算由多个 task 并行,因为每个逻辑上的 keyed stream 都可以被单独处理,属于同一个 key 的元素会被发送到同一个 task;
对于 non-keyed stream,原始的 stream 不会被分割为多个逻辑上的 stream, 所有的窗口计算会被同一个 task 完成,也就是 parallelism 为 1;
44. WindowAssigner 负责将 stream 中的每个数据分发到一个或多个窗口中,Flink 提供了默认的 window assigner,即 tumbling windows、sliding windows、session windows 和 global windows;也可以继承 WindowAssigner 类来实现自定义的 window assigner;
45.基于时间的窗口用 start timestamp(包含)和 end timestamp(不包含)描述窗口的大小;Flink 处理基于时间的窗口使用的是 TimeWindow, 它有查询开始和结束的 timestamp 以及返回窗口所能储存的最大 timestamp 的方法 maxTimestamp();
46.滚动窗口(Tumbling Windows),滚动窗口的 assigner 分发元素到指定大小的窗口,滚动窗口的大小是固定的,且各自范围之间不重叠;
47.滑动窗口(Sliding Windows),滑动窗口的 assigner 分发元素到指定大小的窗口,窗口大小通过 window size 参数设置,滑动窗口需要一个额外的滑动距离(window slide)参数来控制生成新窗口的频率;如果 slide 小于窗口大小,滑动窗口可以允许窗口重叠,此时一个元素可能会被分发到多个窗口;
48.滚动窗口和滑动窗口的 assigners 可以设置 offset 参数,这个参数可以用来对齐窗口,不设置 offset 时,窗口的起止时间会与 linux 的 epoch 对齐,一个重要的 offset 用例是根据 UTC-0 调整窗口的时差,在中国可能会设置 offset 为 Time.hours(-8);
49.会话窗口(Session Windows),会话窗口的 assigner 会把数据按活跃的会话分组,会话窗口不会相互重叠,且没有固定的开始或结束时间,会话窗口在一段时间没有收到数据之后会关闭,会话窗口的 assigner 可以设置固定的会话间隔(session gap)或用 session gap extractor 函数来动态地定义多长时间算作不活跃;当超出了不活跃的时间段,当前的会话就会关闭,接下来的数据将被分发到新的会话窗口;
50.会话窗口并没有固定的开始或结束时间,在 Flink 内部,会话窗口的算子会为每一条数据创建一个窗口,然后将距离不超过预设间隔的窗口合并,想要让窗口可以被合并,会话窗口需要拥有支持合并的 Trigger 和 Window Function, 例如 ReduceFunction、AggregateFunction 或 ProcessWindowFunction;
51.全局窗口(Global Windows),全局窗口的 assigner 将拥有相同 key 的所有数据分发到一个全局窗口,此窗口模式仅在指定了自定义的 trigger 时有用,否则计算不会发生,因为全局窗口没有天然的终点去触发其中积累的数据;
52.窗口函数(Window Functions)有三种:ReduceFunction、AggregateFunction 或 ProcessWindowFunction;
- ReduceFunction、AggregateFunction 执行更高效,因为 Flink 可以在每条数据到达窗口后进行增量聚合;
- 而 ProcessWindowFunction 会得到能够遍历当前窗口内所有数据的 Iterable,以及关于这个窗口的 meta-information;
53.ProcessWindowFunction 可以与 ReduceFunction 或 AggregateFunction 合并来提高效率,既可以增量聚合窗口内的数据,又可以从 ProcessWindowFunction 接收窗口的 metadata;
54.ReduceFunction:指定两条输入数据如何合并起来产生一条输出数据,输入和输出数据的类型必须相同;
55.AggregateFunction:接收三个参数,输入数据的类型(IN)、累加器的类型(ACC)和输出数据的类型(OUT);
56.AggregateFunction 接口有如下方法:
把每一条元素加进累加器:add
创建初始累加器:createAccumulator
合并两个累加器:merge
从累加器中提取输出数据:getResult
57.ProcessWindowFunction:具备 Iterable 能获取窗口内所有的元素,以及用来获取时间和状态信息的 Context 对象,但因为窗口中的数据无法被增量聚合,而需要在窗口触发前缓存所有数据;
58.增量聚合的 ProcessWindowFunction:ProcessWindowFunction 可以与 ReduceFunction 或 AggregateFunction 搭配使用,使其能够在数据到达窗口的时候进行增量聚合,当窗口关闭时,ProcessWindowFunction 将会得到聚合的结果;即实现了增量聚合窗口的元素并且也从 ProcessWindowFunction 中获得了窗口的元数据;
59.除了访问 keyed state,ProcessWindowFunction 还可以使用作用域仅为“当前正在处理的窗口”的 keyed state;
60.process() 接收到的 Context 对象中有两个方法允许访问以下两种 state:
- globalState(),访问全局的 keyed state
- windowState(),访问作用域仅限于当前窗口的 keyed state
61.如果可能将一个 window 触发多次(比如迟到数据会再次触发窗口计算,或自定义了根据推测提前触发窗口的 trigger),这时可能需要在 per-window state 中储存关于之前触发的信息或触发的总次数;
62.当使用窗口状态时,一定记得在删除窗口时清除这些状态,应该定义在 clear() 方法中;
63.Trigger 决定了一个窗口(由 window assigner 定义)何时可以被 window function 处理;每个 WindowAssigner 都有一个默认的 Trigger,如果默认 trigger 无法满足需要,可以在 trigger(...) 调用自定义的 trigger;
64.Trigger 接口提供了五个方法来响应不同的事件:
- onElement() 方法在每个元素被加入窗口时调用。
- onEventTime() 方法在注册的 event-time timer 触发时调用。
- onProcessingTime() 方法在注册的 processing-time timer 触发时调用。
- onMerge() 方法与有状态的 trigger 相关。该方法会在两个窗口合并时,将窗口对应 trigger 的状态合并,比如使用会话窗口时。
- clear() 方法处理在对应窗口被移除时所需的逻辑。
前三个方法通过返回 TriggerResult 来决定 trigger 如何应对到达窗口的事件,应对方案有以下几种:
- CONTINUE: 什么也不做
- FIRE: 触发计算
- PURGE: 清空窗口内的元素
- FIRE_AND_PURGE: 触发计算,计算结束后清空窗口内的元素
65.当 trigger 触发时,它可以返回 FIRE 或 FIRE_AND_PURGE;FIRE 会保留被触发的窗口中的内容,而 FIRE_AND_PURGE 会删除这些内容,Flink 内置的 trigger 默认使用 FIRE,不会清除窗口的内容;Purge 只会移除窗口的内容,不会移除关于窗口的 meta-information 和 trigger 的状态;
66.Flink 包含一些内置 trigger:
- ContinuousProcessingTimeTrigger:根据间隔时间周期性触发窗口或者当 Window 的结束时间小于当前 ProcessTime 触发窗口计算
- ProcessingTimeoutTrigger:当内置触发器满足超时时间时,触发窗口的计算
- ProcessingTimeTrigger:ProcessingTimeWindows 默认使用,会在处理时间越过窗口结束时间后直接触发
- ContinuousEventTimeTrigger:根据间隔时间周期性触发窗口或者当 Window 的结束时间小于当前的 watermark 时触发窗口计算
- EventTimeTrigger:EventTimeWindows 默认使用,会在 watermark 越过窗口结束时间后直接触发
- PurgingTrigger:接收另一个 trigger 并将它转换成一个会清理数据的 trigger
- NeverTrigger:GlobalWindows 默认使用,任何时候都不触发窗口计算
- DeltaTrigger:根据接入数据计算出来的 Delta 指标是否超过指定的 Threshold 去判断是否触发窗口计算
- CountTrigger:在窗口中的元素超过预设的限制时触发
67.Flink 的窗口模型允许在 WindowAssigner 和 Trigger 之外指定可选的 Evictor,通过 evictor(...) 方法传入 Evictor,Evictor 可以在 trigger 触发后、调用窗口函数之前或之后从窗口中删除元素;
68.evictBefore() 包含在调用窗口函数前的逻辑,而 evictAfter() 包含在窗口函数调用之后的逻辑,在调用窗口函数之前被移除的元素不会被窗口函数计算;
69.Flink 有三个内置的 evictor:
- CountEvictor: 仅记录用户指定数量的元素,一旦窗口中的元素超过这个数量,多余的元素会从窗口缓存的开头移除;
- DeltaEvictor: 接收 DeltaFunction 和 threshold 参数,计算最后一个元素与窗口缓存中所有元素的差值,并移除差值大于或等于 threshold 的元素;
- TimeEvictor: 接收 interval 参数,以毫秒表示,它会找到窗口中元素的最大 timestamp 即 max_ts 并移除比 max_ts - interval 小的所有元素;
默认情况下,所有内置的 evictor 逻辑都在调用窗口函数前执行;Flink 不对窗口中元素的顺序做任何保证,即使 evictor 从窗口缓存的开头移除一个元素,这个元素也不一定是最先或者最后到达窗口的;
70.使用 ProcessTime 和 GlobalWindows 时无迟到数据,但使用 event-time 窗口时,数据可能会迟到,默认 watermark 一旦越过窗口结束的 timestamp,迟到的数据就会被直接丢弃;
71.Allowed lateness 默认是 0,在 watermark 超过窗口末端、到达窗口末端加上 allowed lateness 之前的这段时间内到达的元素,依旧会被加入窗口;Flink 会将窗口状态保存到 allowed lateness 超时才会将窗口及其状态删除;但窗口再次触发的结果取决于触发器是否 purge 而导致结果不同;
72.通过 Flink 的侧流输出功能,可以获得迟到数据的数据流;
73.当指定了大于 0 的 allowed lateness 时,窗口本身以及其中的内容仍会在 watermark 越过窗口末端后保留;此时如果一个迟到但未被丢弃的数据到达,它可能会再次触发这个窗口,这种触发被称作 late firing;如果是使用会话窗口的情况,late firing 可能会进一步合并已有的窗口,因为他们可能会连接现有的、未被合并的窗口;late firing 发出的元素应该被视作对之前计算结果的更新,即数据流中会包含一个相同计算任务的多个结果,应用需要考虑到这些重复的结果,或去除重复的部分;
74.窗口操作的结果会变回 DataStream,并且窗口操作的信息不会保存在输出的元素中,如果想要保留窗口的 meta-information,需要在 ProcessWindowFunction 里手动将他们放入输出的元素中;
75.当 watermark 到达窗口算子时,它触发了两件事:
- 这个 watermark 触发了所有最大 timestamp(即 end-timestamp - 1)小于它的窗口;
- 这个 watermark 被原封不动地转发给下游的任务;
76.窗口可以被定义在很长的时间段上(比如几天、几周或几个月)并且积累下很大的状态,当估算窗口计算的储存需求时,注意如下:
- Flink 会为一个元素在它所属的每一个窗口中都创建一个副本;在滚动窗口的设置中一个元素只会存在一个副本,在滑动窗口的设置中一个元素可能会被拷贝到多个滑动窗口中,每个(滑动窗口长度/滑动距离)会存在一个数据副本;
- ReduceFunction 和 AggregateFunction 可以极大地减少储存需求,它们会就地聚合到达的元素,且每个窗口仅储存一个值,而使用 ProcessWindowFunction 需要累积窗口中所有的元素;
- 使用 Evictor 可以避免预聚合,因为窗口中的所有数据必须先经过 evictor 才能进行计算;
77.Window join 作用在两个流中有相同 key 且处于相同窗口的元素上,两个流中的元素在组合之后,会被传递给用户定义的 JoinFunction 或 FlatJoinFunction,可以用它们输出符合 join 要求的结果;
stream.join(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
78.一个流中的元素在与另一个流中对应的元素完成 join 之前不会被输出;完成 join 的元素会将他们的 timestamp 设为对应窗口中允许的最大 timestamp;
79.滚动 Window Join:所有 key 相同且共享一个滚动窗口的元素会被组合成对,并传递给 JoinFunction 或 FlatJoinFunction,行为与 inner join 类似,所以一个流中的元素如果没有与另一个流中的元素组合起来,它就不会被输出;
80.滑动 Window Join:所有 key 相同且处于同一个滑动窗口的元素将被组合成对,并传递给 JoinFunction 或 FlatJoinFunction,当前滑动窗口内,如果一个流中的元素没有与另一个流中的元素组合起来,它就不会被输出;
81.在某个滑动窗口中被 join 的元素不一定会在其他滑动窗口中被 join;
82.会话 Window Join:所有 key 相同且组合后符合会话要求的元素将被组合成对,并传递给 JoinFunction 或 FlatJoinFunction,这个操作同样是 inner join,如果一个会话窗口中只含有某一个流的元素,这个窗口将不会产生输出;
83.Interval join:组合元素的条件为两个流(A 和 B)中 key 相同且 B 中元素的 timestamp 处于 A 中元素 timestamp 的一定范围内,即 b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound] 或 a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound;
上述的 a 和 b 为 A 和 B 中共享相同 key 的元素,上界和下界可正可负,只要下界永远小于等于上界即可,Interval join 目前仅执行 inner join;
84.当一对元素被传递给 ProcessJoinFunction,他们的 timestamp 会从两个元素的 timestamp 中取最大值 (timestamp 可以通过 ProcessJoinFunction.Context 访问);
85.Interval join 目前仅支持 event time;默认情况下,上下界也被包括在区间内,但 .lowerBoundExclusive() 和 .upperBoundExclusive() 可以将它们排除在外;
86.Window Join 和 Interval Join 只适合 Inner Join,可以通过 coGroup/connect 实现 Left/Right/Inner Join;
87.ProcessFunction 是底层的数据流处理操作,可访问所有(非循环)流应用程序的基本模块;
- 事件 (数据流中的元素)
- 状态(容错、一致、仅在 keyed stream 上)
- 定时器(事件时间和处理时间,仅在 keyed stream 上)
88.ProcessFunction 允许访问 keyed State,可通过 RuntimeContext 访问;
89.定时器支持处理时间和事件时间,对函数 processElement(…)的每次调用都会获得一个 Context 对象,该对象可以访问元素的事件时间戳和 TimerService;TimerService 可用于注册处理时间和事件时间定时器;对于事件时间定时器,当 watermark 到达或超过定时器的时间戳时,会调用 onTimer(...),在该调用过程中,所有状态的作用域再次限定为创建定时器时使用的 key,从而允许定时器操作 keyed State;
90.对于两个输入的底层 Join 可以使用 CoProcessFunction 或 KeyedCoProcessFunction,通过调用 processElement1(…)和processElement2(…)分别处理两个输入;
91.底层 Join 流程如下:
为一个输入或两个输入创建状态对象;
从输入中接收元素时更新状态;
从另一个输入接收元素后,查询状态并产生 Join 结果;
92.TimerService 按 key 和时间戳消除重复的定时器,即每个 key 和时间戳最多有一个定时器,如果为同一时间戳注册了多个计时器,那么 onTimer() 方法将只被调用一次;
93.Flink 会同步 onTimer() 和 processElement() 的调用,无需担心同时修改状态;
94.定时器是容错的,并与应用程序的状态一起进行 Checkpoint,如果发生故障恢复或从保存点启动应用程序,则会恢复定时器;
95.当应用程序从故障中恢复或从保存点启动时,本应在恢复前启动的检查点中的处理时间定时器将立即启动;
96.除了 RocksDB 后端/与增量快照/与基于堆的定时器的组合,定时器使用异步检查点;但是大量的定时器会增加检查点时间,因为定时器是检查点状态的一部分;
97.由于 Flink 为每个 key 和时间戳只维护一个定时器,可以通过降低定时器的精度来合并定时器以减少定时器的数量;
对于1秒(事件或处理时间)的定时器精度,可以将目标时间四舍五入到整秒,定时器最多会提前1秒触发,但不会晚于要求的毫秒精度,每个键和秒最多有一个计时器;
long coalescedTime = ((ctx.timerService().currentProcessingTime() + timeout) / 1000) * 1000;
ctx.timerService().registerProcessingTimeTimer(coalescedTime);
由于事件时间定时器只在 watermark 到达时触发,可以使用当前 watermark 来注册定时器,并将其与下一个 watermark 合并;
long coalescedTime = ctx.timerService().currentWatermark() + 1;
ctx.timerService().registerEventTimeTimer(coalescedTime);
98.停止处理时间定时器-ctx.timerService().deleteProcessingTimeTimer();停止事件时间定时器-ctx.timerService().deleteEventTimeTimer();如果没有注册具有给定时间戳的定时器,则停止定时器无效;
99.在与外部系统交互(用数据库中的数据扩充流数据)时,需要考虑与外部系统的通信延迟对整个流处理应用的影响:
同步交互:使用 MapFunction 访问外部数据库的数据,MapFunction 向数据库发送一个请求然后一直等待,直到收到响应;大多数情况下,等待占据了函数运行的大部分时间;
异步交互:一个并行函数实例可以并发地处理多个请求和接收多个响应,使函数在等待的时间可以发送其他请求和接收其他响应,使等待的时间可以被多个请求分摊;大多数情况下,异步交互可以大幅度提高流处理的吞吐量;
100.提高 MapFunction 的并行度(parallelism)在有些情况下也可以提升吞吐量,但是这样做通常会导致非常高的资源消耗:更多的并行 MapFunction 实例意味着更多的 Task、更多的线程、更多的 Flink 内部网络连接、更多的与数据库的网络连接、更多的缓冲和更多程序内部协调的开销;
101.异步 I/O 算子使用前提:
需要支持异步请求的数据库客户端;
如果没有支持异步请求的客户端,可以通过创建多个客户端并使用线程池处理同步调用的方法,将同步客户端转换为有限并发的客户端,比正规的异步客户端效率低;
102.Flink 的异步 I/O API 允许用户在流处理中使用异步请求客户端,API 处理与数据流的集成,同时还能处理好顺序、事件时间和容错等;
103.在具备异步数据库客户端的基础上,实现数据流转换操作与数据库的异步 I/O 交互需要以下三部分:
- 实现分发请求的 AsyncFunction;
- 获取数据库交互的结果并发送给 ResultFuture 的回调函数;
- 将异步 I/O 操作应用于 DataStream,作为 DataStream 的一次转换操作,启用或者不启用重试;
104.第一次调用 ResultFuture.complete 后 ResultFuture 就完成了,后续的 complete 调用都将被忽略;
105.Timeout:超时参数定义了异步操作执行多久未完成、最终认定为失败的时长,如果启用重试,则可能包括多个重试请求,可以防止一直等待得不到响应的请求;
106.Capacity: 容量参数定义了可以同时进行的异步请求数;即使异步 I/O 通常带来更高的吞吐量,执行异步 I/O 操作的算子仍然可能成为流处理的瓶颈,限制并发请求的数量可以确保算子不会持续累积待处理的请求进而造成积压,而是在容量耗尽时触发反压;
107.AsyncRetryStrategy: 重试策略参数定义了什么条件会触发延迟重试以及延迟的策略,如固定延迟、指数后退延迟、自定义实现等;
108.超时处理:
当异步 I/O 请求超时的时候,默认会抛出异常并重启作业;
如果想处理超时,可以重写 AsyncFunction#timeout 方法;重写 AsyncFunction#timeout 时需要调用 ResultFuture.complete() 或者 ResultFuture.completeExceptionally() 以通知 Flink 这条记录的处理已经完成;如果超时发生时不想发出任何记录,可以调用 ResultFuture.complete(Collections.emptyList());
109.AsyncFunction 发出的并发请求经常以不确定的顺序完成,这取决于请求得到响应的顺序;Flink 提供两种模式控制结果记录以何种顺序发出。
- 无序模式: 异步请求一结束就立刻发出结果记录。流中记录的顺序在经过异步 I/O 算子之后发生了改变。当使用处理时间作为基本时间特征时,这个模式具有最低的延迟和最少的开销。此模式使用 AsyncDataStream.unorderedWait(...) 方法。
- 有序模式: 保持了流的顺序。发出结果记录的顺序与触发异步请求的顺序(记录输入算子的顺序)相同;算子将缓冲一个结果记录直到这条记录前面的所有记录都发出(或超时),因为记录或者结果要在 checkpoint 的状态中保存更长的时间,所以与无序模式相比,有序模式通常会带来额外的延迟和 checkpoint 开销。此模式使用 AsyncDataStream.orderedWait(...) 方法。
110.当流处理应用使用事件时间时,异步 I/O 算子会正确处理 watermark。
- 无序模式:Watermark 既不超前于记录也不落后于记录,即 watermark 建立了顺序的边界。只有连续两个 watermark 之间的记录是无序发出的。在一个 watermark 后面生成的记录只会在这个 watermark 发出以后才发出。在一个 watermark 之前的所有输入的结果记录全部发出以后,才会发出这个 watermark。在 watermark 的情况下,无序模式会引入一些与有序模式相同的延迟和管理开销。开销大小取决于 watermark 的频率;
- 有序模式:连续两个 watermark 之间的记录顺序也被保留了。开销与使用处理时间相比,没有显著的差别。
111.异步 I/O 算子提供了完全的精确一次容错保证,它将异步请求的记录保存在 checkpoint 中,在故障恢复时重新触发请求;
112.重试支持为异步 I/O 操作引入了一个内置的重试机制,它对用户的异步函数实现逻辑是透明的。
- AsyncRetryStrategy: 异步重试策略包含了触发重试条件 AsyncRetryPredicate 定义,以及根据当前已尝试次数判断是否继续重试、下次重试间隔时长的接口方法。在满足触发重试条件后,有可能因为当前重试次数超过预设的上限放弃重试,或是在任务结束时被强制终止重试(此时系统以最后一次执行的结果或异常作为最终状态)。
- AsyncRetryPredicate: 触发重试条件可以选择基于返回结果、执行异常来定义条件,两种条件是或的关系,满足其一即会触发。
113.在实现使用 Executor 和回调的 Futures 时,建议使用 DirectExecutor,因为通常回调的工作量很小,DirectExecutor 避免了额外的线程切换开销;回调通常只是把结果发送给 ResultFuture,也就是把它添加进输出缓冲;从这里开始,包括发送记录和与 chenkpoint 交互在内的繁重逻辑都将在专有的线程池中进行处理。
114.DirectExecutor 可以通过 org.apache.flink.util.concurrent.Executors.directExecutor() 或 com.google.common.util.concurrent.MoreExecutors.directExecutor() 获得;
115.默认情况下,AsyncFunction 的算子(异步等待算子)可以在作业图的任意处使用,但它不能与 SourceFunction/SourceStreamTask 组成算子链;
116.以下情况将阻塞 asyncInvoke(...) 函数,从而使异步行为无效:
- 使用同步数据库客户端,它的查询方法调用在返回结果前一直被阻塞;
- 在 asyncInvoke(...) 方法内阻塞等待异步客户端返回的 future 类型对象;
117.启用重试后可能需要更大的缓冲队列容量:
新的重试功能可能会导致更大的队列容量要求,最大数量可以近似地评估如下:
inputRate * retryRate * avgRetryDuration
例如,对于一个输入率=100条记录/秒的任务,其中1%的元素将平均触发1次重试,平均重试时间为60秒,额外的队列容量要求为:
100条记录/秒 * 1% * 60s = 60
