python每日学习9:正则表达式
定义
- 在Python中,正则表达式是一种用于匹配字符串中字符组合的模式。它被广泛用于执行各种字符串搜索和替换任务。Python提供了内置的
re模块,用于处理正则表达式。
- 在Python中,正则表达式是一种用于匹配字符串中字符组合的模式。它被广泛用于执行各种字符串搜索和替换任务。Python提供了内置的
常用的元字符
- \d:匹配一个数字字符。等价于[0-9]。
- \D:匹配一个非数字字符。等价于非[0-9]。
- \s:匹配任何空白字符,包括空格、制表符、换页符等。等价于[\f\r\n\t\v]。
- \S:匹配任何非空白字符,包括空格、制表符、换页符等。等价于非[\f\r\n\t\v]。
- \w:匹配字母数字字符。
- \W:匹配非字母数字字符。
字符匹配
?:匹配前面的字符0次或1次。
*:匹配前面的字符0次或多次。
+:匹配前面的字符1次或多次。
. :匹配除’\n’之外的任何单个字符。使用[.\n]匹配包括\n的任何字符。
{n}表示n个字符,用{n,m}表示n~m个字符。
:将特殊字符转义。
A|B可以匹配A或B,所以(P|p)ython可以匹配’Python’或者’python’。
^:表示行的开头。
^\d:表示必须以数字开头。
$:表示行的结束。
\d$:表示必须以数字结束。
\d{3}表示匹配3个数字,例如'010' \s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配 '空格','空格空格','空格空格空格'等; \d{3,8}表示3-8个数字,例如'1234567','123','12345' 综上,该正则表达式可以匹配以任意个空格隔开的带三位区号的电话号码4 要匹配'010-12345'这样的号码,由于'-'是特殊字符,要用'\'转义,所以可用\d{3}\-\d{3,8}进行匹配。
复杂的正则表达式
常用方法
- [0-9a-zA-Z_]可以匹配一个数字、字母或者下划线。
- [0-9a-zA-Z_]+可以匹配至少由一个数字、字母或者下划线组成的字符串。
- [0-9a-zA-Z_]{0, 19}更精确地限制了长度是0-19个字符(最多19个字符)。
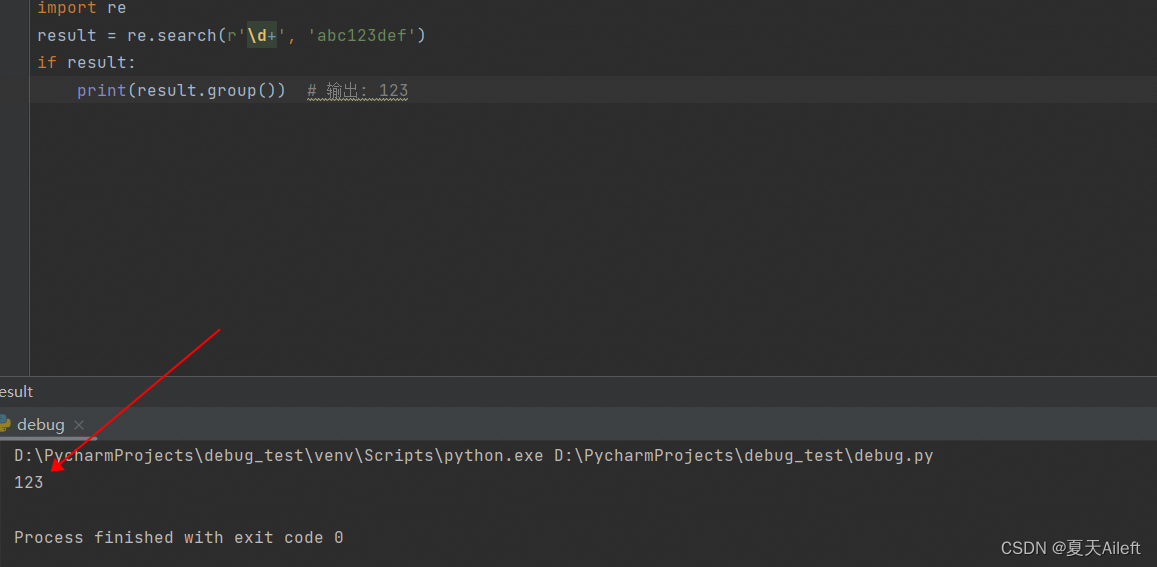
re模块
match方法
定义:match()方法判断是否匹配,如果匹配成功,返回一个Match对象,否则返回None(match方法通常会结合if选择结构进行判断)。
格式
import re 使用前需要先导入re模块 re.match(r'^\d{3}\-\d{3,8}$', '010-12345') 调用match方法,左边需要传入一个正则表达式,右边为待匹配的字符串 如果能匹配上则返回:<_sre.SRE_Match object; span=(0, 9), match='010-12345'> re.match(r'^\d{3}\-\d{3,8}$', '010 12345') 无法匹配则返回空,即None
切分字符串
re模块提供了split方法,可以按照指定的正则表达式进行字符串的切分。
#无论多少个空格都可以正常分割 import re m=re.split(r'\s+','a bb c') print(m)
分组
m=re.match(r'^(\d{3})\-(\d{3,8})$') m.group(0)#默认为0 全部读取 m.group(1)#读取第一个字串 m.group(2)#读取第二个字串 m.groups()#以列表的形式读取贪婪匹配
定义:正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。
re.match(r'^(\d+)(0*)$', '102300').groups() 最终结果:('102300', '')非贪婪匹配:就是尽可能少匹配。
re.match(r'^(\d+?)(0*)$', '102300').groups() 最终结果:('1023', '00')
编译
定义:如果一个正则表达式要重复使用几千次,出于效率的考虑,可以使用compile方法预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配。
import re # 导入模块 re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$') # 预编译 re_telephone.match('010-12345').groups() # 进行匹配并返回所有组 结果为:('010', '12345') re_telephone.match('010-8086').groups() # 进行匹配并返回所有组 结果为:('010', '8086')