下面是一个使用Python爬虫爬取视频的基本例子。创建一个Python爬虫来爬取视频通常涉及到几个步骤:发送HTTP请求、解析网页内容、提取视频链接、下载视频文件。
import json
import requests
from lxml import etree
if __name__ == '__main__':
# UA伪装
head = {
"User-Agent": "http://example.com/"
# 防盗链
, "Referer": "http://example.com/"
,
"Cookie": "http://example.com/"
}
# 1、指定url
url = "http://example.com/"
# 2、发送请求
response = requests.get(url, headers=head)
# 3、获取响应的数据
res_text = response.text
print(res_text)
#4.数据解析
tree = etree.HTML(res_text)
with open("bi.html","w",encoding="utf8") as f:
f.write(res_text)
base_info = "".join(tree.xpath("/html/head/script[4]/text()"))[20:]
print(base_info)
info_dict = json.loads(base_info)
print(info_dict)
video_url = info_dict["data"]["dash"]['video'][0]["baseUrl"]
audio_url = info_dict["data"]["dash"]['audio'][0]["baseUrl"]
video_content = requests.get(video_url,head).content
audio_content = requests.get(audio_url,head).content
with open("video.mp4","wb") as f:
f.write(video_content)
with open("audio.mp4","wb") as fp:
fp.write(audio_content)
pass
这段代码的主要目的是从网站获取一个视频的视频流和音频流,并将它们分别保存到本地文件中。下面是代码的详细解释:
1.导入必要的库:
json:用于处理JSON数据。
requests:用于发送HTTP请求。
lxml.etree:用于解析HTML和XML文档。
2.设置请求头:
创建一个字典head,包含模拟浏览器访问的User-Agent、防止防盗链的Referer以及一个示例的Cookie(注意,这里的User-Agent、Referer、Cookie仅仅只是样例)。
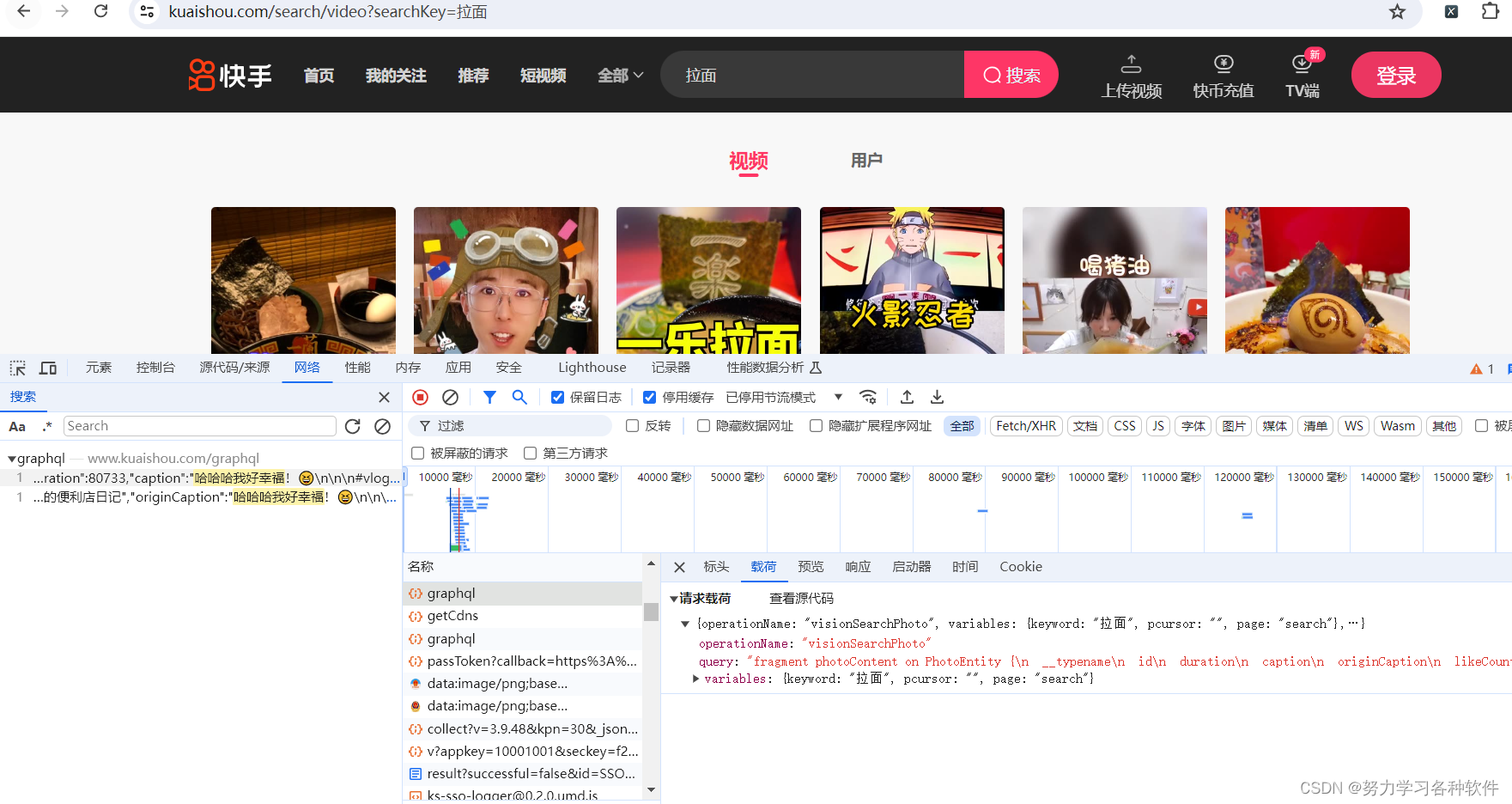
想要找到正确的User-Agent、防止防盗链的Referer以及一个示例的Cookie,可以通过打开电脑键盘F12,然后点击显示界面网络,找到名称一列的第一个项目,从标头里面可以找到相应的目标。
图例:

3.指定URL:
这里的url的获取方法同上。
4.发送请求:
使用requests.get方法发送HTTP GET请求到指定的URL,并将请求头设置为之前创建的head。(注意:请求方法可以通过类似url的获取方式查询)
图例:

5.获取响应数据:
从响应中获取HTML内容,并将其存储在变量res_text中。
打印整个HTML内容(这一步通常用于调试)。
6.保存HTML到文件:
将HTML内容写入到名为bi.html的文件中,用于后续分析或备份。
7.解析HTML以获取视频和音频信息:
使用lxml.etree解析HTML内容,并尝试从标签中的第四个
8.提取视频和音频的URL:
从解析后的字典中提取视频和音频的baseUrl。
9.下载视频和音频内容:
分别对视频和音频的URL发送GET请求,并将响应的内容(即视频和音频的二进制数据)保存到本地文件中。注意,这里将音频也保存为.mp4文件,但通常音频文件会使用.m4a、.aac或其他音频格式的文件扩展名。
注意:
硬编码的Cookie和直接从HTML中提取JSON字符串的方法(特别是通过指定