即在无序输出模式下,给工作队列增加 60 个容量可能不会影响吞吐量;而在有序模式下,头部元素是关键点,它未完成的时间越长,算子提供的处理延迟就越长;在相同的超时约束下,如果头元素事实上获得了更多的重试,那重试功能可能会增加头部元素的处理时间即未完成时间,也就是说在有序模式下,增大队列容量并不是总能提升吞吐。
118.当队列容量增长时(可以缓解背压),OOM 的风险会随之增加;对于 ListState 存储来说,理论的上限是 Integer.MAX_VALUE,虽然队列容量的限制是一样的,但在生产中不能把队列容量增加到太大,此时增加任务的并行性也许更可行;
119.使用 keyed state,首先需要为 DataStream 指定 key(主键);这个 key 用于状态分区(数据流中的 Record 也会被分区);可以使用 DataStream 中 Java API 的 keyBy(KeySelector) 来指定 key,将生成 KeyedStream;
120.Key selector 函数接收单条 Record 作为输入,返回这条记录的 key,该 key 可以为任何类型,但是它的计算产生方式必须具备确定性,Flink 的数据模型不基于 key-value 对,将数据集在物理上封装成 key 和 value 是没有必要的,Key 是“虚拟”的,用以操纵分组算子;
121.可以通过 tuple 字段索引,或者选取对象字段的表达式来指定 key 即 Tuple Keys 和 Expression Keys;
122.keyed state 接口提供不同类型状态的访问接口,这些状态都作用于当前输入数据的 key 下,即这些状态仅可在 KeyedStream 上使用,支持的状态类型如下:
- ValueState: 保存一个可以更新和检索的值(每个值都对应到当前的输入数据的 key,因此算子接收到的每个 key 都可能对应一个值)这个值可以通过 update(T) 进行更新,通过 T value() 进行检索;
- ListState: 保存一个元素的列表,可以往这个列表中追加数据,并在当前的列表上进行检索,通过 add(T) 或者 addAll(List) 添加元素,通过 Iterable get() 获得整个列表,还可以通过 update(List) 覆盖当前的列表;
- ReducingState: 保存一个单值,表示添加到状态的所有值的聚合,使用 add(T) 增加的元素会用提供的 ReduceFunction 进行聚合;
- AggregatingState: 保留一个单值,表示添加到状态的所有值的聚合,和 ReducingState 相反的是,聚合类型可能与添加到状态的元素的类型不同,使用 add(IN) 添加的元素会用指定的 AggregateFunction 进行聚合;
- MapState: 维护了一个映射列表,可以添加键值对到状态中,也可以获得反映当前所有映射的迭代器,使用 put(UK,UV) 或者 putAll(Map) 添加映射,使用 get(UK) 检索特定 key,使用 entries(),keys() 和 values() 分别检索映射、键和值的可迭代视图,还可以通过 isEmpty() 来判断是否包含任何键值对;
123.所有类型的状态都有一个 clear() 方法,清除当前 key 下的状态数据;
124.状态对象仅用于与状态交互,状态本身不一定存储在内存中,还可能在磁盘或其他位置;从状态中获取的值取决于输入元素所代表的 key,在不同 key 上调用同一个接口,可能得到不同的值;
125.状态通过 RuntimeContext 进行访问,只能在 rich functions 中使用;
126.任何类型的 keyed state 都可以有有效期 (TTL),如果配置了 TTL 且状态值已过期,则会尽最大可能清除对应的值,所有状态类型都支持单元素的 TTL,列表元素和映射元素将独立到期;
127.在使用状态 TTL 前,需要先构建一个 StateTtlConfig 配置对象,然后把配置传递到 state descriptor 中启用 TTL 功能;
128.TTL 的更新策略(默认是 OnCreateAndWrite):
- StateTtlConfig.UpdateType.OnCreateAndWrite - 仅在创建和写入时更新
- StateTtlConfig.UpdateType.OnReadAndWrite - 读取时也更新
129.数据在过期但还未被清理时的可见性配置如下(默认为 NeverReturnExpired):
- StateTtlConfig.StateVisibility.NeverReturnExpired - 不返回过期数据
- StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp - 会返回过期但未清理的数据
NeverReturnExpired 情况下,过期数据就像不存在一样,不管是否被物理删除,这对于不能访问过期数据的场景下非常有用,比如敏感数据, ReturnExpiredIfNotCleanedUp 在数据被物理删除前都会返回;
注意:
- 状态上次的修改时间会和数据一起保存在 state backend 中,开启该特性会增加状态数据的存储;Heap state backend 会额外存储一个包括用户状态以及时间戳的 Java 对象,RocksDB state backend 会在每个状态值(list 或者 map 的每个元素)序列化后增加 8 个字节;
- 暂时只支持基于 processing time 的 TTL;
- 尝试从 checkpoint/savepoint 进行恢复时,TTL 的状态(是否开启)必须和之前保持一致,否则会遇到 “StateMigrationException”;
- TTL 的配置并不会保存在 checkpoint/savepoint 中,仅对当前 Job 有效;
- 不建议 checkpoint 恢复前后将 state TTL 从短调长,这可能会产生潜在的数据错误;
- 当前开启 TTL 的 map state 仅在用户值序列化器支持 null 的情况下,才支持用户值为 null;如果用户值序列化器不支持 null,可以用 NullableSerializer 包装一层;
- 启用 TTL 配置后,StateDescriptor 中的 defaultValue(已标记 deprecated)将会失效,在此基础上,用户需要手动管理那些实际值为 null 或已过期的状态默认值;
130.默认情况下,过期数据会在读取的时候被删除,例如 ValueState#value,会有后台线程定期清理(需要 StateBackend 支持)可以通过 StateTtlConfig 配置关闭后台清理.disableCleanupInBackground();
131.当前的实现中 HeapStateBackend 依赖增量数据清理,RocksDBStateBackend 利用压缩过滤器进行后台清理;
132.可以启用全量快照时进行清理的策略,可以减少整个快照的大小,当前实现中不会清理本地的状态,但从上次快照恢复时,不会恢复那些已经删除的过期数据,该策略可以通过 StateTtlConfig 进行配置.cleanupFullSnapshot(),该策略在 RocksDBStateBackend 的增量 checkpoint 模式下无效;这种清理方式可以在任何时候通过 StateTtlConfig 启用或者关闭,比如在从 savepoint 恢复时;
133.可以选择增量式清理状态数据,在状态访问或/和处理时进行,如果某个状态开启了该清理策略,则会在存储后端保留一个所有状态的惰性全局迭代器,每次触发增量清理时,从迭代器中选择已经过期的数进行清理;
该策略有两个参数:
- 第一个参数表示每次清理时检查状态的条目数,在每个状态访问时触发;
- 第二个参数表示是否在处理每条记录时触发清理,Heap backend 默认会检查 5 条状态,并且关闭在每条记录时触发清理;
注意:
- 如果没有 state 访问,也没有处理数据,则不会清理过期数据;
- 增量清理会增加数据处理的耗时;
- 现在仅 Heap state backend 支持增量清除机制,在 RocksDB state backend 上启用该特性无效;
- 如果 Heap state backend 使用同步快照方式,则会保存一份所有 key 的拷贝,从而防止并发修改问题,因此会增加内存的使用,但异步快照则没有这个问题;
- 对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,比如从 savepoint 重启后;
134.如果使用 RocksDB state backend,则会启用 Flink 为 RocksDB 定制的压缩过滤器,RocksDB 会周期性的对数据进行合并压缩从而减少存储空间,Flink 提供的 RocksDB 压缩过滤器会在压缩时过滤掉已经过期的状态数据;
135.Flink 处理一定条数的状态数据后,会使用当前时间戳来检测 RocksDB 中的状态是否已经过期,可以通过 StateTtlConfig.newBuilder(...).cleanupInRocksdbCompactFilter(long queryTimeAfterNumEntries) 方法指定处理状态的条数;时间戳更新的越频繁,状态的清理越及时,但由于压缩会有调用 JNI 的开销,因此会影响整体的压缩性能;RocksDB backend 的默认后台清理策略会每处理 1000 条数据进行一次;
136.定期压缩可以加速过期状态条目的清理,特别是对于很少访问的状态条目,比这个值早的文件将被选取进行压缩,并重新写入与之前相同的 Level 中,该功能可以确保文件定期通过压缩过滤器压缩,可以通过 StateTtlConfig.newBuilder(...).cleanupInRocksdbCompactFilter(long queryTimeAfterNumEntries, Duration periodicCompactionTime) 方法设定定期压缩的时间,定期压缩的时间的默认值是 30 天,可以将其设置为 0 以关闭定期压缩或设置一个较小的值以加速过期状态条目的清理,但它将会触发更多压缩;
137.可以通过配置开启 RocksDB 过滤器的 debug 日志:log4j.logger.org.rocksdb.FlinkCompactionFilter=DEBUG;
注意:
- 压缩时调用 TTL 过滤器会降低速度,TTL 过滤器需要解析上次访问的时间戳,并对每个将参与压缩的状态进行是否过期检查,对于集合型状态类型(比如 list 和 map),会对集合中每个元素进行检查;
- 对于元素序列化后长度不固定的列表状态,TTL 过滤器需要在每次 JNI 调用过程中,额外调用 Flink 的 java 序列化器, 从而确定下一个未过期数据的位置;
- 对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,比如从 savepoint 重启后;
- 定期压缩功能只在 TTL 启用时生效;
138.算子状态(或者非 keyed 状态)是绑定到一个并行算子实例的状态,Kafka consumer 每个并行实例维护了 topic partitions 和偏移量的 map 作为它的算子状态;
139.当并行度改变的时候,算子状态支持将状态重新分发给各并行算子实例,处理重分发过程有多种不同的方案;
140.算子状态作为一种特殊类型的状态使用,用于实现 source/sink,以及无法对 state 进行分区而没有主键的这类场景中;
141.广播状态是一种特殊的算子状态,支持将一个流中的元素需要广播到所有下游任务的使用情形,广播状态用于保持所有子任务状态相同;
142.广播状态和其他算子状态的区别:
- 它具有 map 格式;
- 它仅在一些特殊的算子中可用,这些算子的输入为一个广播数据流和非广播数据流;
- 这类算子可以拥有不同命名的多个广播状态;
143.用户可以通过实现 CheckpointedFunction 接口来使用 operator state;
144.进行 checkpoint 时会调用 snapshotState(),自定义函数初始化时会调用 initializeState(),初始化包括第一次自定义函数初始化和从之前的 checkpoint 恢复;因此 initializeState() 不仅是定义不同状态类型初始化的地方,也需要包括状态恢复的逻辑;
145.当前 operator state 以 list 的形式存在;这些状态是一个可序列化对象的集合 List,彼此独立,方便在改变并发后进行状态的重新分派,根据状态的不同访问方式,有如下几种重新分配的模式:
- Even-split redistribution: 每个算子都保存一个列表形式的状态集合,整个状态由所有的列表拼接而成;当作业恢复或重新分配的时候,整个状态会按照算子的并发度进行均匀分配;比如说,算子 A 的并发度为 1,包含两个元素 element1 和 element2,当并发度增加为 2 时,element1 会被分到并发 0 上,element2 则会被分到并发 1 上;
- Union redistribution: 每个算子保存一个列表形式的状态集合;整个状态由所有的列表拼接而成;当作业恢复或重新分配时,每个算子都将获得所有的状态数据【不建议使用】;
146.调用不同的获取状态对象的接口,会使用不同的状态分配算法,比如 getUnionListState(descriptor) 会使用 union redistribution 算法,而 getListState(descriptor) 则使用 even-split redistribution 算法;
147.当初始化状态对象后,通过 isRestored() 方法判断是否从之前的故障中恢复,如果该方法返回 true 则表示从故障中进行恢复;
148.要获取 checkpoint 成功消息的算子,可以参考 org.apache.flink.api.common.state.CheckpointListener 接口,当算子完成 checkpoint 后会回调 notifyCheckpointComplete() 方法;
149.为关联一个非广播流(keyed 或者 non-keyed)与一个广播流(BroadcastStream),可以调用非广播流的方法 connect(),并将 BroadcastStream 当做参数传入;这个方法的返回参数是 BroadcastConnectedStream,具有 process() 方法,可以传入一个特殊的 CoProcessFunction 来编辑模式识别逻辑,具体传入 process() 的是哪个类型取决于非广播流的类型:
- 如果流是一个 keyed 流,那就是 KeyedBroadcastProcessFunction 类型;
- 如果流是一个 non-keyed 流,那就是 BroadcastProcessFunction 类型;
150.在传入的 BroadcastProcessFunction 或 KeyedBroadcastProcessFunction 中,需要实现两个方法;processBroadcastElement() 负责处理广播流中的元素,processElement() 负责处理非广播流中的元素;
151.在 getBroadcastState() 方法中传入的 stateDescriptor 应该与调用 .broadcast(ruleStateDescriptor) 的参数相同;
152.对于 broadcast state 的访问权限,在处理广播流元素这端,是具有读写权限的,而对于处理非广播流元素这端是只读的;因为 Flink 中是不存在跨 task 通讯的,为了保证 broadcast state 在所有的并发实例中是一致的,在处理广播流元素的时候给予写权限,在所有的 task 中均可以看到这些元素,并且要求对这些元素处理是一致的,那么最终所有 task 得到的 broadcast state 是一致的;
153.processBroadcastElement() 的实现必须在所有的并发实例中具有确定性的结果;
154.KeyedBroadcastProcessFunction 在 Keyed Stream 上工作,提供了一些 BroadcastProcessFunction 没有的功能:
processElement() 的参数 ReadOnlyContext 提供了方法访问 Flink 的定时器服务,可以注册事件时间定时器(event-time timer)或处理时间定时器(processing-time timer);当定时器触发时,会调用 onTimer() 方法,提供了 OnTimerContext,它具有 ReadOnlyContext 的全部功能,并且提供:
- 查询当前触发的是一个事件时间还是处理时间的定时器
- 查询定时器关联的key
processBroadcastElement() 方法中的参数 Context 会提供方法 applyToKeyedState(StateDescriptor stateDescriptor, KeyedStateFunction function);这个方法使用一个 KeyedStateFunction 能够对 stateDescriptor 对应的 state 中所有 key 的存储状态进行操作;
155.注册定时器只能在 KeyedBroadcastProcessFunction 的 processElement() 方法中进行,在 processBroadcastElement() 方法中不能注册定时器,因为广播的元素中并没有关联的 key;
156.broadcast state 在不同的 task 的事件顺序可能是不同的,虽然广播流中元素的过程能够保证所有的下游 task 全部能够收到,但在不同 task 中元素的到达顺序可能不同,所以 broadcast state 的更新不能依赖于流中元素到达的顺序;
157.虽然所有 task 中的 broadcast state 是一致的,但当 checkpoint 来临时,所有 task 均会对 broadcast state 做 checkpoint;防止在作业恢复后读文件造成的文件热点;Flink 会保证在恢复状态/改变并发的时候数据没有重复且没有缺失;在作业恢复时,如果与之前具有相同或更小的并发度,所有的 task 读取之前已经 checkpoint 过的 state,在增大并发的情况下,task 会读取本身的 state,多出来的并发(p_new - p_old)会使用轮询调度算法读取之前 task 的 state;
158.不使用 RocksDB state backend,broadcast state 在运行时保存在内存中,需保证内存充足,同样适用于其它 Operator State;
159.Flink 中的每个方法或算子都能够是有状态的,状态化的方法在处理单个元素/事件的时候存储数据,为了让状态容错,Flink 需要为状态添加 checkpoint(检查点);
160.默认 checkpoint 是禁用的,通过调用 StreamExecutionEnvironment 的 enableCheckpointing(n) 来启用 checkpoint,里面的 n 是进行 checkpoint 的间隔,单位毫秒;
161.checkpoint 其它属性包括【checkpoint 存储\精确一次(exactly-once)和至少一次(at-least-once)\checkpoint 超时\checkpoints 之间的最小时间\checkpoint 可容忍连续失败次数\并发 checkpoint 的数目\externalized checkpoints\非对齐 checkpoints\部分任务结束的 checkpoints】;
162.Flink 的 checkpointing 机制会将 timer 以及 stateful 的 operator 进行快照,然后存储下来,包括连接器(connectors),窗口(windows)以及用户自定义的状态;
163.Checkpoint 存储在哪里取决于配置的 State Backend(比如 JobManager memory、 file system、 database),默认情况下,状态是保存在 TaskManagers 的内存中,checkpoint 保存在 JobManager 的内存中;为了持久化大体量状态, Flink 支持存储 checkpoint 状态到其他的 state backends 上;
164.Flink 现在为没有迭代(iterations)的作业提供一致性的处理保证,在迭代作业上开启 checkpoint 会导致异常,为了在迭代程序中强制进行 checkpoint,用户需要在开启 checkpoint 时设置一个特殊的标志:env.enableCheckpointing(interval, CheckpointingMode.EXACTLY_ONCE, force = true),注意在环形边上游走的记录(以及与之相关的状态变化)在故障时会丢失;
165.从 1.14 版本开始 Flink 支持在部分任务结束后继续进行 Checkpoint,如果一部分数据源是有限数据集,那么就可以,从 1.15 版本开始,这一特性被默认打开;如果想要关闭这一功能,可以执行 config.set(ExecutionCheckpointingOptions.ENABLE_CHECKPOINTS_AFTER_TASKS_FINISH, false); 此时,结束的任务不会参与 Checkpoint 的过程,在实现自定义的算子或者 UDF(用户自定义函数)时需要考虑这一点;
166.在部分 Task 结束后的 checkpoint 中,Flink 对 UnionListState 进行了特殊的处理,UnionListState 一般用于实现对外部系统读取位置的一个全局视图(例如记录所有 Kafka 分区的读取偏移);
如果在算子的某个并发调用 close() 方法后丢弃它的状态,就会丢失它所分配的分区的偏移量信息,为了解决这一问题,对于使用 UnionListState 的算子,只允许在它的并发都在运行或都已结束的时候才能进行 checkpoint 操作;
167.ListState 一般不会用于类似的场景,仍然需要注意在调用 close() 方法后进行的 checkpoint 会丢弃算子的状态并且这些状态在算子重启后不可用;
任何支持并发修改操作的算子也可以支持部分并发实例结束后的恢复操作,从这种类型的快照中恢复等价于将算子的并发改为正在运行的并发实例数。
168.为了保证使用两阶段提交的算子可以提交所有的数据,任务会在所有算子都调用 finish() 方法后等待下一次 checkpoint 成功后退出;
这一行为可能会延长任务运行的时间,如果 checkpoint 周期比较大,这一延迟会非常明显,极端情况下,如果 checkpoint 的周期被设置为 Long.MAX_VALUE,那么任务永远不会结束,因为下一次 checkpoint 不会进行;
169.Flink 提供了多种 state backends,它用于指定状态的存储方式和位置;
170.为了让应用程序可以维护非常大的状态,Flink 可以自己管理内存(如果有必要可以溢写到磁盘);
171.默认情况下,所有 Flink Job 会使用 Flink 配置文件中指定的 state backend,但配置文件中指定的 state backend 会被 Job 中指定的 state backend 覆盖;
172.Flink 以其独特的方式来处理数据类型及序列化,包括它自身的类型描述符、泛型类型提取以及类型序列化框架,支持的数据类型:
Java Tuples and Scala Case Classes
Java POJOs
Primitive Types
Regular Classes
Values
Hadoop Writables
Special Types
173.Tuples and Case Classes:元组是包含固定数量的具有各种类型的字段的复合类型,Java API 提供从 Tuple1 到 Tuple25 的类,元组的每个字段都可以是任意的 Flink 类型,包括元组,从而产生嵌套的元组;
元组的字段可以使用字段名称 tuple.f4 直接访问,也可以使用通用的 getter 方法 tuple.getField(int位置) 字段索引从0开始;
174.POJOs:如果 Java 和 Scala 类满足以下要求,Flink 会将它们视为特殊的 POJO 数据类型:
- 类必须是公开的
- 它必须有一个不带参数的公共构造函数(默认构造函数)
- 所有字段要么是公共的,要么必须可以通过 getter 和 setter 函数访问;对于名为 foo 的字段,getter 和 setter 方法必须命名为 getFoo() 和 setFoo()
- 字段的类型必须被已注册的序列化器支持
POJO 通常用 PojoTypeInfo 表示,并用 PojoSerializer 进行序列化(可以配置回退使用 Kryo 序列化器);除了 POJO 是 Avro 类型(Avro 特定记录)或作为 “Avro 反射类型” ,此时 POJO 由 AvroTypeInfo 表示,并使用 AvroSerializer 进行序列化;如果需要,还可以注册自定义的序列化程序;
可以通过 org.apache.flink.types.PojoTestUtils#assertSerializedAsPojo() 测试【类是否符合 POJO 要求】,如果想确保 POJO 的任何字段都不会使用 Kryo 进行序列化,可以使用 assertSerializedAsPojoWithoutKryo;
175.Primitive Types:Flink 支持所有 Java 和 Scala 基本类型,如 Integer、String 和 Double;
176.General Class Types:Flink 支持大多数 Java 和 Scala 类(API和自定义),对于包含无法序列化字段的类,如文件指针、I/O流或其它本机资源,会受限制;遵循 JavaBeans 约定的类可以正常使用;
Flink 将所有未标识为 POJO 类型的类,作为通用类的类型进行处理,Flink 将这些数据类型视为黑匣子,无法访问其内容;一般类型使用序列化框架 Kryo 进行序列化和反序列化;
177.Values:值类型需要手动描述它们的序列化和反序列化器,它们不是通过通用的序列化框架,而是通过实现 org.apache.flink.type 自定义读取和写入的方法;
当通用序列化器效率很低时,使用 Value 类型是合理的;示例将元素的稀疏向量用数组实现,其中数组元素大部分为零,就可以对非零元素使用特殊编码,而通用序列化器只需写入所有数组元素;
Flink 提供了与基本数据类型相对应的预定义值类型(ByteValue、ShortValue、IntValue、LongValue、FloatValue、DoubleValue、StringValue、CharValue、BooleanValue)这些值类型充当基本数据类型的变体,它们的值可以更改,允许重用对象并减轻 GC 的压力;
178.Hadoop Writables:使用实现了 org.apache.hadoop 接口的类型,使用 write() 和 readFields() 方法定义序列化和反序列化逻辑;
179.Special Types:特殊的类型,包括 Scala 的 Either,Option 和 Try;Java API 有 Either 的自定义实现,表示两种可能类型的值;
