前言
本文是爬虫系列的第二篇文章,主要讲解关于爬虫的简单伪装,以及如何爬取B站的视频。建议先看完上一篇文章,再来看这一篇文章。要注意的是,本文介绍的方法只能爬取免费视频,会员视频是无法爬取的哦。
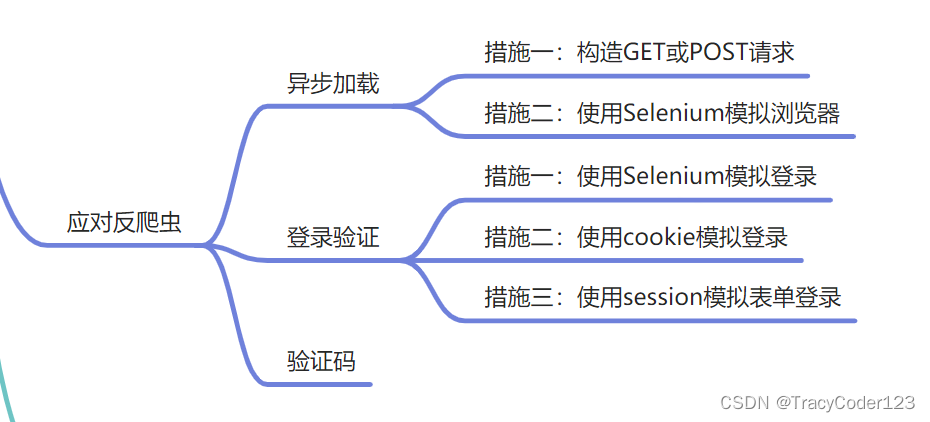
爬虫的伪装
1.为什么要伪装
有些网站会检查请求的合理性(比如B站),合理性具体包括以下三个指标:
user-agent 操作系统和浏览器的标识
cookie 用户标识
referer 引荐页
2.伪装格式
直接去网址的下面复制。
headers = {'user-agent': '留空', 'cookie': '留空', 'referer': '留空'}
3.如何骗过网址!
res = requests.get(url, headers=headers)
实战——爬取B站视频
找B站视频的链接
1.打开开发者工具–网络(network)–全部(all)–刷新网页。
2.点击大小(size) 让网络数据从大到小排列(因为视频往往比较大)
3.点击靠最前面的数据,标头(headers)中就有链接!

往下,就能看到User-Agent和Referer,把链接复制到代码中对应的“留空”位置即可。B站没有cookie,那就直接把cookie略去就行了。

代码如下,从四行代码变成了五行代码:
import requests
url = 'https://cn-sdjn-fx-01-08.bilivideo.com/upgcxcode/00/58/1599995800/1599995800_x1-1-100022.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1721210891&gen=playurlv2&os=bcache&oi=0&trid=0000df6fbda98be44d1d86bfe5fd4f5d5f2eu&mid=0&platform=pc&og=cos&upsig=b62735e5559ca1c4d91bac74f3ffdbd6&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform,og&cdnid=57408&bvc=vod&nettype=0&orderid=0,3&buvid=378D4A7A-2CFF-6786-15B0-D8AD9F8DB7C619803infoc&build=0&f=u_0_0&agrr=1&bw=7600&np=151339420&logo=80000000'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36', 'referer': 'https://www.bilibili.com/video/BV1N1421k7s6/?spm_id_from=333.1007.tianma.11-2-33.click'}
res = requests.get(url, headers=headers)
open('B站视频.mp4', 'wb').write(res.content)
注意,由于解码方式的不同,该视频使用电脑自带的视频播放工具不一定能打开。建议使用恒星播放器打开视频。
找B站音频的链接
打开视频之后,会发现视频没有声音。那是因为B站的视频和音频是分开存储的。所以还需要再下载音频。
在刚刚找视频数据的地方,下面还有好多条数据。此时数据是从大到小排列的,由于音频的大小往往也比较大,而且会比视频小,所以在下面找到除了第一条视频数据以外,重复出现几次的数据,那就是音频(下图选中的那一条便是我们要找的音频)。