180.类型擦除:Java 编译器在编译后会丢弃许多泛型的类型信息,因此在运行时,对象的实例不再知道其泛型类型,例如 DataStream<String> 和 DataStream<Long> 的实例在 JVM 中看起来是相同的;
181.Flink 在调用程序的 main 方法时需要知道类型信息,Flink Java API 试图重建丢弃的类型信息,并将其显式存储在数据集和 operator 中;可以通过 DataStream.getType() 检索类型,该方法返回 TypeInformation 的一个实例,这是 Flink 表示类型的内部方式;
182.类型推断有其局限性,有时需要手动指定数据的类型,例如从集合创建数据集 StreamExecutionEnvironment.fromCollection(),可以在其中传递描述类型的参数;像 MapFunction<I,O> 这样的通用函数有时也需要额外的类型信息;
183.Flink 试图推断出在分布式计算过程中交换和存储的数据类型信息,在大多数情况下,Flink 会推断出所有必要的信息,使用户无需关心序列化框架和无需注册数据类型;
184.Flink 对数据类型了解得越多,序列化方案就越好;这对于 Flink 中的内存使用模式非常重要(尽可能在堆内/外处理序列化数据,使序列化成本非常低);
185.注册子类型:如果函数签名只描述超类型,但在执行过程中实际使用了超类型的子类型,那让 Flink 知道这些子类型会大大提高性能,需要在 StreamExecutionEnvironment 上为每个子类型调用.registerType(clazz);
186.注册自定义序列化程序:Flink 会为无法处理的类型使用 Kryo 序列化器,如果 kryo 序列化器也不能处理,需要在StreamExecutionEnvironment 上调用 .getConfig().addDefaultKryoSerializer(clazz,serializer) 注册自定义的序列化器;
187.添加类型提示(TypeHints):当 Flink 无法推断出通用类型时,必须传递类型提示,通常只有在 Java API 中需要;
188.TypeInformation 类是所有类型描述符的基类,它揭示了类型的一些基本属性,并可以为类型生成序列化器和比较器(Flink 中的比较器不仅定义顺序,还用于处理 keys);
189.在内部,Flink 对类型区分如下:
基本类型:Java 基本类型及其装箱形式以及 void、String、Date、BigDecimal 和 BigInteger;
基本数组和对象数组
复合类型:
Flink 的 Java 元组(Flink Java API的一部分):最多25个字段,不支持空字段;
Scala case classes (包括 Scala 元组):不支持 null 字段;
Row:具有任意数量的字段和支持空字段的元组;
POJO:遵循特定 bean 模式的类;
辅助类型:Option,Either,Lists,Maps,…;
泛型类型:Flink 本身不会序列化这些类型,而是由 Kryo 进行序列化;
190.POJO 类型规则:如果满足以下条件,Flink 将数据类型识别为 POJO 类型(并允许 “按名称” 字段引用):
该类是公共的和独立的(没有非静态内部类);
该类有一个公共的无参数构造函数;
类(和所有超类)中的所有非静态、非 transient 字段要么是公共的,要么有一个公共的 getter 和 setter 方法;
注意:当用户定义的数据类型无法识别为 POJO 类型时,必须将其处理为 GenericType 并使用 Kryo 进行序列化;
191.由于 Java 会擦除泛型类型信息,因此需要将类型传递给 TypeInformation:
对于非泛型类型,可以传递类:
TypeInformation<String> info = TypeInformation.of(String.class);
对于泛型类型,需要通过 TypeHint “捕获” 泛型类型信息:
TypeInformation<Tuple2<String, Double>> info = TypeInformation.of(new TypeHint<Tuple2<String, Double>>(){});
在内部,创建了 TypeHint 的一个匿名子类,该子类捕获泛型信息以将其保留到运行时;
192.有两种方法可以创建 TypeSerializer:
- 对 TypeInformation 对象调用 typeInfo.createSerializer(config),config 参数的类型为 ExecutionConfig,包含有关程序注册的自定义序列化器的信息;尽量将正确的 ExecutionConfig 传递给程序,可以通过调用 getExecutionConfig() 从 DataStream 中获取它;
- 在函数(如 RichMapFunction)内部使用 getRuntimeContext().createSerializer(typeInfo) 来获取它;
193.Java API中的类型提示:在 Flink 无法重建擦除的通用类型信息时,Java API 提供所谓的类型提示,类型提示告诉系统函数生成的数据流或数据集的类型,return 语句指定生成的类型;
194.Java 8 lambdas 的类型提取与非 lambdas 不同,因为 lambdas 与扩展函数接口的实现类无关,Flink 试图使用 Java 的泛型签名来确定参数类型和返回类型;但并非所有编译器都会为 Lambda 生成这些签名,有时也需要手动指定数据类型;
195.PojoTypeInfo 为 POJO 中的所有字段创建序列化程序;int、long、String 等标准类型由 Flink 自带的序列化程序处理,对于其它类型使用 Kryo,如果 Kryo 无法处理该类型,可以要求 PojoTypeInfo 使用 Avro 序列化 POJO,调用方法如下:env.getConfig().enableForceAvro();
196.Flink 会使用 Avro 序列化器自动序列化 Avro 生成的 POJO,如果希望 Kryo 序列化器处理整个 POJO 类型,配置如下:
env.getConfig().enableForceKryo();
197.如果 Kryo 无法序列化 POJO,可以向 Kryo 添加自定义序列化程序:
env.getConfig().addDefaultKryoSerializer(Class<?> type, Class<? extends Serializer<?>> serializerClass);
198.如果程序需要避免使用 Kryo 作为泛型类型的回退,确保通过 Flink 自己的序列化程序或通过用户自定义的自定义序列化程序有效地序列化所有类型,配置如下:env.getConfig().disableForceKryo();
注意:遇到要使用 Kryo 的数据类型时,以下设置会引发异常
env.getConfig().disableGenericTypes();
199.类型信息工厂允许将用户定义的类型信息插入 Flink 类型系统,需要实现 org.apache.flink.api.common.typeinfo.TypeInfoFactory 以返回自定义的类型信息;
如果相应的类型已经用 @org.apache.flink.api.common.typeinfo.TypeInfo 注解,则在类型提取阶段会调用工厂;
类型信息工厂可以在 Java 和 Scala API 中使用,在类型层次结构中,向上遍历时将选择最近的工厂,内置工厂具有最高优先级;工厂的优先级也高于 Flink 的内置类型;
200.方法 createTypeInfo(Type,Map<String,TypeInformation<?>) 为工厂的目标类型创建类型信息;这些参数提供了有关类型本身的附加信息,以及类型的泛型类型参数;
如果类型包含需要从 Flink 函数的输入类型派生的泛型参数,请确保还实现了org.apache.Flink.api.common.typeinfo.TypeInformation#getGenericParameters 用于泛型参数到类型信息的双向映射;
201.在内部,状态是否可以进行升级取决于用于读写持久化状态字节的序列化器,状态数据结构只有在其序列化器正确支持时才能升级;这一过程是被 Flink 的类型序列化框架生成的序列化器透明处理的;只适用于 Flink 自己生成的状态序列化器;即在声明状态时,状态描述符不可以配置为使用特定的 TypeSerializer 或 TypeInformation;
202.对状态类型升级,步骤如下:
- 对 Flink 流作业进行 savepoint 操作;
- 升级程序中的状态类型(例如:修改 Avro 的结构);
- 从 savepoint 恢复作业。当第一次访问状态数据时,Flink 会判断状态数据 schema 是否已经改变,并进行必要的迁移;
适应状态结构的改变而进行的状态迁移过程是自动发生的,并且状态之间是互相独立的;
203.Flink 内部首先会检查新的序列化器相对比之前的序列化器是否有不同的状态结构;如果有,那么之前的序列化器用来读取状态数据字节到对象,然后使用新的序列化器将对象回写为字节;
204.目前仅支持 POJO 和 Avro 类型的 schema 升级:
POJO 类型:Flink 基于下面的规则来支持 POJO 类型结构的升级
- 可以删除字段。一旦删除,被删除字段的前值将会在将来的 checkpoints 以及 savepoints 中删除。
- 可以添加字段。新字段会使用类型对应的默认值进行初始化。
- 不可以修改字段的声明类型。
- 不可以改变 POJO 类型的类名,包括类的命名空间。
注意:只有从 1.8.0 及以上版本的 Flink 生产的 savepoint 进行恢复时,POJO 类型的状态才可以进行升级;对 1.8.0 版本之前的 Flink 是没有办法进行 POJO 类型升级的;
Avro 类型:Flink 支持 Avro 状态类型的升级,只要数据结构的修改是被 Avro 的数据结构解析规则认为兼容的即可
除非新的 Avro 数据 schema 生成的类无法被重定位或者使用了不同的命名空间,在作业恢复时状态数据会被认为是不兼容的;
205.Flink 的 Schema 迁移有一些限制,这些限制是确保正确性所必需的;对于需要绕过这些限制并理解它们在特定用例中是安全的用户,可以考虑使用自定义序列化程序或状态处理器 API:
不支持 key 的 schema 演变:无法迁移 key 的 schema,因为这可能导致不确定性行为;如果一个 POJO 被用作 key,并且一个字段被丢弃,那么可能会突然出现多个现在相同的单独键,Flink无法合并相应的值;
此外,RocksDB 状态后端依赖于二进制对象标识,而不是 hashCode 方法,对 key 的对象结构的任何更改都可能导致不确定性行为;
Kryo 不能用于 schema 演变:当使用 Kryo 时,框架不能验证是否进行了不兼容的更改;如果包含给定类型的数据结构通过 Kryo 进行序列化,那么所包含的类型就不能进行 schema 进化;如果一个 POJO 包含一个 List<SometherPojo>,那么该 List 及其内容是通过 Kryo 序列化的,SometherPojo 不支持模式演化;
206.对状态使用自定义序列化,包含如何提供自定义状态序列化程序、实现允许状态模式演变的序列化程序;
207.注册托管 operator 或 keyed 状态时,需要 StateDescriptor 来指定状态的名称以及有关状态类型的信息,Flink 的类型序列化框架使用类型信息为状态创建适当的序列化程序;
208.可以让 Flink 使用自定义的序列化程序来序列化托管状态,只需使用自定义的 TypeSerializer 实现直接实例化 StateDescriptor:
new ListStateDescriptor<>("state-name",new CustomTypeSerializer());
209.从保存点恢复时,Flink 允许更改用于读取和写入先前注册状态的序列化程序,当状态恢复时,将为该状态注册一个新的序列化程序(即用于访问已恢复作业中的状态的 StateDescriptor 附带的序列化程序);这个新的序列化程序可能具有与以前的序列化程序不同的模式;因此,在实现状态序列化程序时,除了读取/写入数据的基本逻辑外,还需要实现如何更改序列化模式;
210.模式可能会在以下几种情况下发生变化:
- 状态类型的数据模式已经改变。即从用作状态的 POJO 中添加或删除字段;一般来说,在更改数据模式后,需要升级序列化程序的序列化格式。
- 序列化程序的配置已更改。为了使新的执行具有写入的状态模式的信息并检测模式是否已经改变,在获取 operator 状态的保存点时,需要将状态序列化器的快照与状态字节一起写入。
211.序列化程序的 TypeSerializerSnapshot 是一个时间点信息,它是关于状态序列化程序写入 schema 的唯一记录,以及还原与给定时间点相同的序列化程序所必需的附加信息;在 writeSnapshot 和 readSnapshot 方法中定义了在恢复时作为序列化程序快照应写入和读取的逻辑;
212.快照自己的写入模式可能也需要随着时间的推移而更改(例如,当希望向快照添加更多有关序列化程序的信息时);为了便于实现这一点,使用 getCurrentVersion 方法中定义的当前版本号对快照进行版本控制;在还原时,从保存点读取序列化程序快照时,写入快照的 schema 的版本将提供给 readSnapshot 方法,以便读取可以实现处理不同的版本;
213.在恢复时,应在 resolveSchemaCompatibility 方法中实现检测新序列化程序的 schema 是否已更改的逻辑;当在 operator 的恢复执行中,以前注册的状态再次向新的序列化程序注册时,旧的序列化程序快照将通过此方法提供给新的序列化器快照;此方法返回表示兼容性解析结果的 TypeSerializerSchemaCompatibility,它可以是以下内容之一:
- TypeSerializerSchemaCompatility.compatibleAsIs():此结果表示新的序列化程序是兼容的,即新的序列化器与以前的序列化程序具有相同的 schema。新的序列化程序可能已在 resolveSchemaCompatibility 方法中重新配置,因此它是兼容的。
- TypeSerializerSchemaCompatibility.compatibleAfterMigration():此结果表示新的序列化程序具有不同的序列化架构,可以通过使用以前的序列化程序(识别旧架构)将字节读取到状态对象中,然后使用新的序列化器(识别新架构)将对象重写回字节,从而从旧架构迁移。
- TypeSerializerSchemaCompatibility.incompatible():此结果表示新的序列化程序具有不同的序列化 schema,但无法从旧架构迁移。
214.序列化程序的 TypeSerializerSnapshot 的另一个重要作用是,它充当还原以前的序列化程序的工厂;即 TypeSerializerSnapshot 应该实现 restoreSerializer 方法来实例化一个序列化程序实例,该序列化程序实例可以识别以前的序列化程序的 schema 和配置,因此可以安全地读取以前的序列化程序器写入的数据;
215.Flink 如何与 TypeSerializer 和 TypeSerializerSnapshot 抽象交互:根据状态后端的不同,状态后端与抽象交互略有不同
堆外状态后端(例如 RocksDBStateBackend)【向具有 schema A 的状态序列化程序注册新状态、获取保存点、执行恢复时使用具有 schema B 的新状态序列化程序重新访问恢复的状态字节、将状态后端中的状态字节从 schema A迁移到 schema B】
堆状态后端(例如MemoryStateBackend、FsStateBackend)【向具有 schema A 的状态序列化程序注册新状态、取一个保存点,用 schema A 序列化所有状态、恢复时,将状态反序列化为堆中的对象、执行恢复时使用具有 schema B 的新状态序列化程序重新访问以前的状态、取另一个保存点,用 schema B 序列化所有状态】
216.Flink 提供了两个典型场景的 TypeSerializerSnapshot 的抽象基类:SimpleTypeSerializerSnapshot 和CompositeTypeSerializerSnapshot;
SimpleTypeSerializerSnapshot 适用于没有任何状态或配置的序列化程序,意味着序列化程序的序列化 schema 仅由序列化程序的类定义;IntSerializer 没有状态或配置,序列化格式仅由序列化程序类本身定义,并且只能由另一个 IntSerializer 读取,它适合SimpleTypeSerializerSnapshot 的用例;
CompositeTypeSerializerSnapshot 适用于依赖多个嵌套序列化程序进行序列化的序列化程序;将依赖于多个嵌套序列化程序的序列化程序称为 “外部” 序列化程序;例如,MapSerializer、ListSerializer 和 GenericArraySerializer等;当考虑 MapSerializer 的键和值序列化程序时将是嵌套的序列化程序,而 MapSerialize 器本身是“外部”序列化程序;
217.如果在 Flink 程序中使用了 Flink 类型序列化器无法进行序列化的用户自定义类型,Flink 会回退到通用的 Kryo 序列化器;可以使用 Kryo 注册自己的序列化器或序列化系统,比如 Google Protobuf 或 Apache Thrift;
218.使用方法是在 Flink 程序中的 ExecutionConfig 注册类类型以及序列化器;需要确保你的自定义序列化器继承了 Kryo 的序列化器类,对于 Google Protobuf 或 Apache Thrift,这一点已经做好了;
219.flink 自带的 Tuple 类的序列化性能最高,其中一部分原因来源于不需要使用反射来访问 Tuple 中的字段;
220.Pojo 序列化比 Tuple 序列化性能差一些,但是比 kryo 的序列化方式性能要高几倍;
221.Protobuf 或者 Thrift 经由 Kryo 注册后,其序列化性能并不差;
222.创建用户自定义函数的方式【实现接口(implements MapFunction<I,O>)、匿名类(new MapFunction<I,O> (){})、Lambdas 表达式、继承 Rich functions(extends RichMapFunction<I,O>)】;
223.累加器是具有【加法运算】和【最终累加结果】的一种简单结构,可在作业结束后使用;
224.在作业结束时,Flink 会汇总(合并)所有部分的结果并将其发送给客户端,Flink 目前有如下内置累加器,每个都实现了累加器接口:
IntCounter,LongCounter 和 DoubleCounter;
Histogram(直方图):离散数量的柱状直方图实现【在内部,它只是整形到整形的映射,可以用它来计算值的分布】;
225.单个作业的所有累加器共享一个命名空间,可以在不同的操作 function 里面使用同一个累加器;Flink 会在内部将所有具有相同名称的累加器合并起来;
226.自定义累加器只需要实现累加器接口,可以选择实现 Accumulator 或 SimpleAccumulator:
Accumulator:定义了将要添加的值类型 V,并定义了最终的结果类型 R;
SimpleAccumulator:适用于两种类型都相同的情况;
227.通过调用 execute() 方法返回的 JobExecutionResult 对象获得累加器结果(只有等待作业完成后执行才起作用);
228.为了使用事件时间语义,Flink 应用程序需要知道事件时间戳对应的字段,即数据流中的每个元素都需要拥有可分配的事件时间戳;
229.可以通过使用 TimestampAssigner API 从元素中的某个字段去访问/提取时间戳;
230.时间戳的分配与 watermark 的生成是齐头并进的,表明 Flink 应用程序事件时间的进度,可以通过指定 WatermarkGenerator 来配置 watermark 的生成方式;
231.使用 Flink API 时需要设置一个同时包含 TimestampAssigner 和 WatermarkGenerator 的 WatermarkStrategy,WatermarkStrategy 工具类中也提供了许多常用的 watermark 策略,用户也可以自定义 watermark 策略;
232.可以使用 WatermarkStrategy 工具类中通用的 watermark 策略,或者使用这个工具类将自定义的 TimestampAssigner 与 WatermarkGenerator 进行绑定;
233. 时间戳和 watermark 都是从 1970-01-01T00:00:00Z 起的 Java 纪元开始,并以毫秒为单位;
234.WatermarkStrategy 可以在 Flink 应用程序中的两处使用,第一种是在数据源上使用,第二种是在非数据源的操作之后使用;
第一种方式更好,因为数据源可以利用 watermark 生成逻辑中有关分片/分区(shards/partitions/splits)的信息,数据源可以更精准地跟踪 watermark,整体 watermark 生成将更精确;直接在源上指定 WatermarkStrategy 意味着必须使用特定数据源接口,例如 KafkaSource;
仅当无法直接在数据源上设置策略时,才应该使用第二种方式(在任意转换操作之后设置 WatermarkStrategy);
235.使用 WatermarkStrategy 去获取流并生成带有时间戳的元素和 watermark 的新流时,如果原始流已经具有时间戳或 watermark,则新指定的时间戳分配器将覆盖原有的时间戳和 watermark;
236.如果数据源中的某一个分区/分片在一段时间内未发送事件数据,则意味着 WatermarkGenerator 也不会获得任何新数据去生成 watermark,称这类数据源为空闲输入或空闲源;
237.可以使用 WatermarkStrategy 来检测空闲输入并将其标记为空闲状态,WatermarkStrategy.withIdleness;
238.某些 splits/partitions/shards 或 source 可能会非常快地处理记录,从而使其 Watermark 的增加速度相对较快,对于使用 Watermark 处理数据的下游 Operator 来说,下游 Operator(如Window Join)的水印可以正常进行,但是 Operator 需要缓冲来自快速输入的过多数据量,因为来自其所有输入的最小 Watermark 被滞后;
239.由快速输入发出的所有记录都必须在下游 Operator 的状态中进行缓冲,这可能导致 Operator 状态的不可控增长,可以启用 Watermark 对齐,确保没有 splits/partitions/shards 或 source 将其 Watermark 增加得比其它源多太多,可以分别为每个源启用对齐,WatermarkStrategy.withWatermarkAlignment("alignment-group-1", Duration.ofSeconds(20), Duration.ofSeconds(1));
当启用 Watermark 对齐时,需要告诉 Flink,source 应属于哪个组,通过提供一个标签(例如alignment-group-1)来实现,该标签将共享它的所有 source 绑定在一起;
此外,必须告诉属于该组的所有 source 的当前最小水印的最大漂移,第三个参数描述了当前最大水印应该多久更新一次,频繁更新的缺点是在TM和JM之间会有更多的RPC消息传输;
240.只有 FLIP-27 的 source 可以启用水印对齐,它不适用于历史版本,不适用于在数据源之后应用 assignTimestampsAndWatermarks;
241.为了实现对齐,Flink 将暂停从源/任务进行消费,它将继续读取其他来源/任务的记录,这些来源/任务可以向前移动组合水印,从而解锁更快的水印;
242.从 Flink 1.17 开始,FLIP-27 源框架支持拆分级别的水印对齐,源连接器实现一个接口来恢复和暂停拆分,以便在同一任务中对齐splits/partitions/shards;
243.如果从 1.15.x 和 1.16.x(含1.15.x)之间的 Flink 版本升级,通过将 pipeline.watermark-alignment.allow-unaligned-source-splits 设置为 true 来禁用拆分级别对齐;
244.当将标志设置为 true 时,只有当 splits/partitions/shards 的数量等于源运算符的并行度时,水印对齐才能正常工作,这导致每个子任务都被分配一个工作单元;另一方面,如果有两个 Kafka 分区,它们以不同的速度生成水印,并被分配给同一个任务,那么水印可能不会像预期的那样工作;但即使在最坏的情况下,基本对齐的性能也不会比根本没有对齐差;
245.Flink 支持在相同来源和不同来源的任务之间进行对齐,当有两个不同的来源(例如 Kafka 和 File )以不同的速度生成水印时,这很有用;
246.WatermarkGenerator#onEvent:每来一条事件数据调用一次,可以检查或者记录事件的时间戳,也可以基于事件数据本身生成 watermark;
247.WatermarkGenerator#onPeriodicEmit:周期性的调用,可能会生成新的 watermark,调用此方法生成 watermark 的间隔时间由 ExecutionConfig#getAutoWatermarkInterval 决定;
248.watermark 的生成方式本质上有两种:周期性生成和标记生成;
周期性生成器通过 onEvent() 观察传入的事件数据,然后在框架调用 onPeriodicEmit() 时发出 watermark;
标记生成器将查看 onEvent() 中的事件数据,并检查在流中携带 watermark 的特殊标记事件或打点数据,当获取到这些事件数据时,它将立即发出 watermark,通常标记生成器不会通过 onPeriodicEmit() 发出 watermark;
249.周期性生成器会观察流事件数据并定期生成 watermark(其生成可能取决于流数据,或者完全基于处理时间);
250.生成 watermark 的时间间隔(每 n 毫秒)可以通过 ExecutionConfig.setAutoWatermarkInterval(...) 指定;每次都会调用生成器的 onPeriodicEmit() 方法,如果返回的 watermark 非空且值大于前一个 watermark,则将发出新的 watermark;
251.标记 watermark 生成器观察流事件数据并在获取到带有 watermark 信息的特殊事件元素时发出 watermark;
252.可以针对每个事件生成 watermark,但每个 watermark 都会在下游做一些计算,因此过多的 watermark 会降低程序性能;
253.可以使用 Flink 中可识别 Kafka 分区的 watermark 生成机制;将在 Kafka 消费端内部针对每个 Kafka 分区生成 watermark,并且不同分区 watermark 的合并方式与在数据流 shuffle 时的合并方式相;
254.在将 watermark 转发到下游之前,需要算子对其进行触发的事件完全进行处理;即由于此 watermark 的出现而产生的所有数据元素都将在此 watermark 之前发出;
255.相同的规则也适用于 TwoInputStreamOperator;此时算子当前的 watermark 会取其两个输入的最小值;
256.WatermarkStrategy 包含 TimestampAssigner 和 WatermarkGenerator;
257.单调递增时间戳分配器:周期性 watermark 生成方式最简单的特例就是给定的数据源中数据的时间戳升序出现;此时当前时间戳就可以充当 watermark,因为后续到达数据的时间戳不会比当前的小;
WatermarkStrategy.forMonotonousTimestamps();
在 Flink 应用程序中,如果是并行数据源,则只要求并行数据源中的每个单分区数据源任务时间戳递增;
Flink 的 watermark 合并机制会在并行数据流进行分发(shuffle)、联合(union)、连接(connect)或合并(merge)时生成正确的 watermark;
258.数据之间存在最大固定延迟的时间戳分配器:当 watermark 滞后于数据流中最大(事件时间)时间戳一个固定的时间量;即预先知道数据流中的数据可能遇到的最大延迟;
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10));
Flink 针对上述场景提供了 boundedOutfordernessWatermarks 生成器,该生成器将 maxOutOfOrderness 作为参数,该参数代表在计算给定窗口的结果时,允许元素被忽略计算之前延迟到达的最长时间;
其中延迟时长就等于 t - t_w,其中 t 代表元素的(事件时间)时间戳,t_w 代表前一个 watermark 对应的(事件时间)时间戳;如果 lateness > 0,则认为该元素迟到了,并且在计算相应窗口的结果时默认会被忽略;
259.WithIdleness(处理时间):针对某个数据源无数据有效;针对单个数据源某个分区无数据也有效;
260.是否在生成水位线和分配时间戳之前进行 keyby,对于水位线的生成会有影响(导致数据被分配的 subtask 不同),要考虑是否配置空闲数据源;
261.水位线的计算:
单数据源单分区:当前的(eventtime-1)ms;
单数据源多分区:以最小分区的 watermark 为主;
多数据源单分区\多分区:以两个数据源间最小分区的 watermark 为主;
262.DataStream API 的流(STREAMING)执行模式,适用于需要连续增量处理,而且常驻线上的无边界作业;
263.DataStream API 的批(BATCH)执行模式,类似于 MapReduce 等批处理框架,适用于已知输入、不会连续运行的的有边界作业;
264.Flink 对流处理和批处理采取统一的处理方式,无论配置何种执行模式,在有界输入上执行的 DataStream 应用都会产生相同的最终结果;在流模式执行的作业可能会产生增量更新(类似于数据库中的插入(upsert)操作),而批作业只在最后产生一个最终结果;
265.通过启用批执行模式,Flink 可以对有边界作业进行额外的优化:可以使用不同的关联(join)/ 聚合(aggregation)策略、不同 shuffle 实现来提高任务调度和故障恢复的效率等;
266.批执行模式只能用于有边界的作业/Flink 程序:
267.边界:是数据源的一个属性,表明是否在执行之前已经知道来自该数据源的所有输入,或者新数据是否会无限期地出现;如果作业的所有源都是有边界的,则它就是有边界的,否则就是无边界的;
流执行模式,既可用于有边界任务,也可用于无边界任务;
批执行模式,只用于有边界任务;
268.使用流模式运行有边界作业:
- 使用有边界作业的运行结果去初始化作业状态,并将该状态在之后的无边界作业中使用;例如,通过`流`模式运行一个有边界作业,获取一个 savepoint,然后在一个无边界作业上恢复这个 savepoint【将 savepoint 作为 `批` 执行作业的附加输出】;
- 为无边界数据源写测试代码时,使用有边界数据源更自然。
269.配置批执行模式
执行模式可以通过 execution.runtime-mode 配置,可选值如下:
- STREAMING: 经典 DataStream 执行模式(默认)
- BATCH: 在 DataStream API 上进行批量式执行
- AUTOMATIC: 让系统根据数据源的边界性来决定
可以通过 bin/flink run ... 的命令行参数配置,或者在创建/配置 StreamExecutionEnvironment 时写进程序;
注意:不建议在程序中设置运行模式,而是在提交应用程序时使用命令行设置,保持应用程序代码的免配置可以让程序更加灵活,因为同一个应用程序可能在任何执行模式下执行;
270.执行行为-任务调度与网络 Shuffle
270.1在流执行模式下,所有任务需要持续运行;Flink可以通过整个管道立即处理新的记录,以达到需要的连续和低延迟的流处理;同时分配给某个作业的 TaskManagers 需要有足够的资源来同时运行所有的任务;
网络 shuffle 是流水线式的,记录会立即发送给下游任务,在网络层上进行一些缓冲;当处理连续的数据流时,在任务(或任务管道)之间没有可以实体化的自然数据点(时间点),而在批执行模式下,中间的结果可以被实体化;
270.2在批执行模式下,作业的任务可以分阶段执行;因为输入是有边界的,因此 Flink 可以在进入下一个阶段之前完全处理管道中的一个阶段;在上面的例子中,工作会有三个阶段,对应着被 shuffle 界线分开的三个任务;
分阶段处理要求 Flink 将任务的中间结果实体化到非永久存储中,让下游任务在上游任务下线后再读取,将增加处理的延迟,但这允许 Flink 在故障发生时回溯到最新的可用结果,而不是重新启动整个任务;同时批作业可以在更少的资源上执行;
在批执行模式中,因为输入数据是有边界的,Flink 可以使用更高效的数据结构和算法来进行任务调度和网络 shuffle;
TaskManagers 将至少在下游任务开始消费前保留中间结果,在这之后,只要空间允许,中间结果就会被保留,以便任务失败回滚;
271.执行行为-State Backends/State
在流模式下,Flink 使用 StateBackend 控制状态的存储方式和检查点的工作方式;
在批模式下,配置的 state backend 被忽略;对输入按 key 分组(使用排序),依次处理一个 key 的所有记录,以便在同一时间只保留一个 key 的状态,当进行到下一个 key 时,上一个 key 的状态将被丢弃;
272.执行行为-处理顺序
在批执行和流执行中,算子或用户自定义函数(UDF)处理记录的顺序可能不同:
在流模式下,对于用户自定义函数,数据一到达就被处理;
在批模式下,Flink 确保数据有序,排序可以是特定调度任务、网络 shuffle、上文提到的 state backend 等;
将常见输入类型分为三类:
- 广播输入(broadcast input): 从广播流输入【广播状态】;
- 常规输入(regular input): 既不从广播输入或也不从 keyed 输入;
- keyed 输入(keyed input): 从 KeyedStream 输入;
消费多种类型输入的函数或算子,处理顺序如下:
- 广播输入第一个处理
- 常规输入第二个处理
- keyed 输入最后处理
对于从多个常规或广播输入进行消费的函数 — 比如 CoProcessFunction — Flink 有权从任一输入以任意顺序处理数据;
对于从多个keyed输入进行消费的函数 — 比如 KeyedCoProcessFunction — Flink 先处理单一键中的所有记录再处理下一个;
273.执行行为-事件时间/水印
在流模式下,存在数据乱序的可能,使用 Watermark(一个带有时间戳 T 的水印)标志再没有时间戳 t < T 的元素跟进;
在批模式下,输入的数据集是事先已知的,至少可以按照时间戳对元素进行排序,从而按照时间顺序进行处理,不存在数据乱序的可能;
综上:在批模式下,只需要在输入的末尾有一个与每个键相关的 MAX_WATERMARK,如果输入流没有键,则在输入的末尾需要一个 MAX_WATERMARK;所有注册的定时器都会在时间结束时触发,用户定义的 WatermarkAssigners 或 WatermarkStrategies 会被忽略;但配置 WatermarkStrategy 是有用的,因为它的 TimestampAssigner 仍然会被用来给记录分配时间戳;
274.执行行为-处理时间
处理时间是指在处理记录的具体实例上,处理记录的机器上的时钟时间,基于处理时间的计算结果是不可重复的,因为同一条记录被处理两次,会有两个不同的时间戳;
在流模式下,事件时间和处理时间存在相关性;在流模式下事件时间的1小时也几乎是处理时间的1小时,使用处理时间可以用于早期(不完全)触发,给出预期结果的提示;
在批模式下,事件时间和处理时间相关性不存在,因为输入的数据集是静态的;允许用户请求当前的处理时间,并注册处理时间定时器,但与事件时间的情况一样,所有的定时器都要在输入结束时触发。
在作业执行过程中,处理时间不会提前,当整个输入处理完毕后,会快进到时间结束;
275.执行行为-故障恢复
在流模式下,Flink 使用 checkpoint 进行故障恢复,在发生故障时,Flink 会从 checkpoint 重新启动所有正在运行的任务;
在批模式下,Flink 会尝试回溯到之前的中间结果仍可获取的处理阶段,只有失败的任务才需要重新启动,相比从 checkpoint 重新启动所有任务,可以提高作业的处理效率和整体处理时间;
276.批模式下的行为变化
- 滚动操作,如 reduce() 或 sum(),会对流模式下每一条新记录发出增量更新,在批模式下,只发出最终结果;
277.批模式下不支持
- Checkpointing 和任何依赖于 checkpointing 的操作都不支持;
278.批处理程序的故障恢复不使用检查点,因为没有 checkpoints,某些功能如 CheckpointListener ,以及因此,Kafka 的精确一次(EXACTLY_ONCE) 模式或 File Sink 的 OnCheckpointRollingPolicy 将无法工作;
279.仍然可以使用所有的状态原语(state primitives),只是用于故障恢复的机制会有所不同;
280.在流模式下运行良好的 Operator 可能会在批模式下产生错误的结果:
- 在批模式下,会逐个 key 处理记录;因此,Watermark 会在每个 key 之间从 MAX_VALUE 切换到 MIN_VALUE;
- Watermark 在一个算子中不总是递增的;
- 定时器将首先按 key 的顺序触发,然后按每个 key 内的时间戳顺序触发;
- 不支持手动更改 key 的操作;
281.Flink 程序基本组成:
- 获取一个执行环境(execution environment);
- 加载/创建初始数据;
- 指定数据相关的转换;
- 指定计算结果的存储位置;
- 触发程序执行;
282.通常使用 getExecutionEnvironment() 即可,该方法会根据上下文做正确的处理:
- 如果在 IDE 中执行程序或将其作为一般的 Java 程序执行,那么它将创建一个本地环境,该环境将在本地机器上执行程序;
- 如果基于程序创建了一个 JAR 文件,并通过命令行运行它,Flink 集群管理器将执行程序的 main 方法,同时 getExecutionEnvironment() 方法会返回一个执行环境以在集群上执行程序;
283.执行环境提供了一些方法,支持使用各种方法从文件中读取数据;
284.指定 data sources 将生成一个 DataStream,可以在上面应用转换(transformation)来创建新的派生 DataStream,可以调用 DataStream 上具有转换功能的方法来应用转换;
285.通过创建 sink 把包含最终结果的 DataStream 写到外部系统;
286.需要调用 StreamExecutionEnvironment 的 execute() 方法来触发程序执行,根据 ExecutionEnvironment 的类型,执行会在本地机器上触发,或将程序提交到某个集群上执行;
execute() 方法将等待作业完成,然后返回一个 JobExecutionResult,其中包含执行时间和累加器结果;
如果不想等待作业完成,可以调用 StreamExecutionEnvironment 的 executeAsync() 方法来触发作业异步执行,它会返回一个 JobClient,可以通过它与刚刚提交的作业进行通信;
287.所有 Flink 程序都是延迟执行的:
- 当程序的 main 方法被执行时,数据加载和转换不会直接发生,而是每个算子都被创建并添加到 dataflow 形成的有向图中;
- 当被执行环境的 execute() 方法显示地触发时,这些算子才会真正执行;
288.Source 用于程序获取数据,可以用 StreamExecutionEnvironment.addSource(sourceFunction) 将一个 source 关联到程序中;
289.Flink 自带了许多预先实现的 source functions,也可以实现 SourceFunction 接口编写自定义的非并行 source,也可以实现 ParallelSourceFunction 接口或者继承 RichParallelSourceFunction 类编写自定义的并行 sources;
290.通过 StreamExecutionEnvironment 可以访问预定义的 stream source;
291.Data sinks 使用 DataStream 并将它们转发到文件、套接字、外部系统或打印它们;Flink 自带了多种内置的输出格式,这些格式相关的实现封装在 DataStreams 的算子里;
292.DataStream 的 write*() 方法主要用于调试,不参与 Flink 的 checkpointing,通常这些函数具有至少有一次语义,刷新到目标系统的数据取决于 OutputFormat 的实现,并非所有发送到 OutputFormat 的元素都会立即显示在目标系统中;此外,在失败的情况下,这些记录可能会丢失;
293.为了将流可靠地、精准一次地传输到文件系统中,请使用 FileSink;通过 .addSink(...) 方法调用的自定义实现也可以参与 Flink 的 checkpointing,以实现精准一次的语义;
294.StreamExecutionEnvironment 包含了 ExecutionConfig,它允许在运行时设置作业特定的配置值;
295.State & Checkpointing 描述了如何启用和配置 Flink 的 checkpointing 机制;
296.默认情况下,元素不会在网络上一一传输(这会导致不必要的网络传输),而是被缓冲;缓冲区的大小(实际在机器之间传输)可以在 Flink 配置文件中设置,虽然此方法有利于优化吞吐量,但当输入流不够快时,它可能会导致延迟问题;
297.要控制吞吐量和延迟,可以调用执行环境(或单个算子)的 env.setBufferTimeout(timeoutMillis) 方法来设置缓冲区填满的最长等待时间,超过此时间后,即使缓冲区未满,也会被自动发送,超时时间的默认值为 100 毫秒;
298.为了最大限度地提高吞吐量,设置 setBufferTimeout(-1) 来删除超时,这样缓冲区仅在已满时才会被刷新;
299.要最小化延迟,请将超时设置为接近 0 的值(例如 5 或 10 毫秒)应避免超时为 0 的缓冲区,因为它会导致严重的性能下降;
300.LocalStreamEnvironment 在创建它的同一个 JVM 进程中启动 Flink 系统,如果从 IDE 启动 LocalEnvironment,则可以在代码中设置断点并轻松调试程序;
301.Flink 提供了一个 sink【collectAsync】来收集 DataStream 的结果,但在程序完成时或者 CheckPoint 触发时才会输出结果;
1、DataStream API
1)概述
1.总结
1.Flink 程序基本组成:
- 获取一个执行环境(execution environment);
- 加载/创建初始数据;
- 指定数据相关的转换;
- 指定计算结果的存储位置;
- 触发程序执行;
2.通常使用 getExecutionEnvironment() 即可,该方法会根据上下文做正确的处理:
- 如果在 IDE 中执行程序或将其作为一般的 Java 程序执行,那么它将创建一个本地环境,该环境将在本地机器上执行程序;
- 如果基于程序创建了一个 JAR 文件,并通过命令行运行它,Flink 集群管理器将执行程序的 main 方法,同时 getExecutionEnvironment() 方法会返回一个执行环境以在集群上执行程序;
3.执行环境提供了一些方法,支持使用各种方法从文件中读取数据;
4.指定 data sources 将生成一个 DataStream,可以在上面应用转换(transformation)来创建新的派生 DataStream,可以调用 DataStream 上具有转换功能的方法来应用转换;
5.通过创建 sink 把包含最终结果的 DataStream 写到外部系统;
6.需要调用 StreamExecutionEnvironment 的 execute() 方法来触发程序执行,根据 ExecutionEnvironment 的类型,执行会在本地机器上触发,或将程序提交到某个集群上执行;
execute() 方法将等待作业完成,然后返回一个 JobExecutionResult,其中包含执行时间和累加器结果;
如果不想等待作业完成,可以调用 StreamExecutionEnvironment 的 executeAsync() 方法来触发作业异步执行,它会返回一个 JobClient,可以通过它与刚刚提交的作业进行通信;
7.所有 Flink 程序都是延迟执行的:
- 当程序的 main 方法被执行时,数据加载和转换不会直接发生,而是每个算子都被创建并添加到 dataflow 形成的有向图中;
- 当被执行环境的 execute() 方法显示地触发时,这些算子才会真正执行;
8.Source 用于程序获取数据,可以用 StreamExecutionEnvironment.addSource(sourceFunction) 将一个 source 关联到程序中;
9.Flink 自带了许多预先实现的 source functions,也可以实现 SourceFunction 接口编写自定义的非并行 source,也可以实现 ParallelSourceFunction 接口或者继承 RichParallelSourceFunction 类编写自定义的并行 sources;
10.通过 StreamExecutionEnvironment 可以访问预定义的 stream source;
11.Data sinks 使用 DataStream 并将它们转发到文件、套接字、外部系统或打印它们;Flink 自带了多种内置的输出格式,这些格式相关的实现封装在 DataStreams 的算子里;
12.DataStream 的 write*() 方法主要用于调试,不参与 Flink 的 checkpointing,通常这些函数具有至少有一次语义,刷新到目标系统的数据取决于 OutputFormat 的实现,并非所有发送到 OutputFormat 的元素都会立即显示在目标系统中;此外,在失败的情况下,这些记录可能会丢失;
13.为了将流可靠地、精准一次地传输到文件系统中,请使用 FileSink;通过 .addSink(...) 方法调用的自定义实现也可以参与 Flink 的 checkpointing,以实现精准一次的语义;
14.StreamExecutionEnvironment 包含了 ExecutionConfig,它允许在运行时设置作业特定的配置值;
15.State & Checkpointing 描述了如何启用和配置 Flink 的 checkpointing 机制;
16.默认情况下,元素不会在网络上一一传输(这会导致不必要的网络传输),而是被缓冲;缓冲区的大小(实际在机器之间传输)可以在 Flink 配置文件中设置,虽然此方法有利于优化吞吐量,但当输入流不够快时,它可能会导致延迟问题;
17.要控制吞吐量和延迟,可以调用执行环境(或单个算子)的 env.setBufferTimeout(timeoutMillis) 方法来设置缓冲区填满的最长等待时间,超过此时间后,即使缓冲区未满,也会被自动发送,超时时间的默认值为 100 毫秒;
18.为了最大限度地提高吞吐量,设置 setBufferTimeout(-1) 来删除超时,这样缓冲区仅在已满时才会被刷新;
19.要最小化延迟,请将超时设置为接近 0 的值(例如 5 或 10 毫秒)应避免超时为 0 的缓冲区,因为它会导致严重的性能下降;
20.LocalStreamEnvironment 在创建它的同一个 JVM 进程中启动 Flink 系统,如果从 IDE 启动 LocalEnvironment,则可以在代码中设置断点并轻松调试程序;
21.Flink 提供了一个 sink【collectAsync】来收集 DataStream 的结果,但在程序完成时或者 CheckPoint 触发时才会输出结果;
2、执行模式
1)概述
1.总结
1.DataStream API 的流(STREAMING)执行模式,适用于需要连续增量处理,而且常驻线上的无边界作业;
2.DataStream API 的批(BATCH)执行模式,类似于 MapReduce 等批处理框架,适用于已知输入、不会连续运行的的有边界作业;
3.Flink 对流处理和批处理采取统一的处理方式,无论配置何种执行模式,在有界输入上执行的 DataStream 应用都会产生相同的最终结果;在流模式执行的作业可能会产生增量更新(类似于数据库中的插入(upsert)操作),而批作业只在最后产生一个最终结果;
4.通过启用批执行模式,Flink 可以对有边界作业进行额外的优化:可以使用不同的关联(join)/ 聚合(aggregation)策略、不同 shuffle 实现来提高任务调度和故障恢复的效率等;
5.批执行模式只能用于有边界的作业/Flink 程序:
6.边界:是数据源的一个属性,表明是否在执行之前已经知道来自该数据源的所有输入,或者新数据是否会无限期地出现;如果作业的所有源都是有边界的,则它就是有边界的,否则就是无边界的;
流执行模式,既可用于有边界任务,也可用于无边界任务;
批执行模式,只用于有边界任务;
7.使用流模式运行有边界作业:
- 使用有边界作业的运行结果去初始化作业状态,并将该状态在之后的无边界作业中使用;例如,通过`流`模式运行一个有边界作业,获取一个 savepoint,然后在一个无边界作业上恢复这个 savepoint【将 savepoint 作为 `批` 执行作业的附加输出】;
- 为无边界数据源写测试代码时,使用有边界数据源更自然。
8.配置批执行模式
执行模式可以通过 execution.runtime-mode 配置,可选值如下:
- STREAMING: 经典 DataStream 执行模式(默认)
- BATCH: 在 DataStream API 上进行批量式执行
- AUTOMATIC: 让系统根据数据源的边界性来决定
可以通过 bin/flink run ... 的命令行参数配置,或者在创建/配置 StreamExecutionEnvironment 时写进程序;
注意:不建议在程序中设置运行模式,而是在提交应用程序时使用命令行设置,保持应用程序代码的免配置可以让程序更加灵活,因为同一个应用程序可能在任何执行模式下执行;
9.执行行为-任务调度与网络 Shuffle
9.1在流执行模式下,所有任务需要持续运行;Flink可以通过整个管道立即处理新的记录,以达到需要的连续和低延迟的流处理;同时分配给某个作业的 TaskManagers 需要有足够的资源来同时运行所有的任务;
网络 shuffle 是流水线式的,记录会立即发送给下游任务,在网络层上进行一些缓冲;当处理连续的数据流时,在任务(或任务管道)之间没有可以实体化的自然数据点(时间点),而在批执行模式下,中间的结果可以被实体化;
9.2在批执行模式下,作业的任务可以分阶段执行;因为输入是有边界的,因此 Flink 可以在进入下一个阶段之前完全处理管道中的一个阶段;在上面的例子中,工作会有三个阶段,对应着被 shuffle 界线分开的三个任务;
分阶段处理要求 Flink 将任务的中间结果实体化到非永久存储中,让下游任务在上游任务下线后再读取,将增加处理的延迟,但这允许 Flink 在故障发生时回溯到最新的可用结果,而不是重新启动整个任务;同时批作业可以在更少的资源上执行;
在批执行模式中,因为输入数据是有边界的,Flink 可以使用更高效的数据结构和算法来进行任务调度和网络 shuffle;
TaskManagers 将至少在下游任务开始消费前保留中间结果,在这之后,只要空间允许,中间结果就会被保留,以便任务失败回滚;
10.执行行为-State Backends/State
在流模式下,Flink 使用 StateBackend 控制状态的存储方式和检查点的工作方式;
在批模式下,配置的 state backend 被忽略;对输入按 key 分组(使用排序),依次处理一个 key 的所有记录,以便在同一时间只保留一个 key 的状态,当进行到下一个 key 时,上一个 key 的状态将被丢弃;
11.执行行为-处理顺序
在批执行和流执行中,算子或用户自定义函数(UDF)处理记录的顺序可能不同:
在流模式下,对于用户自定义函数,数据一到达就被处理;
在批模式下,Flink 确保数据有序,排序可以是特定调度任务、网络 shuffle、上文提到的 state backend 等;
将常见输入类型分为三类:
- 广播输入(broadcast input): 从广播流输入【广播状态】;
- 常规输入(regular input): 既不从广播输入或也不从 keyed 输入;
- keyed 输入(keyed input): 从 KeyedStream 输入;
消费多种类型输入的函数或算子,处理顺序如下:
- 广播输入第一个处理
- 常规输入第二个处理
- keyed 输入最后处理
对于从多个常规或广播输入进行消费的函数 — 比如 CoProcessFunction — Flink 有权从任一输入以任意顺序处理数据;
对于从多个keyed输入进行消费的函数 — 比如 KeyedCoProcessFunction — Flink 先处理单一键中的所有记录再处理下一个;
12.执行行为-事件时间/水印
在流模式下,存在数据乱序的可能,使用 Watermark(一个带有时间戳 T 的水印)标志再没有时间戳 t < T 的元素跟进;
在批模式下,输入的数据集是事先已知的,至少可以按照时间戳对元素进行排序,从而按照时间顺序进行处理,不存在数据乱序的可能;