音频只有网址和视频不一样,user-agent和referer都和视频一样,所以只需复制音频网址。
代码如下:
url = 'https://cn-sdjn-fx-01-10.bilivideo.com/upgcxcode/00/58/1599995800/1599995800-1-30216.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1721210891&gen=playurlv2&os=bcache&oi=0&trid=0000df6fbda98be44d1d86bfe5fd4f5d5f2eu&mid=0&platform=pc&og=hw&upsig=05fec34eb554b2d6eccbec9bda85f552&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform,og&cdnid=57410&bvc=vod&nettype=0&orderid=0,3&buvid=378D4A7A-2CFF-6786-15B0-D8AD9F8DB7C619803infoc&build=0&f=u_0_0&agrr=1&bw=3970&np=151339420&logo=80000000'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36', 'referer': 'https://www.bilibili.com/video/BV1N1421k7s6/?spm_id_from=333.1007.tianma.11-2-33.click'}
res = requests.get(url, headers=headers)
open('B站音频.mp3', 'wb').write(res.content)
注意打开的文件格式要从mp4改成mp3。
合成视频
现在我们有了没有声音的视频,和没有画面的音频,当然要把两者合成一个视频。这个工作可以通过各种视频剪辑软件完成,但其实python也可以完成这个工作。代码如下:
# 1.加载素材!
video = VideoFileClip('B站视频.mp4')
audio = AudioFileClip('B站音频.mp3')
# 2.剪辑视频!
final = video.set_audio(audio)
# 3.导出成品!
final.write_videofile('完整视频.mp4')
完整代码
这里给出完整代码:
import requests
url = 'https://cn-sdjn-fx-01-08.bilivideo.com/upgcxcode/00/58/1599995800/1599995800_x1-1-100022.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1721210891&gen=playurlv2&os=bcache&oi=0&trid=0000df6fbda98be44d1d86bfe5fd4f5d5f2eu&mid=0&platform=pc&og=cos&upsig=b62735e5559ca1c4d91bac74f3ffdbd6&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform,og&cdnid=57408&bvc=vod&nettype=0&orderid=0,3&buvid=378D4A7A-2CFF-6786-15B0-D8AD9F8DB7C619803infoc&build=0&f=u_0_0&agrr=1&bw=7600&np=151339420&logo=80000000'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36', 'referer': 'https://www.bilibili.com/video/BV1N1421k7s6/?spm_id_from=333.1007.tianma.11-2-33.click'}
res = requests.get(url, headers=headers)
open('B站视频.mp4', 'wb').write(res.content)
url = 'https://cn-sdjn-fx-01-10.bilivideo.com/upgcxcode/00/58/1599995800/1599995800-1-30216.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1721210891&gen=playurlv2&os=bcache&oi=0&trid=0000df6fbda98be44d1d86bfe5fd4f5d5f2eu&mid=0&platform=pc&og=hw&upsig=05fec34eb554b2d6eccbec9bda85f552&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform,og&cdnid=57410&bvc=vod&nettype=0&orderid=0,3&buvid=378D4A7A-2CFF-6786-15B0-D8AD9F8DB7C619803infoc&build=0&f=u_0_0&agrr=1&bw=3970&np=151339420&logo=80000000'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36', 'referer': 'https://www.bilibili.com/video/BV1N1421k7s6/?spm_id_from=333.1007.tianma.11-2-33.click'}
res = requests.get(url, headers=headers)
open('B站音频.mp3', 'wb').write(res.content)
from moviepy.editor import *
# 1.加载素材!
video = VideoFileClip('B站视频.mp4')
audio = AudioFileClip('B站音频.mp3')
# 2.剪辑视频!
final = video.set_audio(audio)
# 3.导出成品!
final.write_videofile('完整视频.mp4')
视频剪辑
python拥有15万+的库,可以实现非常多功能,做一些简单的视频剪辑不在话下。
比如对于刚刚获取的B站视频,我们可以截取其中10s-20s的视频,然后制作成镜像效果。
from moviepy.editor import *
video = VideoFileClip('完整视频.mp4') # 加载完整的视频
video1 = video.subclip(0, 10) # 切割0-10s的视频
video2 = video.subclip(10, 20) # 切割10-20s的视频
video3 = video.subclip(20, 30) # 切割20-30s的视频
# 包括原视频在内的4个镜像视频!
# video2
clip1 = video2.fx(vfx.mirror_x)
clip2 = video2.fx(vfx.mirror_y)
clip3 = clip2.fx(vfx.mirror_x)
final = clips_array([
[video2, clip1],
[clip2, clip3]
])
final.write_videofile('镜像视频.mp4')
原本第13秒的视频是这样的:

经过代码处理后的视频是这样的:

总结
本文在上一篇文章的基础上,进一步介绍了爬虫的功能。这次通过爬虫的伪装,成功下载到了B站的视频。还顺便介绍了一点使用python做视频剪辑的功能。