综上:在批模式下,只需要在输入的末尾有一个与每个键相关的 MAX_WATERMARK,如果输入流没有键,则在输入的末尾需要一个 MAX_WATERMARK;所有注册的定时器都会在时间结束时触发,用户定义的 WatermarkAssigners 或 WatermarkStrategies 会被忽略;但配置 WatermarkStrategy 是有用的,因为它的 TimestampAssigner 仍然会被用来给记录分配时间戳;
13.执行行为-处理时间
处理时间是指在处理记录的具体实例上,处理记录的机器上的时钟时间,基于处理时间的计算结果是不可重复的,因为同一条记录被处理两次,会有两个不同的时间戳;
在流模式下,事件时间和处理时间存在相关性;在流模式下事件时间的1小时也几乎是处理时间的1小时,使用处理时间可以用于早期(不完全)触发,给出预期结果的提示;
在批模式下,事件时间和处理时间相关性不存在,因为输入的数据集是静态的;允许用户请求当前的处理时间,并注册处理时间定时器,但与事件时间的情况一样,所有的定时器都要在输入结束时触发。
在作业执行过程中,处理时间不会提前,当整个输入处理完毕后,会快进到时间结束;
14.执行行为-故障恢复
在流模式下,Flink 使用 checkpoint 进行故障恢复,在发生故障时,Flink 会从 checkpoint 重新启动所有正在运行的任务;
在批模式下,Flink 会尝试回溯到之前的中间结果仍可获取的处理阶段,只有失败的任务才需要重新启动,相比从 checkpoint 重新启动所有任务,可以提高作业的处理效率和整体处理时间;
15.批模式下的行为变化
- 滚动操作,如 reduce() 或 sum(),会对流模式下每一条新记录发出增量更新,在批模式下,只发出最终结果;
16.批模式下不支持
- Checkpointing 和任何依赖于 checkpointing 的操作都不支持;
17.批处理程序的故障恢复不使用检查点,因为没有 checkpoints,某些功能如 CheckpointListener ,以及因此,Kafka 的精确一次(EXACTLY_ONCE) 模式或 File Sink 的 OnCheckpointRollingPolicy 将无法工作;
18.仍然可以使用所有的状态原语(state primitives),只是用于故障恢复的机制会有所不同;
19.在流模式下运行良好的 Operator 可能会在批模式下产生错误的结果:
- 在批模式下,会逐个 key 处理记录;因此,Watermark 会在每个 key 之间从 MAX_VALUE 切换到 MIN_VALUE;
- Watermark 在一个算子中不总是递增的;
- 定时器将首先按 key 的顺序触发,然后按每个 key 内的时间戳顺序触发;
- 不支持手动更改 key 的操作;
3、事件时间
1)生成 Watermark
1.总结
1.为了使用事件时间语义,Flink 应用程序需要知道事件时间戳对应的字段,即数据流中的每个元素都需要拥有可分配的事件时间戳;
2.可以通过使用 TimestampAssigner API 从元素中的某个字段去访问/提取时间戳;
3.时间戳的分配与 watermark 的生成是齐头并进的,表明 Flink 应用程序事件时间的进度,可以通过指定 WatermarkGenerator 来配置 watermark 的生成方式;
4.使用 Flink API 时需要设置一个同时包含 TimestampAssigner 和 WatermarkGenerator 的 WatermarkStrategy,WatermarkStrategy 工具类中也提供了许多常用的 watermark 策略,用户也可以自定义 watermark 策略;
5.可以使用 WatermarkStrategy 工具类中通用的 watermark 策略,或者使用这个工具类将自定义的 TimestampAssigner 与 WatermarkGenerator 进行绑定;
6. 时间戳和 watermark 都是从 1970-01-01T00:00:00Z 起的 Java 纪元开始,并以毫秒为单位;
7.WatermarkStrategy 可以在 Flink 应用程序中的两处使用,第一种是在数据源上使用,第二种是在非数据源的操作之后使用;
第一种方式更好,因为数据源可以利用 watermark 生成逻辑中有关分片/分区(shards/partitions/splits)的信息,数据源可以更精准地跟踪 watermark,整体 watermark 生成将更精确;直接在源上指定 WatermarkStrategy 意味着必须使用特定数据源接口,例如 KafkaSource;
仅当无法直接在数据源上设置策略时,才应该使用第二种方式(在任意转换操作之后设置 WatermarkStrategy);
8.使用 WatermarkStrategy 去获取流并生成带有时间戳的元素和 watermark 的新流时,如果原始流已经具有时间戳或 watermark,则新指定的时间戳分配器将覆盖原有的时间戳和 watermark;
9.如果数据源中的某一个分区/分片在一段时间内未发送事件数据,则意味着 WatermarkGenerator 也不会获得任何新数据去生成 watermark,称这类数据源为空闲输入或空闲源;
10.可以使用 WatermarkStrategy 来检测空闲输入并将其标记为空闲状态,WatermarkStrategy.withIdleness;
11.某些 splits/partitions/shards 或 source 可能会非常快地处理记录,从而使其 Watermark 的增加速度相对较快,对于使用 Watermark 处理数据的下游 Operator 来说,下游 Operator(如Window Join)的水印可以正常进行,但是 Operator 需要缓冲来自快速输入的过多数据量,因为来自其所有输入的最小 Watermark 被滞后;
12.由快速输入发出的所有记录都必须在下游 Operator 的状态中进行缓冲,这可能导致 Operator 状态的不可控增长,可以启用 Watermark 对齐,确保没有 splits/partitions/shards 或 source 将其 Watermark 增加得比其它源多太多,可以分别为每个源启用对齐,WatermarkStrategy.withWatermarkAlignment("alignment-group-1", Duration.ofSeconds(20), Duration.ofSeconds(1));
当启用 Watermark 对齐时,需要告诉 Flink,source 应属于哪个组,通过提供一个标签(例如alignment-group-1)来实现,该标签将共享它的所有 source 绑定在一起;
此外,必须告诉属于该组的所有 source 的当前最小水印的最大漂移,第三个参数描述了当前最大水印应该多久更新一次,频繁更新的缺点是在TM和JM之间会有更多的RPC消息传输;
13.只有 FLIP-27 的 source 可以启用水印对齐,它不适用于历史版本,不适用于在数据源之后应用 assignTimestampsAndWatermarks;
14.为了实现对齐,Flink 将暂停从源/任务进行消费,它将继续读取其他来源/任务的记录,这些来源/任务可以向前移动组合水印,从而解锁更快的水印;
15.从 Flink 1.17 开始,FLIP-27 源框架支持拆分级别的水印对齐,源连接器实现一个接口来恢复和暂停拆分,以便在同一任务中对齐splits/partitions/shards;
16.如果从 1.15.x 和 1.16.x(含1.15.x)之间的 Flink 版本升级,通过将 pipeline.watermark-alignment.allow-unaligned-source-splits 设置为 true 来禁用拆分级别对齐;
17.当将标志设置为 true 时,只有当 splits/partitions/shards 的数量等于源运算符的并行度时,水印对齐才能正常工作,这导致每个子任务都被分配一个工作单元;另一方面,如果有两个 Kafka 分区,它们以不同的速度生成水印,并被分配给同一个任务,那么水印可能不会像预期的那样工作;但即使在最坏的情况下,基本对齐的性能也不会比根本没有对齐差;
18.Flink 支持在相同来源和不同来源的任务之间进行对齐,当有两个不同的来源(例如 Kafka 和 File )以不同的速度生成水印时,这很有用;
19.WatermarkGenerator#onEvent:每来一条事件数据调用一次,可以检查或者记录事件的时间戳,也可以基于事件数据本身生成 watermark;
20.WatermarkGenerator#onPeriodicEmit:周期性的调用,可能会生成新的 watermark,调用此方法生成 watermark 的间隔时间由 ExecutionConfig#getAutoWatermarkInterval 决定;
21.watermark 的生成方式本质上有两种:周期性生成和标记生成;
周期性生成器通过 onEvent() 观察传入的事件数据,然后在框架调用 onPeriodicEmit() 时发出 watermark;
标记生成器将查看 onEvent() 中的事件数据,并检查在流中携带 watermark 的特殊标记事件或打点数据,当获取到这些事件数据时,它将立即发出 watermark,通常标记生成器不会通过 onPeriodicEmit() 发出 watermark;
22.周期性生成器会观察流事件数据并定期生成 watermark(其生成可能取决于流数据,或者完全基于处理时间);
23.生成 watermark 的时间间隔(每 n 毫秒)可以通过 ExecutionConfig.setAutoWatermarkInterval(...) 指定;每次都会调用生成器的 onPeriodicEmit() 方法,如果返回的 watermark 非空且值大于前一个 watermark,则将发出新的 watermark;
24.标记 watermark 生成器观察流事件数据并在获取到带有 watermark 信息的特殊事件元素时发出 watermark;
25.可以针对每个事件生成 watermark,但每个 watermark 都会在下游做一些计算,因此过多的 watermark 会降低程序性能;
26.可以使用 Flink 中可识别 Kafka 分区的 watermark 生成机制;将在 Kafka 消费端内部针对每个 Kafka 分区生成 watermark,并且不同分区 watermark 的合并方式与在数据流 shuffle 时的合并方式相;
27.在将 watermark 转发到下游之前,需要算子对其进行触发的事件完全进行处理;即由于此 watermark 的出现而产生的所有数据元素都将在此 watermark 之前发出;
28.相同的规则也适用于 TwoInputStreamOperator;此时算子当前的 watermark 会取其两个输入的最小值;
29.WatermarkStrategy 包含 TimestampAssigner 和 WatermarkGenerator;
2)内置 Watermark 生成器
1.总结
1.单调递增时间戳分配器:周期性 watermark 生成方式最简单的特例就是给定的数据源中数据的时间戳升序出现;此时当前时间戳就可以充当 watermark,因为后续到达数据的时间戳不会比当前的小;
WatermarkStrategy.forMonotonousTimestamps();
在 Flink 应用程序中,如果是并行数据源,则只要求并行数据源中的每个单分区数据源任务时间戳递增;
Flink 的 watermark 合并机制会在并行数据流进行分发(shuffle)、联合(union)、连接(connect)或合并(merge)时生成正确的 watermark;
2.数据之间存在最大固定延迟的时间戳分配器:当 watermark 滞后于数据流中最大(事件时间)时间戳一个固定的时间量;即预先知道数据流中的数据可能遇到的最大延迟;
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10));
Flink 针对上述场景提供了 boundedOutfordernessWatermarks 生成器,该生成器将 maxOutOfOrderness 作为参数,该参数代表在计算给定窗口的结果时,允许元素被忽略计算之前延迟到达的最长时间;
其中延迟时长就等于 t - t_w,其中 t 代表元素的(事件时间)时间戳,t_w 代表前一个 watermark 对应的(事件时间)时间戳;如果 lateness > 0,则认为该元素迟到了,并且在计算相应窗口的结果时默认会被忽略;
3.WithIdleness(处理时间):针对某个数据源无数据有效;针对单个数据源某个分区无数据也有效;
4.是否在生成水位线和分配时间戳之前进行 keyby,对于水位线的生成会有影响(导致数据被分配的 subtask 不同),要考虑是否配置空闲数据源;
5.水位线的计算:
单数据源单分区:当前的(eventtime-1)ms;
单数据源多分区:以最小分区的 watermark 为主;
多数据源单分区\多分区:以两个数据源间最小分区的 watermark 为主;
4、用户自定义 Functions
1)用户自定义函数
1.总结
1、创建用户自定义函数的方式【实现接口(implements MapFunction<I,O>)、匿名类(new MapFunction<I,O> (){})、Lambdas 表达式、继承 Rich functions(extends RichMapFunction<I,O>)】;
2)累加器 和 计数器
1.总结
1、累加器是具有【加法运算】和【最终累加结果】的一种简单结构,可在作业结束后使用;
2、在作业结束时,Flink 会汇总(合并)所有部分的结果并将其发送给客户端,Flink 目前有如下内置累加器,每个都实现了累加器接口:
IntCounter,LongCounter 和 DoubleCounter;
Histogram(直方图):离散数量的柱状直方图实现【在内部,它只是整形到整形的映射,可以用它来计算值的分布】;
3、单个作业的所有累加器共享一个命名空间,可以在不同的操作 function 里面使用同一个累加器;Flink 会在内部将所有具有相同名称的累加器合并起来;
4、自定义累加器只需要实现累加器接口,可以选择实现 Accumulator 或 SimpleAccumulator:
Accumulator:定义了将要添加的值类型 V,并定义了最终的结果类型 R;
SimpleAccumulator:适用于两种类型都相同的情况;
5、通过调用 execute() 方法返回的 JobExecutionResult 对象获得累加器结果(只有等待作业完成后执行才起作用);
5、状态与容错
1)使用状态
1.总结
1.使用 keyed state,首先需要为 DataStream 指定 key(主键);这个 key 用于状态分区(数据流中的 Record 也会被分区);可以使用 DataStream 中 Java API 的 keyBy(KeySelector) 来指定 key,将生成 KeyedStream;
2.Key selector 函数接收单条 Record 作为输入,返回这条记录的 key,该 key 可以为任何类型,但是它的计算产生方式必须具备确定性,Flink 的数据模型不基于 key-value 对,将数据集在物理上封装成 key 和 value 是没有必要的,Key 是“虚拟”的,用以操纵分组算子;
3.可以通过 tuple 字段索引,或者选取对象字段的表达式来指定 key 即 Tuple Keys 和 Expression Keys;
4.keyed state 接口提供不同类型状态的访问接口,这些状态都作用于当前输入数据的 key 下,即这些状态仅可在 KeyedStream 上使用,支持的状态类型如下:
- ValueState: 保存一个可以更新和检索的值(每个值都对应到当前的输入数据的 key,因此算子接收到的每个 key 都可能对应一个值)这个值可以通过 update(T) 进行更新,通过 T value() 进行检索;
- ListState: 保存一个元素的列表,可以往这个列表中追加数据,并在当前的列表上进行检索,通过 add(T) 或者 addAll(List) 添加元素,通过 Iterable get() 获得整个列表,还可以通过 update(List) 覆盖当前的列表;
- ReducingState: 保存一个单值,表示添加到状态的所有值的聚合,使用 add(T) 增加的元素会用提供的 ReduceFunction 进行聚合;
- AggregatingState: 保留一个单值,表示添加到状态的所有值的聚合,和 ReducingState 相反的是,聚合类型可能与添加到状态的元素的类型不同,使用 add(IN) 添加的元素会用指定的 AggregateFunction 进行聚合;
- MapState: 维护了一个映射列表,可以添加键值对到状态中,也可以获得反映当前所有映射的迭代器,使用 put(UK,UV) 或者 putAll(Map) 添加映射,使用 get(UK) 检索特定 key,使用 entries(),keys() 和 values() 分别检索映射、键和值的可迭代视图,还可以通过 isEmpty() 来判断是否包含任何键值对;
5.所有类型的状态都有一个 clear() 方法,清除当前 key 下的状态数据;
6.状态对象仅用于与状态交互,状态本身不一定存储在内存中,还可能在磁盘或其他位置;从状态中获取的值取决于输入元素所代表的 key,在不同 key 上调用同一个接口,可能得到不同的值;
7.状态通过 RuntimeContext 进行访问,只能在 rich functions 中使用;
8.任何类型的 keyed state 都可以有有效期 (TTL),如果配置了 TTL 且状态值已过期,则会尽最大可能清除对应的值,所有状态类型都支持单元素的 TTL,列表元素和映射元素将独立到期;
9.在使用状态 TTL 前,需要先构建一个 StateTtlConfig 配置对象,然后把配置传递到 state descriptor 中启用 TTL 功能;
10.TTL 的更新策略(默认是 OnCreateAndWrite):
- StateTtlConfig.UpdateType.OnCreateAndWrite - 仅在创建和写入时更新
- StateTtlConfig.UpdateType.OnReadAndWrite - 读取时也更新
11.数据在过期但还未被清理时的可见性配置如下(默认为 NeverReturnExpired):
- StateTtlConfig.StateVisibility.NeverReturnExpired - 不返回过期数据
- StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp - 会返回过期但未清理的数据
NeverReturnExpired 情况下,过期数据就像不存在一样,不管是否被物理删除,这对于不能访问过期数据的场景下非常有用,比如敏感数据, ReturnExpiredIfNotCleanedUp 在数据被物理删除前都会返回;
注意:
- 状态上次的修改时间会和数据一起保存在 state backend 中,开启该特性会增加状态数据的存储;Heap state backend 会额外存储一个包括用户状态以及时间戳的 Java 对象,RocksDB state backend 会在每个状态值(list 或者 map 的每个元素)序列化后增加 8 个字节;
- 暂时只支持基于 processing time 的 TTL;
- 尝试从 checkpoint/savepoint 进行恢复时,TTL 的状态(是否开启)必须和之前保持一致,否则会遇到 “StateMigrationException”;
- TTL 的配置并不会保存在 checkpoint/savepoint 中,仅对当前 Job 有效;
- 不建议 checkpoint 恢复前后将 state TTL 从短调长,这可能会产生潜在的数据错误;
- 当前开启 TTL 的 map state 仅在用户值序列化器支持 null 的情况下,才支持用户值为 null;如果用户值序列化器不支持 null,可以用 NullableSerializer 包装一层;
- 启用 TTL 配置后,StateDescriptor 中的 defaultValue(已标记 deprecated)将会失效,在此基础上,用户需要手动管理那些实际值为 null 或已过期的状态默认值;
12.默认情况下,过期数据会在读取的时候被删除,例如 ValueState#value,会有后台线程定期清理(需要 StateBackend 支持)可以通过 StateTtlConfig 配置关闭后台清理.disableCleanupInBackground();
13.当前的实现中 HeapStateBackend 依赖增量数据清理,RocksDBStateBackend 利用压缩过滤器进行后台清理;
14.可以启用全量快照时进行清理的策略,可以减少整个快照的大小,当前实现中不会清理本地的状态,但从上次快照恢复时,不会恢复那些已经删除的过期数据,该策略可以通过 StateTtlConfig 进行配置.cleanupFullSnapshot(),该策略在 RocksDBStateBackend 的增量 checkpoint 模式下无效;这种清理方式可以在任何时候通过 StateTtlConfig 启用或者关闭,比如在从 savepoint 恢复时;
15.可以选择增量式清理状态数据,在状态访问或/和处理时进行,如果某个状态开启了该清理策略,则会在存储后端保留一个所有状态的惰性全局迭代器,每次触发增量清理时,从迭代器中选择已经过期的数进行清理;
该策略有两个参数:
- 第一个参数表示每次清理时检查状态的条目数,在每个状态访问时触发;
- 第二个参数表示是否在处理每条记录时触发清理,Heap backend 默认会检查 5 条状态,并且关闭在每条记录时触发清理;
注意:
- 如果没有 state 访问,也没有处理数据,则不会清理过期数据;
- 增量清理会增加数据处理的耗时;
- 现在仅 Heap state backend 支持增量清除机制,在 RocksDB state backend 上启用该特性无效;
- 如果 Heap state backend 使用同步快照方式,则会保存一份所有 key 的拷贝,从而防止并发修改问题,因此会增加内存的使用,但异步快照则没有这个问题;
- 对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,比如从 savepoint 重启后;
16.如果使用 RocksDB state backend,则会启用 Flink 为 RocksDB 定制的压缩过滤器,RocksDB 会周期性的对数据进行合并压缩从而减少存储空间,Flink 提供的 RocksDB 压缩过滤器会在压缩时过滤掉已经过期的状态数据;
17.Flink 处理一定条数的状态数据后,会使用当前时间戳来检测 RocksDB 中的状态是否已经过期,可以通过 StateTtlConfig.newBuilder(...).cleanupInRocksdbCompactFilter(long queryTimeAfterNumEntries) 方法指定处理状态的条数;时间戳更新的越频繁,状态的清理越及时,但由于压缩会有调用 JNI 的开销,因此会影响整体的压缩性能;RocksDB backend 的默认后台清理策略会每处理 1000 条数据进行一次;
18.定期压缩可以加速过期状态条目的清理,特别是对于很少访问的状态条目,比这个值早的文件将被选取进行压缩,并重新写入与之前相同的 Level 中,该功能可以确保文件定期通过压缩过滤器压缩,可以通过 StateTtlConfig.newBuilder(...).cleanupInRocksdbCompactFilter(long queryTimeAfterNumEntries, Duration periodicCompactionTime) 方法设定定期压缩的时间,定期压缩的时间的默认值是 30 天,可以将其设置为 0 以关闭定期压缩或设置一个较小的值以加速过期状态条目的清理,但它将会触发更多压缩;
19.可以通过配置开启 RocksDB 过滤器的 debug 日志:log4j.logger.org.rocksdb.FlinkCompactionFilter=DEBUG;
注意:
- 压缩时调用 TTL 过滤器会降低速度,TTL 过滤器需要解析上次访问的时间戳,并对每个将参与压缩的状态进行是否过期检查,对于集合型状态类型(比如 list 和 map),会对集合中每个元素进行检查;
- 对于元素序列化后长度不固定的列表状态,TTL 过滤器需要在每次 JNI 调用过程中,额外调用 Flink 的 java 序列化器, 从而确定下一个未过期数据的位置;
- 对已有的作业,这个清理方式可以在任何时候通过 StateTtlConfig 启用或禁用该特性,比如从 savepoint 重启后;
- 定期压缩功能只在 TTL 启用时生效;
20.算子状态(或者非 keyed 状态)是绑定到一个并行算子实例的状态,Kafka consumer 每个并行实例维护了 topic partitions 和偏移量的 map 作为它的算子状态;
21.当并行度改变的时候,算子状态支持将状态重新分发给各并行算子实例,处理重分发过程有多种不同的方案;
22.算子状态作为一种特殊类型的状态使用,用于实现 source/sink,以及无法对 state 进行分区而没有主键的这类场景中;
23.广播状态是一种特殊的算子状态,支持将一个流中的元素需要广播到所有下游任务的使用情形,广播状态用于保持所有子任务状态相同;
24.广播状态和其他算子状态的区别:
- 它具有 map 格式;
- 它仅在一些特殊的算子中可用,这些算子的输入为一个广播数据流和非广播数据流;
- 这类算子可以拥有不同命名的多个广播状态;
25.用户可以通过实现 CheckpointedFunction 接口来使用 operator state;
26.进行 checkpoint 时会调用 snapshotState(),自定义函数初始化时会调用 initializeState(),初始化包括第一次自定义函数初始化和从之前的 checkpoint 恢复;因此 initializeState() 不仅是定义不同状态类型初始化的地方,也需要包括状态恢复的逻辑;
27.当前 operator state 以 list 的形式存在;这些状态是一个可序列化对象的集合 List,彼此独立,方便在改变并发后进行状态的重新分派,根据状态的不同访问方式,有如下几种重新分配的模式:
- Even-split redistribution: 每个算子都保存一个列表形式的状态集合,整个状态由所有的列表拼接而成;当作业恢复或重新分配的时候,整个状态会按照算子的并发度进行均匀分配;比如说,算子 A 的并发度为 1,包含两个元素 element1 和 element2,当并发度增加为 2 时,element1 会被分到并发 0 上,element2 则会被分到并发 1 上;
- Union redistribution: 每个算子保存一个列表形式的状态集合;整个状态由所有的列表拼接而成;当作业恢复或重新分配时,每个算子都将获得所有的状态数据【不建议使用】;
28.调用不同的获取状态对象的接口,会使用不同的状态分配算法,比如 getUnionListState(descriptor) 会使用 union redistribution 算法,而 getListState(descriptor) 则使用 even-split redistribution 算法;
29.当初始化状态对象后,通过 isRestored() 方法判断是否从之前的故障中恢复,如果该方法返回 true 则表示从故障中进行恢复;
30.要获取 checkpoint 成功消息的算子,可以参考 org.apache.flink.api.common.state.CheckpointListener 接口,当算子完成 checkpoint 后会回调 notifyCheckpointComplete() 方法;
2)广播状态
1.总结
1.为关联一个非广播流(keyed 或者 non-keyed)与一个广播流(BroadcastStream),可以调用非广播流的方法 connect(),并将 BroadcastStream 当做参数传入;这个方法的返回参数是 BroadcastConnectedStream,具有 process() 方法,可以传入一个特殊的 CoProcessFunction 来编辑模式识别逻辑,具体传入 process() 的是哪个类型取决于非广播流的类型:
- 如果流是一个 keyed 流,那就是 KeyedBroadcastProcessFunction 类型;
- 如果流是一个 non-keyed 流,那就是 BroadcastProcessFunction 类型;
2.在传入的 BroadcastProcessFunction 或 KeyedBroadcastProcessFunction 中,需要实现两个方法;processBroadcastElement() 负责处理广播流中的元素,processElement() 负责处理非广播流中的元素;
3.在 getBroadcastState() 方法中传入的 stateDescriptor 应该与调用 .broadcast(ruleStateDescriptor) 的参数相同;
4.对于 broadcast state 的访问权限,在处理广播流元素这端,是具有读写权限的,而对于处理非广播流元素这端是只读的;因为 Flink 中是不存在跨 task 通讯的,为了保证 broadcast state 在所有的并发实例中是一致的,在处理广播流元素的时候给予写权限,在所有的 task 中均可以看到这些元素,并且要求对这些元素处理是一致的,那么最终所有 task 得到的 broadcast state 是一致的;
5.processBroadcastElement() 的实现必须在所有的并发实例中具有确定性的结果;
6.KeyedBroadcastProcessFunction 在 Keyed Stream 上工作,提供了一些 BroadcastProcessFunction 没有的功能:
processElement() 的参数 ReadOnlyContext 提供了方法访问 Flink 的定时器服务,可以注册事件时间定时器(event-time timer)或处理时间定时器(processing-time timer);当定时器触发时,会调用 onTimer() 方法,提供了 OnTimerContext,它具有 ReadOnlyContext 的全部功能,并且提供:
- 查询当前触发的是一个事件时间还是处理时间的定时器
- 查询定时器关联的key
processBroadcastElement() 方法中的参数 Context 会提供方法 applyToKeyedState(StateDescriptor stateDescriptor, KeyedStateFunction function);这个方法使用一个 KeyedStateFunction 能够对 stateDescriptor 对应的 state 中所有 key 的存储状态进行操作;
7.注册定时器只能在 KeyedBroadcastProcessFunction 的 processElement() 方法中进行,在 processBroadcastElement() 方法中不能注册定时器,因为广播的元素中并没有关联的 key;
8.broadcast state 在不同的 task 的事件顺序可能是不同的,虽然广播流中元素的过程能够保证所有的下游 task 全部能够收到,但在不同 task 中元素的到达顺序可能不同,所以 broadcast state 的更新不能依赖于流中元素到达的顺序;
9.虽然所有 task 中的 broadcast state 是一致的,但当 checkpoint 来临时,所有 task 均会对 broadcast state 做 checkpoint;防止在作业恢复后读文件造成的文件热点;Flink 会保证在恢复状态/改变并发的时候数据没有重复且没有缺失;在作业恢复时,如果与之前具有相同或更小的并发度,所有的 task 读取之前已经 checkpoint 过的 state,在增大并发的情况下,task 会读取本身的 state,多出来的并发(p_new - p_old)会使用轮询调度算法读取之前 task 的 state;
10.不使用 RocksDB state backend,broadcast state 在运行时保存在内存中,需保证内存充足,同样适用于其它 Operator State;
3)Checkpointing
1.总结
1.Flink 中的每个方法或算子都能够是有状态的,状态化的方法在处理单个元素/事件的时候存储数据,为了让状态容错,Flink 需要为状态添加 checkpoint(检查点);
2.默认 checkpoint 是禁用的,通过调用 StreamExecutionEnvironment 的 enableCheckpointing(n) 来启用 checkpoint,里面的 n 是进行 checkpoint 的间隔,单位毫秒;
3.checkpoint 其它属性包括【checkpoint 存储\精确一次(exactly-once)和至少一次(at-least-once)\checkpoint 超时\checkpoints 之间的最小时间\checkpoint 可容忍连续失败次数\并发 checkpoint 的数目\externalized checkpoints\非对齐 checkpoints\部分任务结束的 checkpoints】;
4.Flink 的 checkpointing 机制会将 timer 以及 stateful 的 operator 进行快照,然后存储下来,包括连接器(connectors),窗口(windows)以及用户自定义的状态;
5.Checkpoint 存储在哪里取决于配置的 State Backend(比如 JobManager memory、 file system、 database),默认情况下,状态是保存在 TaskManagers 的内存中,checkpoint 保存在 JobManager 的内存中;为了持久化大体量状态, Flink 支持存储 checkpoint 状态到其他的 state backends 上;
6.Flink 现在为没有迭代(iterations)的作业提供一致性的处理保证,在迭代作业上开启 checkpoint 会导致异常,为了在迭代程序中强制进行 checkpoint,用户需要在开启 checkpoint 时设置一个特殊的标志:env.enableCheckpointing(interval, CheckpointingMode.EXACTLY_ONCE, force = true),注意在环形边上游走的记录(以及与之相关的状态变化)在故障时会丢失;
7.从 1.14 版本开始 Flink 支持在部分任务结束后继续进行 Checkpoint,如果一部分数据源是有限数据集,那么就可以,从 1.15 版本开始,这一特性被默认打开;如果想要关闭这一功能,可以执行 config.set(ExecutionCheckpointingOptions.ENABLE_CHECKPOINTS_AFTER_TASKS_FINISH, false); 此时,结束的任务不会参与 Checkpoint 的过程,在实现自定义的算子或者 UDF(用户自定义函数)时需要考虑这一点;
8.在部分 Task 结束后的 checkpoint 中,Flink 对 UnionListState 进行了特殊的处理,UnionListState 一般用于实现对外部系统读取位置的一个全局视图(例如记录所有 Kafka 分区的读取偏移);
如果在算子的某个并发调用 close() 方法后丢弃它的状态,就会丢失它所分配的分区的偏移量信息,为了解决这一问题,对于使用 UnionListState 的算子,只允许在它的并发都在运行或都已结束的时候才能进行 checkpoint 操作;
9.ListState 一般不会用于类似的场景,仍然需要注意在调用 close() 方法后进行的 checkpoint 会丢弃算子的状态并且这些状态在算子重启后不可用;
任何支持并发修改操作的算子也可以支持部分并发实例结束后的恢复操作,从这种类型的快照中恢复等价于将算子的并发改为正在运行的并发实例数。
10.为了保证使用两阶段提交的算子可以提交所有的数据,任务会在所有算子都调用 finish() 方法后等待下一次 checkpoint 成功后退出;
这一行为可能会延长任务运行的时间,如果 checkpoint 周期比较大,这一延迟会非常明显,极端情况下,如果 checkpoint 的周期被设置为 Long.MAX_VALUE,那么任务永远不会结束,因为下一次 checkpoint 不会进行;
4)State Backends
1.总结
1.Flink 提供了多种 state backends,它用于指定状态的存储方式和位置;
2.为了让应用程序可以维护非常大的状态,Flink 可以自己管理内存(如果有必要可以溢写到磁盘);
3.默认情况下,所有 Flink Job 会使用 Flink 配置文件中指定的 state backend,但配置文件中指定的 state backend 会被 Job 中指定的 state backend 覆盖;
5)数据类型及序列化
1.总结
1.Flink 以其独特的方式来处理数据类型及序列化,包括它自身的类型描述符、泛型类型提取以及类型序列化框架,支持的数据类型:
Java Tuples and Scala Case Classes
Java POJOs
Primitive Types
Regular Classes
Values
Hadoop Writables
Special Types
2.Tuples and Case Classes:元组是包含固定数量的具有各种类型的字段的复合类型,Java API 提供从 Tuple1 到 Tuple25 的类,元组的每个字段都可以是任意的 Flink 类型,包括元组,从而产生嵌套的元组;
元组的字段可以使用字段名称 tuple.f4 直接访问,也可以使用通用的 getter 方法 tuple.getField(int位置) 字段索引从0开始;
3.POJOs:如果 Java 和 Scala 类满足以下要求,Flink 会将它们视为特殊的 POJO 数据类型:
- 类必须是公开的
- 它必须有一个不带参数的公共构造函数(默认构造函数)
- 所有字段要么是公共的,要么必须可以通过 getter 和 setter 函数访问;对于名为 foo 的字段,getter 和 setter 方法必须命名为 getFoo() 和 setFoo()
- 字段的类型必须被已注册的序列化器支持
POJO 通常用 PojoTypeInfo 表示,并用 PojoSerializer 进行序列化(可以配置回退使用 Kryo 序列化器);除了 POJO 是 Avro 类型(Avro 特定记录)或作为 “Avro 反射类型” ,此时 POJO 由 AvroTypeInfo 表示,并使用 AvroSerializer 进行序列化;如果需要,还可以注册自定义的序列化程序;
可以通过 org.apache.flink.types.PojoTestUtils#assertSerializedAsPojo() 测试【类是否符合 POJO 要求】,如果想确保 POJO 的任何字段都不会使用 Kryo 进行序列化,可以使用 assertSerializedAsPojoWithoutKryo;
4.Primitive Types:Flink 支持所有 Java 和 Scala 基本类型,如 Integer、String 和 Double;
5.General Class Types:Flink 支持大多数 Java 和 Scala 类(API和自定义),对于包含无法序列化字段的类,如文件指针、I/O流或其它本机资源,会受限制;遵循 JavaBeans 约定的类可以正常使用;
Flink 将所有未标识为 POJO 类型的类,作为通用类的类型进行处理,Flink 将这些数据类型视为黑匣子,无法访问其内容;一般类型使用序列化框架 Kryo 进行序列化和反序列化;
6.Values:值类型需要手动描述它们的序列化和反序列化器,它们不是通过通用的序列化框架,而是通过实现 org.apache.flink.type 自定义读取和写入的方法;
当通用序列化器效率很低时,使用 Value 类型是合理的;示例将元素的稀疏向量用数组实现,其中数组元素大部分为零,就可以对非零元素使用特殊编码,而通用序列化器只需写入所有数组元素;
Flink 提供了与基本数据类型相对应的预定义值类型(ByteValue、ShortValue、IntValue、LongValue、FloatValue、DoubleValue、StringValue、CharValue、BooleanValue)这些值类型充当基本数据类型的变体,它们的值可以更改,允许重用对象并减轻 GC 的压力;
7.Hadoop Writables:使用实现了 org.apache.hadoop 接口的类型,使用 write() 和 readFields() 方法定义序列化和反序列化逻辑;
8.Special Types:特殊的类型,包括 Scala 的 Either,Option 和 Try;Java API 有 Either 的自定义实现,表示两种可能类型的值;
9.类型擦除:Java 编译器在编译后会丢弃许多泛型的类型信息,因此在运行时,对象的实例不再知道其泛型类型,例如 DataStream<String> 和 DataStream<Long> 的实例在 JVM 中看起来是相同的;
10.Flink 在调用程序的 main 方法时需要知道类型信息,Flink Java API 试图重建丢弃的类型信息,并将其显式存储在数据集和 operator 中;可以通过 DataStream.getType() 检索类型,该方法返回 TypeInformation 的一个实例,这是 Flink 表示类型的内部方式;
11.类型推断有其局限性,有时需要手动指定数据的类型,例如从集合创建数据集 StreamExecutionEnvironment.fromCollection(),可以在其中传递描述类型的参数;像 MapFunction<I,O> 这样的通用函数有时也需要额外的类型信息;
12.Flink 试图推断出在分布式计算过程中交换和存储的数据类型信息,在大多数情况下,Flink 会推断出所有必要的信息,使用户无需关心序列化框架和无需注册数据类型;
13.Flink 对数据类型了解得越多,序列化方案就越好;这对于 Flink 中的内存使用模式非常重要(尽可能在堆内/外处理序列化数据,使序列化成本非常低);
14.注册子类型:如果函数签名只描述超类型,但在执行过程中实际使用了超类型的子类型,那让 Flink 知道这些子类型会大大提高性能,需要在 StreamExecutionEnvironment 上为每个子类型调用.registerType(clazz);
15.注册自定义序列化程序:Flink 会为无法处理的类型使用 Kryo 序列化器,如果 kryo 序列化器也不能处理,需要在StreamExecutionEnvironment 上调用 .getConfig().addDefaultKryoSerializer(clazz,serializer) 注册自定义的序列化器;
16.添加类型提示(TypeHints):当 Flink 无法推断出通用类型时,必须传递类型提示,通常只有在 Java API 中需要;
17.TypeInformation 类是所有类型描述符的基类,它揭示了类型的一些基本属性,并可以为类型生成序列化器和比较器(Flink 中的比较器不仅定义顺序,还用于处理 keys);
18.在内部,Flink 对类型区分如下:
基本类型:Java 基本类型及其装箱形式以及 void、String、Date、BigDecimal 和 BigInteger;
基本数组和对象数组
复合类型:
Flink 的 Java 元组(Flink Java API的一部分):最多25个字段,不支持空字段;
Scala case classes (包括 Scala 元组):不支持 null 字段;
Row:具有任意数量的字段和支持空字段的元组;
POJO:遵循特定 bean 模式的类;
辅助类型:Option,Either,Lists,Maps,…;
泛型类型:Flink 本身不会序列化这些类型,而是由 Kryo 进行序列化;
19.POJO 类型规则:如果满足以下条件,Flink 将数据类型识别为 POJO 类型(并允许 “按名称” 字段引用):
该类是公共的和独立的(没有非静态内部类);
该类有一个公共的无参数构造函数;
类(和所有超类)中的所有非静态、非 transient 字段要么是公共的,要么有一个公共的 getter 和 setter 方法;
注意:当用户定义的数据类型无法识别为 POJO 类型时,必须将其处理为 GenericType 并使用 Kryo 进行序列化;
20.由于 Java 会擦除泛型类型信息,因此需要将类型传递给 TypeInformation:
对于非泛型类型,可以传递类:
TypeInformation<String> info = TypeInformation.of(String.class);
对于泛型类型,需要通过 TypeHint “捕获” 泛型类型信息:
TypeInformation<Tuple2<String, Double>> info = TypeInformation.of(new TypeHint<Tuple2<String, Double>>(){});
在内部,创建了 TypeHint 的一个匿名子类,该子类捕获泛型信息以将其保留到运行时;
21.有两种方法可以创建 TypeSerializer:
- 对 TypeInformation 对象调用 typeInfo.createSerializer(config),config 参数的类型为 ExecutionConfig,包含有关程序注册的自定义序列化器的信息;尽量将正确的 ExecutionConfig 传递给程序,可以通过调用 getExecutionConfig() 从 DataStream 中获取它;
- 在函数(如 RichMapFunction)内部使用 getRuntimeContext().createSerializer(typeInfo) 来获取它;
22.Java API中的类型提示:在 Flink 无法重建擦除的通用类型信息时,Java API 提供所谓的类型提示,类型提示告诉系统函数生成的数据流或数据集的类型,return 语句指定生成的类型;
23.Java 8 lambdas 的类型提取与非 lambdas 不同,因为 lambdas 与扩展函数接口的实现类无关,Flink 试图使用 Java 的泛型签名来确定参数类型和返回类型;但并非所有编译器都会为 Lambda 生成这些签名,有时也需要手动指定数据类型;
24.PojoTypeInfo 为 POJO 中的所有字段创建序列化程序;int、long、String 等标准类型由 Flink 自带的序列化程序处理,对于其它类型使用 Kryo,如果 Kryo 无法处理该类型,可以要求 PojoTypeInfo 使用 Avro 序列化 POJO,调用方法如下:env.getConfig().enableForceAvro();
25.Flink 会使用 Avro 序列化器自动序列化 Avro 生成的 POJO,如果希望 Kryo 序列化器处理整个 POJO 类型,配置如下:
env.getConfig().enableForceKryo();
26.如果 Kryo 无法序列化 POJO,可以向 Kryo 添加自定义序列化程序:
env.getConfig().addDefaultKryoSerializer(Class<?> type, Class<? extends Serializer<?>> serializerClass);
27.如果程序需要避免使用 Kryo 作为泛型类型的回退,确保通过 Flink 自己的序列化程序或通过用户自定义的自定义序列化程序有效地序列化所有类型,配置如下:env.getConfig().disableForceKryo();
注意:遇到要使用 Kryo 的数据类型时,以下设置会引发异常
env.getConfig().disableGenericTypes();
28.类型信息工厂允许将用户定义的类型信息插入 Flink 类型系统,需要实现 org.apache.flink.api.common.typeinfo.TypeInfoFactory 以返回自定义的类型信息;
如果相应的类型已经用 @org.apache.flink.api.common.typeinfo.TypeInfo 注解,则在类型提取阶段会调用工厂;
类型信息工厂可以在 Java 和 Scala API 中使用,在类型层次结构中,向上遍历时将选择最近的工厂,内置工厂具有最高优先级;工厂的优先级也高于 Flink 的内置类型;
29.方法 createTypeInfo(Type,Map<String,TypeInformation<?>) 为工厂的目标类型创建类型信息;这些参数提供了有关类型本身的附加信息,以及类型的泛型类型参数;
如果类型包含需要从 Flink 函数的输入类型派生的泛型参数,请确保还实现了org.apache.Flink.api.common.typeinfo.TypeInformation#getGenericParameters 用于泛型参数到类型信息的双向映射;
30.在内部,状态是否可以进行升级取决于用于读写持久化状态字节的序列化器,状态数据结构只有在其序列化器正确支持时才能升级;这一过程是被 Flink 的类型序列化框架生成的序列化器透明处理的;只适用于 Flink 自己生成的状态序列化器;即在声明状态时,状态描述符不可以配置为使用特定的 TypeSerializer 或 TypeInformation;
31.对状态类型升级,步骤如下:
- 对 Flink 流作业进行 savepoint 操作;
- 升级程序中的状态类型(例如:修改 Avro 的结构);
- 从 savepoint 恢复作业。当第一次访问状态数据时,Flink 会判断状态数据 schema 是否已经改变,并进行必要的迁移;
适应状态结构的改变而进行的状态迁移过程是自动发生的,并且状态之间是互相独立的;
32.Flink 内部首先会检查新的序列化器相对比之前的序列化器是否有不同的状态结构;如果有,那么之前的序列化器用来读取状态数据字节到对象,然后使用新的序列化器将对象回写为字节;
33.目前仅支持 POJO 和 Avro 类型的 schema 升级:
POJO 类型:Flink 基于下面的规则来支持 POJO 类型结构的升级
- 可以删除字段。一旦删除,被删除字段的前值将会在将来的 checkpoints 以及 savepoints 中删除。
- 可以添加字段。新字段会使用类型对应的默认值进行初始化。
- 不可以修改字段的声明类型。
- 不可以改变 POJO 类型的类名,包括类的命名空间。
注意:只有从 1.8.0 及以上版本的 Flink 生产的 savepoint 进行恢复时,POJO 类型的状态才可以进行升级;对 1.8.0 版本之前的 Flink 是没有办法进行 POJO 类型升级的;
Avro 类型:Flink 支持 Avro 状态类型的升级,只要数据结构的修改是被 Avro 的数据结构解析规则认为兼容的即可
除非新的 Avro 数据 schema 生成的类无法被重定位或者使用了不同的命名空间,在作业恢复时状态数据会被认为是不兼容的;
34.Flink 的 Schema 迁移有一些限制,这些限制是确保正确性所必需的;对于需要绕过这些限制并理解它们在特定用例中是安全的用户,可以考虑使用自定义序列化程序或状态处理器 API:
不支持 key 的 schema 演变:无法迁移 key 的 schema,因为这可能导致不确定性行为;如果一个 POJO 被用作 key,并且一个字段被丢弃,那么可能会突然出现多个现在相同的单独键,Flink无法合并相应的值;
此外,RocksDB 状态后端依赖于二进制对象标识,而不是 hashCode 方法,对 key 的对象结构的任何更改都可能导致不确定性行为;
Kryo 不能用于 schema 演变:当使用 Kryo 时,框架不能验证是否进行了不兼容的更改;如果包含给定类型的数据结构通过 Kryo 进行序列化,那么所包含的类型就不能进行 schema 进化;如果一个 POJO 包含一个 List<SometherPojo>,那么该 List 及其内容是通过 Kryo 序列化的,SometherPojo 不支持模式演化;
35.对状态使用自定义序列化,包含如何提供自定义状态序列化程序、实现允许状态模式演变的序列化程序;
36.注册托管 operator 或 keyed 状态时,需要 StateDescriptor 来指定状态的名称以及有关状态类型的信息,Flink 的类型序列化框架使用类型信息为状态创建适当的序列化程序;
37.可以让 Flink 使用自定义的序列化程序来序列化托管状态,只需使用自定义的 TypeSerializer 实现直接实例化 StateDescriptor:
new ListStateDescriptor<>("state-name",new CustomTypeSerializer());
38.从保存点恢复时,Flink 允许更改用于读取和写入先前注册状态的序列化程序,当状态恢复时,将为该状态注册一个新的序列化程序(即用于访问已恢复作业中的状态的 StateDescriptor 附带的序列化程序);这个新的序列化程序可能具有与以前的序列化程序不同的模式;因此,在实现状态序列化程序时,除了读取/写入数据的基本逻辑外,还需要实现如何更改序列化模式;
39.模式可能会在以下几种情况下发生变化:
- 状态类型的数据模式已经改变。即从用作状态的 POJO 中添加或删除字段;一般来说,在更改数据模式后,需要升级序列化程序的序列化格式。
- 序列化程序的配置已更改。为了使新的执行具有写入的状态模式的信息并检测模式是否已经改变,在获取 operator 状态的保存点时,需要将状态序列化器的快照与状态字节一起写入。
40.序列化程序的 TypeSerializerSnapshot 是一个时间点信息,它是关于状态序列化程序写入 schema 的唯一记录,以及还原与给定时间点相同的序列化程序所必需的附加信息;在 writeSnapshot 和 readSnapshot 方法中定义了在恢复时作为序列化程序快照应写入和读取的逻辑;
41.快照自己的写入模式可能也需要随着时间的推移而更改(例如,当希望向快照添加更多有关序列化程序的信息时);为了便于实现这一点,使用 getCurrentVersion 方法中定义的当前版本号对快照进行版本控制;在还原时,从保存点读取序列化程序快照时,写入快照的 schema 的版本将提供给 readSnapshot 方法,以便读取可以实现处理不同的版本;
42.在恢复时,应在 resolveSchemaCompatibility 方法中实现检测新序列化程序的 schema 是否已更改的逻辑;当在 operator 的恢复执行中,以前注册的状态再次向新的序列化程序注册时,旧的序列化程序快照将通过此方法提供给新的序列化器快照;此方法返回表示兼容性解析结果的 TypeSerializerSchemaCompatibility,它可以是以下内容之一:
- TypeSerializerSchemaCompatility.compatibleAsIs():此结果表示新的序列化程序是兼容的,即新的序列化器与以前的序列化程序具有相同的 schema。新的序列化程序可能已在 resolveSchemaCompatibility 方法中重新配置,因此它是兼容的。
- TypeSerializerSchemaCompatibility.compatibleAfterMigration():此结果表示新的序列化程序具有不同的序列化架构,可以通过使用以前的序列化程序(识别旧架构)将字节读取到状态对象中,然后使用新的序列化器(识别新架构)将对象重写回字节,从而从旧架构迁移。
- TypeSerializerSchemaCompatibility.incompatible():此结果表示新的序列化程序具有不同的序列化 schema,但无法从旧架构迁移。
43.序列化程序的 TypeSerializerSnapshot 的另一个重要作用是,它充当还原以前的序列化程序的工厂;即 TypeSerializerSnapshot 应该实现 restoreSerializer 方法来实例化一个序列化程序实例,该序列化程序实例可以识别以前的序列化程序的 schema 和配置,因此可以安全地读取以前的序列化程序器写入的数据;
44.Flink 如何与 TypeSerializer 和 TypeSerializerSnapshot 抽象交互:根据状态后端的不同,状态后端与抽象交互略有不同
堆外状态后端(例如 RocksDBStateBackend)【向具有 schema A 的状态序列化程序注册新状态、获取保存点、执行恢复时使用具有 schema B 的新状态序列化程序重新访问恢复的状态字节、将状态后端中的状态字节从 schema A迁移到 schema B】
堆状态后端(例如MemoryStateBackend、FsStateBackend)【向具有 schema A 的状态序列化程序注册新状态、取一个保存点,用 schema A 序列化所有状态、恢复时,将状态反序列化为堆中的对象、执行恢复时使用具有 schema B 的新状态序列化程序重新访问以前的状态、取另一个保存点,用 schema B 序列化所有状态】
45、Flink 提供了两个典型场景的 TypeSerializerSnapshot 的抽象基类:SimpleTypeSerializerSnapshot 和CompositeTypeSerializerSnapshot;
SimpleTypeSerializerSnapshot 适用于没有任何状态或配置的序列化程序,意味着序列化程序的序列化 schema 仅由序列化程序的类定义;IntSerializer 没有状态或配置,序列化格式仅由序列化程序类本身定义,并且只能由另一个 IntSerializer 读取,它适合SimpleTypeSerializerSnapshot 的用例;
CompositeTypeSerializerSnapshot 适用于依赖多个嵌套序列化程序进行序列化的序列化程序;将依赖于多个嵌套序列化程序的序列化程序称为 “外部” 序列化程序;例如,MapSerializer、ListSerializer 和 GenericArraySerializer等;当考虑 MapSerializer 的键和值序列化程序时将是嵌套的序列化程序,而 MapSerialize 器本身是“外部”序列化程序;
46、如果在 Flink 程序中使用了 Flink 类型序列化器无法进行序列化的用户自定义类型,Flink 会回退到通用的 Kryo 序列化器;可以使用 Kryo 注册自己的序列化器或序列化系统,比如 Google Protobuf 或 Apache Thrift;
47、使用方法是在 Flink 程序中的 ExecutionConfig 注册类类型以及序列化器;需要确保你的自定义序列化器继承了 Kryo 的序列化器类,对于 Google Protobuf 或 Apache Thrift,这一点已经做好了;
48、flink 自带的 Tuple 类的序列化性能最高,其中一部分原因来源于不需要使用反射来访问 Tuple 中的字段;
49、Pojo 序列化比 Tuple 序列化性能差一些,但是比 kryo 的序列化方式性能要高几倍;
50、Protobuf 或者 Thrift 经由 Kryo 注册后,其序列化性能并不差;
6、算子
1)概述
1.总结
1.转换算子
Map[DataStream → DataStream]:输入一个元素,转换后输出一个元素;
FlatMap[DataStream → DataStream]:输入一个元素,转换后产生零个、一个或多个元素;
Filter[DataStream → DataStream]:为每个元素执行一个boolean function,并保留那些 function 输出值为 true 的元素;
KeyBy[DataStream → KeyedStream]:在逻辑上将流划分为不相交的分区,具有相同 key 的记录都分配到同一个分区;在内部 keyBy() 是通过哈希分区实现的;当类为 POJO 类,却没有重写 hashCode() 方法而是依赖于 Object.hashCode() 实现或它是任意类的数组时不能作为 key;
Reduce[KeyedStream → DataStream]:在相同 key 的数据流上“滚动”执行 reduce,将当前元素与最后一次 reduce 得到的值组合然后输出新值;
Window[KeyedStream → WindowedStream]:在已经分区的 KeyedStreams 上定义 Window,Window 根据某些特征对每个 key Stream 中的数据进行分组;
WindowAll[DataStream → AllWindowedStream]:在 DataStream 上定义 Window,Window 根据某些特征对所有流事件进行分组,注意所有记录都将收集到 windowAll 算子对应的一个任务中[并行度为1];
WindowReduce[WindowedStream → DataStream]:对窗口应用 reduce function 并返回 reduce 后的值;
Union[DataStream* → DataStream]:将两个或多个数据流联合来创建一个包含所有流中数据的新流,如果一个数据流和自身进行联合,这个流中的每个数据将在合并后的流中出现两次;
Window Join[DataStream,DataStream → DataStream]:根据指定的 key 和窗口 join 两个数据流;
Interval Join[KeyedStream,KeyedStream → DataStream]:根据 key 相等并且在指定的时间范围内(e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound)的条件将分别属于两个 keyed stream 的元素 e1 和 e2 Join 在一起;
Window CoGroup[DataStream,DataStream → DataStream]:根据指定的 key 和窗口将两个数据流组合在一起;
Connect[DataStream,DataStream → ConnectedStream]:“连接” 两个数据流并保留各自的类型,connect 允许在两个流的处理逻辑之间共享状态;
CoMap, CoFlatMap[ConnectedStream → DataStream]:在连接的数据流上进行 map 和 flatMap;
Cache[DataStream → CachedDataStream]:把算子的结果缓存起来,目前只支持批模式下运行的作业;算子的结果在算子第一次执行的时候会被缓存起来,之后的作业中会复用该算子缓存的结果;如果算子的结果丢失了,它会被原来的算子重新计算并缓存;
2.物理分区算子
Global Partitioner[DataStream → DataStream]:将数据输出到下游的0号分区中;
Custom Partitioner[DataStream → DataStream]:使用自定义的 Partitioner 为每个元素选择目标分区;
Shuffle Partitioner[DataStream → DataStream]:将元素随机均匀的输出到下游的分区中;
Rebalance Partitioner[DataStream → DataStream]:将元素以循环的方式输出到下游的分区中;
Rescale Partitioner[DataStream → DataStream]:基于上下游算子的并行度,将元素以循环的方式输出到下游的分区中;
Broadcast Partitioner[DataStream → DataStream]:将所有元素广播到下游的每个分区中;
3.算子链和资源组
将两个算子链接在一起,可以使它们在同一个线程中执行,从而提升性能;Flink 默认会将能链接的算子尽可能的进行链接;
可以调用 StreamExecutionEnvironment.disableOperatorChaining() 方法对整个作业禁用算子链;
可以调用 startNewChain() 方法基于当前算子创建一个新的算子链[只能在 DataStream 转换操作后调用,因为只对前一次的数据转换生效];
可以调用 disableChaining() 方法禁止和当前算子链接在一起[只能在 DataStream 转换操作后调用,因为只对前一次的数据转换生效];
可以调用 slotSharingGroup() 方法为当前算子配置 slot 共享组,Flink 会将同一个 slot 共享组的算子放在同一个 slot 中,而将不在同一个 slot 共享组的算子保留在其它 slot 中,可用于隔离 slot;slot 共享组的默认名称是“default”,可以调用 slotSharingGroup(“default”) 来显式地将算子放入该组;
4.Task 和 Slot 的计算
当算子 A 被设置在单独的 SharingGroup 中时,算子 A 有几个并行度就需要几个 slot;
当多个算子能被算子链连在一起时,算子有几个并行度就需要几个 slot;
当算子 A 不能被算子链 B 连在一起,且算子 A 被设置在与算子链 B 相同的 SharingGroup 中时,算子 A 的并行度大于算子链 B 的并行度部分会占用额外的 slot 数;
能被算子链连在一起的算子,可以在同一个线程中执行,只创建一个 Task;
不能被算子链连在一起的算子,每个并行度需要单独创建一个 Task 执行;
5.算子链连接的条件
上下游的并行度一致;
下游节点的入度为1(即下游节点没有来自其它节点的输入);
上下游节点都在同一个 slotSharingGroup 中;
下游节点的 chain 策略为 ALWAYS;
上游节点的 chain 策略为 ALWAYS 或 HEAD;
两个节点间数据分区方式是 Forward Partition;
用户没有禁用算子链;
6.名字和描述
name 主要用在用户界面、线程名、日志、指标等场景,名字需要尽可能简洁,避免对外部系统产生大的压力;description 主要用在执行计划展示及用户界面展示等场景;
建议为算子设置 name\description\uid\parallelism\maxParallelism 参数;
2)窗口
1.总结
1.Flink 窗口在 keyed streams 要调用 keyBy(...) 后再调用 window(...),而 non-keyed streams 直接调用 windowAll(...);
2.Keyed Windows 使用示例
stream
.keyBy(...) <- 仅 keyed 窗口需要
.window(...) <- 必填项:"assigner"
[.trigger(...)] <- 可选项:"trigger" (省略则使用默认 trigger)
[.evictor(...)] <- 可选项:"evictor" (省略则不使用 evictor)
[.allowedLateness(...)] <- 可选项:"lateness" (省略则为 0)
[.sideOutputLateData(...)] <- 可选项:"output tag" (省略则不对迟到数据使用 side output)
.reduce/aggregate/apply() <- 必填项:"function"
[.getSideOutput(...)] <- 可选项:"output tag"
3.Non-Keyed Windows 使用示例
stream
.windowAll(...) <- 必填项:"assigner"
[.trigger(...)] <- 可选项:"trigger" (else default trigger)
[.evictor(...)] <- 可选项:"evictor" (else no evictor)
[.allowedLateness(...)] <- 可选项:"lateness" (else zero)
[.sideOutputLateData(...)] <- 可选项:"output tag" (else no side output for late data)
.reduce/aggregate/apply() <- 必填项:"function"
[.getSideOutput(...)] <- 可选项:"output tag"
4.一个窗口在第一个属于它的元素到达时就会被创建,然后在时间(event 或 processing time)超过窗口的“结束时间戳 + 用户定义的 allowed lateness“时被完全删除;
5.Flink 仅保证删除基于时间的窗口,其他类型的窗口不做保证, 比如全局窗口;
6.每个窗口会设置自己的 Trigger 和 function (ProcessWindowFunction、ReduceFunction、或 AggregateFunction),该 function 决定如何计算窗口中的内容,而 Trigger 决定窗口中的数据何时可以被 function 计算;
7.Trigger 还可以在 window 被创建后、删除前的这段时间内定义何时清理(purge)窗口中的数据;此处数据仅指窗口内的元素,不包括窗口的 meta data,即窗口在 purge 后仍然可以加入新的数据。
8.可以指定一个 Evictor,在 trigger 触发之后,Evictor 可以在窗口函数的前后删除数据;
9.在定义窗口前需确定 stream 是 keyed 还是 non-keyed,keyBy(...) 会将无界 stream 分割为逻辑上的 keyed stream;
对于 keyed stream,数据的任何属性都可以作为 key,使用 keyed stream 允许窗口计算由多个 task 并行,因为每个逻辑上的 keyed stream 都可以被单独处理,属于同一个 key 的元素会被发送到同一个 task;
对于 non-keyed stream,原始的 stream 不会被分割为多个逻辑上的 stream, 所有的窗口计算会被同一个 task 完成,也就是 parallelism 为 1;
10. WindowAssigner 负责将 stream 中的每个数据分发到一个或多个窗口中,Flink 提供了默认的 window assigner,即 tumbling windows、sliding windows、session windows 和 global windows;也可以继承 WindowAssigner 类来实现自定义的 window assigner;
11.基于时间的窗口用 start timestamp(包含)和 end timestamp(不包含)描述窗口的大小;Flink 处理基于时间的窗口使用的是 TimeWindow, 它有查询开始和结束的 timestamp 以及返回窗口所能储存的最大 timestamp 的方法 maxTimestamp();
12.滚动窗口(Tumbling Windows),滚动窗口的 assigner 分发元素到指定大小的窗口,滚动窗口的大小是固定的,且各自范围之间不重叠;
13.滑动窗口(Sliding Windows),滑动窗口的 assigner 分发元素到指定大小的窗口,窗口大小通过 window size 参数设置,滑动窗口需要一个额外的滑动距离(window slide)参数来控制生成新窗口的频率;如果 slide 小于窗口大小,滑动窗口可以允许窗口重叠,此时一个元素可能会被分发到多个窗口;
14.滚动窗口和滑动窗口的 assigners 可以设置 offset 参数,这个参数可以用来对齐窗口,不设置 offset 时,窗口的起止时间会与 linux 的 epoch 对齐,一个重要的 offset 用例是根据 UTC-0 调整窗口的时差,在中国可能会设置 offset 为 Time.hours(-8);
15.会话窗口(Session Windows),会话窗口的 assigner 会把数据按活跃的会话分组,会话窗口不会相互重叠,且没有固定的开始或结束时间,会话窗口在一段时间没有收到数据之后会关闭,会话窗口的 assigner 可以设置固定的会话间隔(session gap)或用 session gap extractor 函数来动态地定义多长时间算作不活跃;当超出了不活跃的时间段,当前的会话就会关闭,接下来的数据将被分发到新的会话窗口;
16.会话窗口并没有固定的开始或结束时间,在 Flink 内部,会话窗口的算子会为每一条数据创建一个窗口,然后将距离不超过预设间隔的窗口合并,想要让窗口可以被合并,会话窗口需要拥有支持合并的 Trigger 和 Window Function, 例如 ReduceFunction、AggregateFunction 或 ProcessWindowFunction;
17.全局窗口(Global Windows),全局窗口的 assigner 将拥有相同 key 的所有数据分发到一个全局窗口,此窗口模式仅在指定了自定义的 trigger 时有用,否则计算不会发生,因为全局窗口没有天然的终点去触发其中积累的数据;
18.窗口函数(Window Functions)有三种:ReduceFunction、AggregateFunction 或 ProcessWindowFunction;
- ReduceFunction、AggregateFunction 执行更高效,因为 Flink 可以在每条数据到达窗口后进行增量聚合;
- 而 ProcessWindowFunction 会得到能够遍历当前窗口内所有数据的 Iterable,以及关于这个窗口的 meta-information;
19.ProcessWindowFunction 可以与 ReduceFunction 或 AggregateFunction 合并来提高效率,既可以增量聚合窗口内的数据,又可以从 ProcessWindowFunction 接收窗口的 metadata;
20.ReduceFunction:指定两条输入数据如何合并起来产生一条输出数据,输入和输出数据的类型必须相同;
21.AggregateFunction:接收三个参数,输入数据的类型(IN)、累加器的类型(ACC)和输出数据的类型(OUT);
22.AggregateFunction 接口有如下方法:
把每一条元素加进累加器:add
创建初始累加器:createAccumulator
合并两个累加器:merge
从累加器中提取输出数据:getResult
23.ProcessWindowFunction:具备 Iterable 能获取窗口内所有的元素,以及用来获取时间和状态信息的 Context 对象,但因为窗口中的数据无法被增量聚合,而需要在窗口触发前缓存所有数据;
24.增量聚合的 ProcessWindowFunction:ProcessWindowFunction 可以与 ReduceFunction 或 AggregateFunction 搭配使用,使其能够在数据到达窗口的时候进行增量聚合,当窗口关闭时,ProcessWindowFunction 将会得到聚合的结果;即实现了增量聚合窗口的元素并且也从 ProcessWindowFunction 中获得了窗口的元数据;
25.除了访问 keyed state,ProcessWindowFunction 还可以使用作用域仅为“当前正在处理的窗口”的 keyed state;
26.process() 接收到的 Context 对象中有两个方法允许访问以下两种 state:
- globalState(),访问全局的 keyed state
- windowState(),访问作用域仅限于当前窗口的 keyed state
27.如果可能将一个 window 触发多次(比如迟到数据会再次触发窗口计算,或自定义了根据推测提前触发窗口的 trigger),这时可能需要在 per-window state 中储存关于之前触发的信息或触发的总次数;
28.当使用窗口状态时,一定记得在删除窗口时清除这些状态,应该定义在 clear() 方法中;
29.Trigger 决定了一个窗口(由 window assigner 定义)何时可以被 window function 处理;每个 WindowAssigner 都有一个默认的 Trigger,如果默认 trigger 无法满足需要,可以在 trigger(...) 调用自定义的 trigger;
30.Trigger 接口提供了五个方法来响应不同的事件:
- onElement() 方法在每个元素被加入窗口时调用。
- onEventTime() 方法在注册的 event-time timer 触发时调用。
- onProcessingTime() 方法在注册的 processing-time timer 触发时调用。
- onMerge() 方法与有状态的 trigger 相关。该方法会在两个窗口合并时,将窗口对应 trigger 的状态合并,比如使用会话窗口时。
- clear() 方法处理在对应窗口被移除时所需的逻辑。
前三个方法通过返回 TriggerResult 来决定 trigger 如何应对到达窗口的事件,应对方案有以下几种:
- CONTINUE: 什么也不做
- FIRE: 触发计算
- PURGE: 清空窗口内的元素
- FIRE_AND_PURGE: 触发计算,计算结束后清空窗口内的元素
31.当 trigger 触发时,它可以返回 FIRE 或 FIRE_AND_PURGE;FIRE 会保留被触发的窗口中的内容,而 FIRE_AND_PURGE 会删除这些内容,Flink 内置的 trigger 默认使用 FIRE,不会清除窗口的内容;Purge 只会移除窗口的内容,不会移除关于窗口的 meta-information 和 trigger 的状态;
32.Flink 包含一些内置 trigger:
- ContinuousProcessingTimeTrigger:根据间隔时间周期性触发窗口或者当 Window 的结束时间小于当前 ProcessTime 触发窗口计算
- ProcessingTimeoutTrigger:当内置触发器满足超时时间时,触发窗口的计算
- ProcessingTimeTrigger:ProcessingTimeWindows 默认使用,会在处理时间越过窗口结束时间后直接触发
- ContinuousEventTimeTrigger:根据间隔时间周期性触发窗口或者当 Window 的结束时间小于当前的 watermark 时触发窗口计算
- EventTimeTrigger:EventTimeWindows 默认使用,会在 watermark 越过窗口结束时间后直接触发
- PurgingTrigger:接收另一个 trigger 并将它转换成一个会清理数据的 trigger
- NeverTrigger:GlobalWindows 默认使用,任何时候都不触发窗口计算
- DeltaTrigger:根据接入数据计算出来的 Delta 指标是否超过指定的 Threshold 去判断是否触发窗口计算
- CountTrigger:在窗口中的元素超过预设的限制时触发
33.Flink 的窗口模型允许在 WindowAssigner 和 Trigger 之外指定可选的 Evictor,通过 evictor(...) 方法传入 Evictor,Evictor 可以在 trigger 触发后、调用窗口函数之前或之后从窗口中删除元素;
34.evictBefore() 包含在调用窗口函数前的逻辑,而 evictAfter() 包含在窗口函数调用之后的逻辑,在调用窗口函数之前被移除的元素不会被窗口函数计算;
35.Flink 有三个内置的 evictor:
- CountEvictor: 仅记录用户指定数量的元素,一旦窗口中的元素超过这个数量,多余的元素会从窗口缓存的开头移除;
- DeltaEvictor: 接收 DeltaFunction 和 threshold 参数,计算最后一个元素与窗口缓存中所有元素的差值,并移除差值大于或等于 threshold 的元素;
- TimeEvictor: 接收 interval 参数,以毫秒表示,它会找到窗口中元素的最大 timestamp 即 max_ts 并移除比 max_ts - interval 小的所有元素;
默认情况下,所有内置的 evictor 逻辑都在调用窗口函数前执行;Flink 不对窗口中元素的顺序做任何保证,即使 evictor 从窗口缓存的开头移除一个元素,这个元素也不一定是最先或者最后到达窗口的;
36.使用 ProcessTime 和 GlobalWindows 时无迟到数据,但使用 event-time 窗口时,数据可能会迟到,默认 watermark 一旦越过窗口结束的 timestamp,迟到的数据就会被直接丢弃;
37.Allowed lateness 默认是 0,在 watermark 超过窗口末端、到达窗口末端加上 allowed lateness 之前的这段时间内到达的元素,依旧会被加入窗口;Flink 会将窗口状态保存到 allowed lateness 超时才会将窗口及其状态删除;但窗口再次触发的结果取决于触发器是否 purge 而导致结果不同;
38.通过 Flink 的侧流输出功能,可以获得迟到数据的数据流;
39.当指定了大于 0 的 allowed lateness 时,窗口本身以及其中的内容仍会在 watermark 越过窗口末端后保留;此时如果一个迟到但未被丢弃的数据到达,它可能会再次触发这个窗口,这种触发被称作 late firing;如果是使用会话窗口的情况,late firing 可能会进一步合并已有的窗口,因为他们可能会连接现有的、未被合并的窗口;late firing 发出的元素应该被视作对之前计算结果的更新,即数据流中会包含一个相同计算任务的多个结果,应用需要考虑到这些重复的结果,或去除重复的部分;
40.窗口操作的结果会变回 DataStream,并且窗口操作的信息不会保存在输出的元素中,如果想要保留窗口的 meta-information,需要在 ProcessWindowFunction 里手动将他们放入输出的元素中;
41.当 watermark 到达窗口算子时,它触发了两件事:
- 这个 watermark 触发了所有最大 timestamp(即 end-timestamp - 1)小于它的窗口;
- 这个 watermark 被原封不动地转发给下游的任务;
42.窗口可以被定义在很长的时间段上(比如几天、几周或几个月)并且积累下很大的状态,当估算窗口计算的储存需求时,注意如下:
- Flink 会为一个元素在它所属的每一个窗口中都创建一个副本;在滚动窗口的设置中一个元素只会存在一个副本,在滑动窗口的设置中一个元素可能会被拷贝到多个滑动窗口中,每个(滑动窗口长度/滑动距离)会存在一个数据副本;
- ReduceFunction 和 AggregateFunction 可以极大地减少储存需求,它们会就地聚合到达的元素,且每个窗口仅储存一个值,而使用 ProcessWindowFunction 需要累积窗口中所有的元素;
- 使用 Evictor 可以避免预聚合,因为窗口中的所有数据必须先经过 evictor 才能进行计算;
43.Window join 作用在两个流中有相同 key 且处于相同窗口的元素上,两个流中的元素在组合之后,会被传递给用户定义的 JoinFunction 或 FlatJoinFunction,可以用它们输出符合 join 要求的结果;
stream.join(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
44.一个流中的元素在与另一个流中对应的元素完成 join 之前不会被输出;完成 join 的元素会将他们的 timestamp 设为对应窗口中允许的最大 timestamp;
45.滚动 Window Join:所有 key 相同且共享一个滚动窗口的元素会被组合成对,并传递给 JoinFunction 或 FlatJoinFunction,行为与 inner join 类似,所以一个流中的元素如果没有与另一个流中的元素组合起来,它就不会被输出;
46.滑动 Window Join:所有 key 相同且处于同一个滑动窗口的元素将被组合成对,并传递给 JoinFunction 或 FlatJoinFunction,当前滑动窗口内,如果一个流中的元素没有与另一个流中的元素组合起来,它就不会被输出;
47.在某个滑动窗口中被 join 的元素不一定会在其他滑动窗口中被 join;
48.会话 Window Join:所有 key 相同且组合后符合会话要求的元素将被组合成对,并传递给 JoinFunction 或 FlatJoinFunction,这个操作同样是 inner join,如果一个会话窗口中只含有某一个流的元素,这个窗口将不会产生输出;
49.Interval join:组合元素的条件为两个流(A 和 B)中 key 相同且 B 中元素的 timestamp 处于 A 中元素 timestamp 的一定范围内,即 b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound] 或 a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound;
上述的 a 和 b 为 A 和 B 中共享相同 key 的元素,上界和下界可正可负,只要下界永远小于等于上界即可,Interval join 目前仅执行 inner join;
50.当一对元素被传递给 ProcessJoinFunction,他们的 timestamp 会从两个元素的 timestamp 中取最大值 (timestamp 可以通过 ProcessJoinFunction.Context 访问);
51.Interval join 目前仅支持 event time;默认情况下,上下界也被包括在区间内,但 .lowerBoundExclusive() 和 .upperBoundExclusive() 可以将它们排除在外;
52.Window Join 和 Interval Join 可以先按 keyBy 分组,再根据数据中的字段进行匹配来模拟 left join 或 right join;
3)Joining
1.总结
1.Window join 作用在两个流中有相同 key 且处于相同窗口的元素上,两个流中的元素在组合之后,会被传递给用户定义的 JoinFunction 或 FlatJoinFunction,可以用它们输出符合 join 要求的结果;
stream.join(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
2.一个流中的元素在与另一个流中对应的元素完成 join 之前不会被输出;完成 join 的元素会将他们的 timestamp 设为对应窗口中允许的最大 timestamp;
3.滚动 Window Join:所有 key 相同且共享一个滚动窗口的元素会被组合成对,并传递给 JoinFunction 或 FlatJoinFunction,行为与 inner join 类似,所以一个流中的元素如果没有与另一个流中的元素组合起来,它就不会被输出;
4.滑动 Window Join:所有 key 相同且处于同一个滑动窗口的元素将被组合成对,并传递给 JoinFunction 或 FlatJoinFunction,当前滑动窗口内,如果一个流中的元素没有与另一个流中的元素组合起来,它就不会被输出;
5.在某个滑动窗口中被 join 的元素不一定会在其他滑动窗口中被 join;
6.会话 Window Join:所有 key 相同且组合后符合会话要求的元素将被组合成对,并传递给 JoinFunction 或 FlatJoinFunction,这个操作同样是 inner join,如果一个会话窗口中只含有某一个流的元素,这个窗口将不会产生输出;
7.Interval join:组合元素的条件为两个流(A 和 B)中 key 相同且 B 中元素的 timestamp 处于 A 中元素 timestamp 的一定范围内,即 b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound] 或 a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound;
上述的 a 和 b 为 A 和 B 中共享相同 key 的元素,上界和下界可正可负,只要下界永远小于等于上界即可,Interval join 目前仅执行 inner join;
8.当一对元素被传递给 ProcessJoinFunction,他们的 timestamp 会从两个元素的 timestamp 中取最大值 (timestamp 可以通过 ProcessJoinFunction.Context 访问);
9.Interval join 目前仅支持 event time;默认情况下,上下界也被包括在区间内,但 .lowerBoundExclusive() 和 .upperBoundExclusive() 可以将它们排除在外;
10.Window Join 和 Interval Join 只适合 Inner Join,可以通过 coGroup/connect 实现 Left/Right/Inner Join;
4)Process Function
1.总结
1.ProcessFunction 是底层的数据流处理操作,可访问所有(非循环)流应用程序的基本模块;
- 事件 (数据流中的元素)
- 状态(容错、一致、仅在 keyed stream 上)
- 定时器(事件时间和处理时间,仅在 keyed stream 上)
2.ProcessFunction 允许访问 keyed State,可通过 RuntimeContext 访问;
3.定时器支持处理时间和事件时间,对函数 processElement(…)的每次调用都会获得一个 Context 对象,该对象可以访问元素的事件时间戳和 TimerService;TimerService 可用于注册处理时间和事件时间定时器;对于事件时间定时器,当 watermark 到达或超过定时器的时间戳时,会调用 onTimer(...),在该调用过程中,所有状态的作用域再次限定为创建定时器时使用的 key,从而允许定时器操作 keyed State;
4.对于两个输入的底层 Join 可以使用 CoProcessFunction 或 KeyedCoProcessFunction,通过调用 processElement1(…)和processElement2(…)分别处理两个输入;
5.底层 Join 流程如下:
为一个输入或两个输入创建状态对象;
从输入中接收元素时更新状态;
从另一个输入接收元素后,查询状态并产生 Join 结果;
6.TimerService 按 key 和时间戳消除重复的定时器,即每个 key 和时间戳最多有一个定时器,如果为同一时间戳注册了多个计时器,那么 onTimer() 方法将只被调用一次;
7.Flink 会同步 onTimer() 和 processElement() 的调用,无需担心同时修改状态;
8.定时器是容错的,并与应用程序的状态一起进行 Checkpoint,如果发生故障恢复或从保存点启动应用程序,则会恢复定时器;
9.当应用程序从故障中恢复或从保存点启动时,本应在恢复前启动的检查点中的处理时间定时器将立即启动;
10.除了 RocksDB 后端/与增量快照/与基于堆的定时器的组合,定时器使用异步检查点;但是大量的定时器会增加检查点时间,因为定时器是检查点状态的一部分;
11.由于 Flink 为每个 key 和时间戳只维护一个定时器,可以通过降低定时器的精度来合并定时器以减少定时器的数量;
对于1秒(事件或处理时间)的定时器精度,可以将目标时间四舍五入到整秒,定时器最多会提前1秒触发,但不会晚于要求的毫秒精度,每个键和秒最多有一个计时器;
long coalescedTime = ((ctx.timerService().currentProcessingTime() + timeout) / 1000) * 1000;
ctx.timerService().registerProcessingTimeTimer(coalescedTime);
由于事件时间定时器只在 watermark 到达时触发,可以使用当前 watermark 来注册定时器,并将其与下一个 watermark 合并;
long coalescedTime = ctx.timerService().currentWatermark() + 1;
ctx.timerService().registerEventTimeTimer(coalescedTime);
12.停止处理时间定时器-ctx.timerService().deleteProcessingTimeTimer();停止事件时间定时器-ctx.timerService().deleteEventTimeTimer();如果没有注册具有给定时间戳的定时器,则停止定时器无效;
5)异步 I\O
1.总结
1.在与外部系统交互(用数据库中的数据扩充流数据)时,需要考虑与外部系统的通信延迟对整个流处理应用的影响:
同步交互:使用 MapFunction 访问外部数据库的数据,MapFunction 向数据库发送一个请求然后一直等待,直到收到响应;大多数情况下,等待占据了函数运行的大部分时间;
异步交互:一个并行函数实例可以并发地处理多个请求和接收多个响应,使函数在等待的时间可以发送其他请求和接收其他响应,使等待的时间可以被多个请求分摊;大多数情况下,异步交互可以大幅度提高流处理的吞吐量;
2.提高 MapFunction 的并行度(parallelism)在有些情况下也可以提升吞吐量,但是这样做通常会导致非常高的资源消耗:更多的并行 MapFunction 实例意味着更多的 Task、更多的线程、更多的 Flink 内部网络连接、更多的与数据库的网络连接、更多的缓冲和更多程序内部协调的开销;
3.异步 I/O 算子使用前提:
需要支持异步请求的数据库客户端;
如果没有支持异步请求的客户端,可以通过创建多个客户端并使用线程池处理同步调用的方法,将同步客户端转换为有限并发的客户端,比正规的异步客户端效率低;
4.Flink 的异步 I/O API 允许用户在流处理中使用异步请求客户端,API 处理与数据流的集成,同时还能处理好顺序、事件时间和容错等;
5.在具备异步数据库客户端的基础上,实现数据流转换操作与数据库的异步 I/O 交互需要以下三部分:
- 实现分发请求的 AsyncFunction;
- 获取数据库交互的结果并发送给 ResultFuture 的回调函数;
- 将异步 I/O 操作应用于 DataStream,作为 DataStream 的一次转换操作,启用或者不启用重试;
6.第一次调用 ResultFuture.complete 后 ResultFuture 就完成了,后续的 complete 调用都将被忽略;
7.Timeout:超时参数定义了异步操作执行多久未完成、最终认定为失败的时长,如果启用重试,则可能包括多个重试请求,可以防止一直等待得不到响应的请求;
8.Capacity: 容量参数定义了可以同时进行的异步请求数;即使异步 I/O 通常带来更高的吞吐量,执行异步 I/O 操作的算子仍然可能成为流处理的瓶颈,限制并发请求的数量可以确保算子不会持续累积待处理的请求进而造成积压,而是在容量耗尽时触发反压;
9.AsyncRetryStrategy: 重试策略参数定义了什么条件会触发延迟重试以及延迟的策略,如固定延迟、指数后退延迟、自定义实现等;
10.超时处理:
当异步 I/O 请求超时的时候,默认会抛出异常并重启作业;
如果想处理超时,可以重写 AsyncFunction#timeout 方法;重写 AsyncFunction#timeout 时需要调用 ResultFuture.complete() 或者 ResultFuture.completeExceptionally() 以通知 Flink 这条记录的处理已经完成;如果超时发生时不想发出任何记录,可以调用 ResultFuture.complete(Collections.emptyList());
11.AsyncFunction 发出的并发请求经常以不确定的顺序完成,这取决于请求得到响应的顺序;Flink 提供两种模式控制结果记录以何种顺序发出。
- 无序模式: 异步请求一结束就立刻发出结果记录。流中记录的顺序在经过异步 I/O 算子之后发生了改变。当使用处理时间作为基本时间特征时,这个模式具有最低的延迟和最少的开销。此模式使用 AsyncDataStream.unorderedWait(...) 方法。
- 有序模式: 保持了流的顺序。发出结果记录的顺序与触发异步请求的顺序(记录输入算子的顺序)相同;算子将缓冲一个结果记录直到这条记录前面的所有记录都发出(或超时),因为记录或者结果要在 checkpoint 的状态中保存更长的时间,所以与无序模式相比,有序模式通常会带来额外的延迟和 checkpoint 开销。此模式使用 AsyncDataStream.orderedWait(...) 方法。
12.当流处理应用使用事件时间时,异步 I/O 算子会正确处理 watermark。
- 无序模式:Watermark 既不超前于记录也不落后于记录,即 watermark 建立了顺序的边界。只有连续两个 watermark 之间的记录是无序发出的。在一个 watermark 后面生成的记录只会在这个 watermark 发出以后才发出。在一个 watermark 之前的所有输入的结果记录全部发出以后,才会发出这个 watermark。在 watermark 的情况下,无序模式会引入一些与有序模式相同的延迟和管理开销。开销大小取决于 watermark 的频率;
- 有序模式:连续两个 watermark 之间的记录顺序也被保留了。开销与使用处理时间相比,没有显著的差别。
13.异步 I/O 算子提供了完全的精确一次容错保证,它将异步请求的记录保存在 checkpoint 中,在故障恢复时重新触发请求;
14.重试支持为异步 I/O 操作引入了一个内置的重试机制,它对用户的异步函数实现逻辑是透明的。
- AsyncRetryStrategy: 异步重试策略包含了触发重试条件 AsyncRetryPredicate 定义,以及根据当前已尝试次数判断是否继续重试、下次重试间隔时长的接口方法。在满足触发重试条件后,有可能因为当前重试次数超过预设的上限放弃重试,或是在任务结束时被强制终止重试(此时系统以最后一次执行的结果或异常作为最终状态)。
- AsyncRetryPredicate: 触发重试条件可以选择基于返回结果、执行异常来定义条件,两种条件是或的关系,满足其一即会触发。
15.在实现使用 Executor 和回调的 Futures 时,建议使用 DirectExecutor,因为通常回调的工作量很小,DirectExecutor 避免了额外的线程切换开销;回调通常只是把结果发送给 ResultFuture,也就是把它添加进输出缓冲;从这里开始,包括发送记录和与 chenkpoint 交互在内的繁重逻辑都将在专有的线程池中进行处理。
16.DirectExecutor 可以通过 org.apache.flink.util.concurrent.Executors.directExecutor() 或 com.google.common.util.concurrent.MoreExecutors.directExecutor() 获得;
17.默认情况下,AsyncFunction 的算子(异步等待算子)可以在作业图的任意处使用,但它不能与 SourceFunction/SourceStreamTask 组成算子链;
18.以下情况将阻塞 asyncInvoke(...) 函数,从而使异步行为无效:
- 使用同步数据库客户端,它的查询方法调用在返回结果前一直被阻塞;
- 在 asyncInvoke(...) 方法内阻塞等待异步客户端返回的 future 类型对象;
19.启用重试后可能需要更大的缓冲队列容量:
新的重试功能可能会导致更大的队列容量要求,最大数量可以近似地评估如下:
inputRate * retryRate * avgRetryDuration
例如,对于一个输入率=100条记录/秒的任务,其中1%的元素将平均触发1次重试,平均重试时间为60秒,额外的队列容量要求为:
100条记录/秒 * 1% * 60s = 60
即在无序输出模式下,给工作队列增加 60 个容量可能不会影响吞吐量;而在有序模式下,头部元素是关键点,它未完成的时间越长,算子提供的处理延迟就越长;在相同的超时约束下,如果头元素事实上获得了更多的重试,那重试功能可能会增加头部元素的处理时间即未完成时间,也就是说在有序模式下,增大队列容量并不是总能提升吞吐。
20.当队列容量增长时(可以缓解背压),OOM 的风险会随之增加;对于 ListState 存储来说,理论的上限是 Integer.MAX_VALUE,虽然队列容量的限制是一样的,但在生产中不能把队列容量增加到太大,此时增加任务的并行性也许更可行;
7、数据源-详见原理
8、旁路输出
1)概述
1.总结
1.可以在 process 方法中,通过 Context 将数据发送到由 OutputTag 标识的旁路输出中,用来拆分数据;
2.可以在 DataStream 运算结果上使用 getSideOutput(OutputTag) 方法获取旁路输出流。
9、应用程序参数处理
1)应用程序参数处理
1.总结
1.可以通过 Parametertool、Commons CLI、argparse4j 来获取外部配置参数;
2.可以通过 ParameterTool 读取来自 .properties 文件、命令行、系统属性的配置参数;
3.可以在 ExecutionConfig 中注册全局作业参数,在 rich 函数中通过 getRuntimeContext().getGlobalJobParameters() 获取全局作业参数。
10、测试
1)概述
1.总结
1.建议始终以 parallelism > 1 的方式在本地测试 pipeline,以识别只有在并行执行 pipeline 时才会出现的 bug。
11、Java Lambda 表达式
1)概述
1.总结
1.当 Lambda 表达式使用 Java 泛型时,需要显式地声明类型信息;使用显式的 ".returns(...)" 、使用类来替代、使用匿名类来替代,使用 Tuple 的子类如 DoubleTuple 来替代;
12、管理执行
1)概述
1.总结
1.StreamExecutionEnvironment 包含了 ExecutionConfig,它允许在运行时设置作业特定的配置;
2.通过 getRuntimeContext() 方法在 Rich* function 中可以访问到 ExecutionConfig;
3.打包后程序运行时,JAR 文件 manifest 中的 program-class 属性会优先于 main-class 属性;对于 JAR manifest 中两个属性都不存在的情况,命令行和 web 界面支持手动传入类名参数;
4.使用 savepoints 时,应该考虑设置最大并行度,此设置会限定整个程序的并行度上限,当作业从一个 savepoint 恢复时,可以改变特定算子或者整个程序的并行度;
5.默认的最大并行度等于 operatorParallelism + (operatorParallelism / 2) 值四舍五入到大于等于该值的一个整型值,并且这个整型值是 2 的幂次方,默认最大并行度下限为 128,上限为 32768;
6.为最大并行度设置一个非常大的值将会降低性能,因为一些 state backends 需要维持内部的数据结构,而这些数据结构将会随着 key-groups 的数目而扩张(key-group 是状态重新分配的最小单元);
7.从之前的作业恢复时,改变该作业的最大并行度将会导致状态不兼容;
8.设置 Job 的并行度,可以从算子层面、执行环境层面、客户端层面(-P)、系统层面(flink-conf.yaml);
13、项目配置
1)概览
1.总结
1.可以使用 Maven 命令、CURL 命令、IDEA 手动创建 Flink 项目;
2.案例
a)Maven 命令
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.19.0
输入 groupId\artifactId\version\package
groupId: maven-flink-create
artifactId: my-flink-maven-test【项目文件夹名称】
version: 1.19
package: com.xu.maven.create.test【包名】

b)CURL 命令
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.19.0

2)使用 Maven
1.总结
1.可以使用 Maven Shade 插件将必需的依赖项打包进应用程序 jar 中;
2.应该在 Flink 集群的 lib 文件夹内配置需要的(核心)依赖项;
3.应该将程序中(核心)依赖项的生效范围置为 provided(需要对它们编译,但不应将它们打包进项目生成的应用程序 JAR 文件中),避免与集群一些依赖项的版本冲突;
2.案例
Maven shade 插件默认会包含所有生效范围是 “runtime” 或 “compile” 的依赖项。
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- Replace this with the main class of your job -->
<mainClass>my.programs.main.clazz</mainClass>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
3)连接器和格式
1.总结
1.flink-connector- 是一个精简 JAR,仅包括连接器代码,但不包含最终的第三方依赖项;flink-sql-connector- 是一个包含连接器第三方依赖项的 uber JAR;
2.uber/fat JAR 主要与 SQL 客户端一起使用,但也可以在任何 DataStream/Table 应用程序中使用它们;
3.某些连接器可能没有相应的 flink-sql-connector- 组件,因为它们不需要第三方依赖项。
4)高级配置
1.总结
1.Flink 发行版的 lib 目录里包括常用模块在内的各种 JAR 文件,若要禁止加载只需将它们从 classpath 中的 lib 目录中删除即可;
2.Flink 在 opt 文件夹下提供了额外的可选依赖项,可以通过移动这些 JAR 文件到 lib 目录来启用这些依赖项;
3.如果只使用 Flink 的 Java API,可以使用任何 Scala 版本;如果使用 Flink 的 Scala API,则需要选择与应用程序的 Scala 匹配的 Scala 版本;
4.2.12.8 之后的 Scala 版本与之前的 2.12.x 版本二进制不兼容,使 Flink 项目无法将其 2.12.x 版本直接升级到 2.12.8 以上;为此,需要在构建时添加 -Djapicmp.skip 以跳过二进制兼容性检查;
5.Flink 发行版默认包含执行 Flink SQL 任务的必要 JAR 文件(位于 lib 目录),但默认情况下不包含 Table Scala API,需手动添加;
6.要将 Flink 与 Hadoop 一起使用,需要有一个包含 Hadoop 依赖项的 Flink 系统,而不是添加 Hadoop 作为应用程序依赖项,通过
[export HADOOP_CLASSPATH=`hadoop classpath`] Flink 将使用 HADOOP_CLASSPATH 环境变量指定的 Hadoop 依赖项;
7.如果在 IDE 开发或测试期间需要 Hadoop 依赖项(用于 HDFS 访问),应该限定这些依赖项的使用范围(如 test 或 provided)。
2.案例
cat ~/.bashrc
----------------------------------------------------
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
export JAVA_HOME=/opt/hadoop/jdk1.8.0_131
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/hadoop/hadoop-3.0.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HIVE_HOME=/opt/hadoop/hive-3.1.2
export PATH=$HIVE_HOME/bin:$PATH
export FLINK_HOME=/opt/hadoop/flink-1.14.6
export PATH=$FLINK_HOME/bin:$PATH
export HADOOP_CLASSPATH=`hadoop classpath`
LC_ALL=zh_CN.UTF-8
export LANG=zh_CN.UTF-8
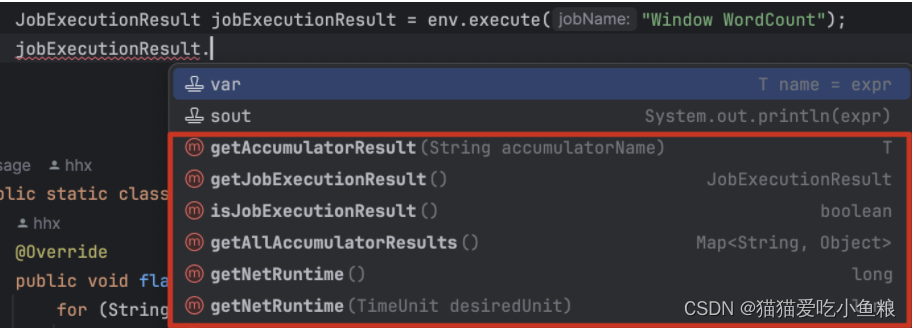




















![[每周一更]-(第106期):DNS和SSL协作模式](https://i-blog.csdnimg.cn/direct/38f1e4c3504746b7a64fa159260752ad.jpeg#pic_center)