大规模语言模型从理论到实践:基于人类反馈的强化学习流程
作者:禅与计算机程序设计艺术 / Zen and the Art of Computer Programming
关键词:
大规模语言模型(LLMs)、强化学习(RL)、人类反馈(HF)、自然语言处理(NLP)、机器学习(ML)
1. 背景介绍
1.1 问题的由来
随着深度学习技术的飞速发展,大规模语言模型(LLMs)如BERT、GPT-3等在自然语言处理(NLP)领域取得了显著成果。然而,这些模型在复杂任务中的表现仍然不尽如人意,特别是在需要与人类交互或进行决策的场景下。为了解决这一问题,基于人类反馈的强化学习(HF-RL)成为了近年来研究的热点。
1.2 研究现状
HF-RL旨在通过人类反馈来指导强化学习过程,使模型能够更好地适应复杂任务和与人类交互。目前,HF-RL已在NLP、计算机视觉、游戏等领域取得了一定的成果。然而,HF-RL技术仍处于发展阶段,面临着诸多挑战。
1.3 研究意义
HF-RL技术对于提升LLMs在复杂任务中的表现具有重要意义。通过引入人类反馈,HF-RL能够使模型更好地理解人类意图,提高模型的鲁棒性和泛化能力。此外,HF-RL也有助于推动人工智能技术向通用人工智能(AGI)方向发展。
1.4 本文结构
本文将首先介绍HF-RL的核心概念和联系,然后详细阐述HF-RL的算法原理、操作步骤以及优缺点。接着,我们将通过数学模型和公式对HF-RL进行详细讲解,并结合案例进行分析。随后,我们将通过项目实践展示HF-RL的具体应用,并探讨其未来发展趋势与挑战。最后,本文将总结研究成果,并提出研究展望。
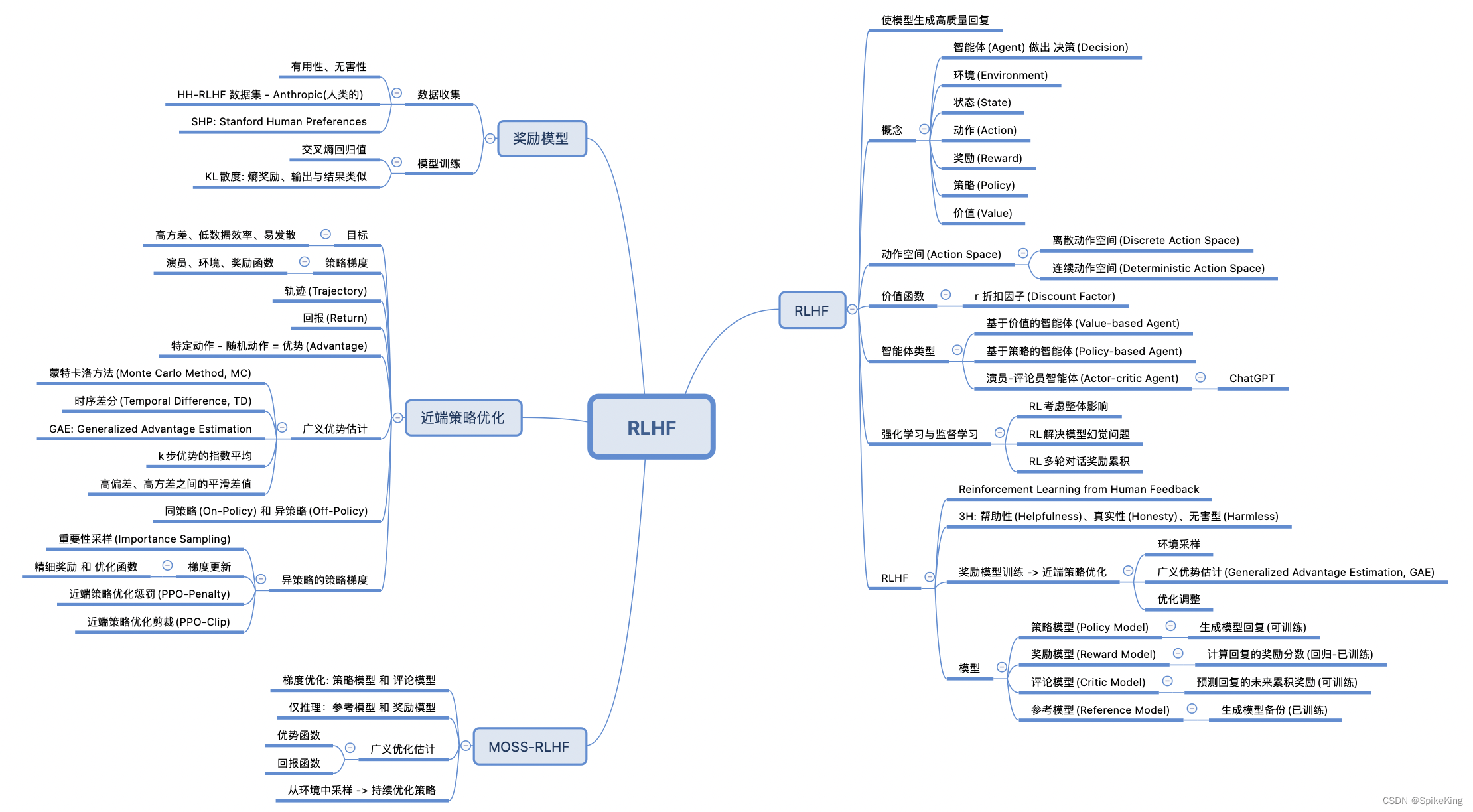
2. 核心概念与联系
2.1 强化学习(RL)
强化学习是一种机器学习方法,通过让智能体在与环境的交互中学习最优策略。在RL中,智能体通过观察环境状态、选择动作并获取奖励,不断优化其行为策略。
2.2 人类反馈(HF)
人类反馈是指从人类专家或用户处获取关于模型性能的意见和建议。HF在HF-RL中起到了关键作用,它能够引导模型学习更符合人类需求的策略。
2.3 大规模语言模型(LLMs)
LLMs是近年来在NLP领域取得显著成果的模型,如BERT、GPT-3等。LLMs在处理复杂语言任务时表现出色,但其在复杂场景中的表现仍需进一步提升。
2.4 联系
HF-RL结合了RL、HF和LLMs的优势,通过人类反馈指导LLMs在复杂任务中的学习过程,从而提升模型性能。
3. 核心算法原理 & 具体操作步骤
3.1 算法原理概述
HF-RL算法主要包含以下几个关键步骤:
- 环境构建:构建模拟实际应用场景的环境,使模型能够学习到真实场景下的行为策略。
- 智能体设计:设计能够执行动作、观察环境并获取奖励的智能体。
- 强化学习:利用强化学习算法指导智能体学习最优策略。
- 人类反馈:从人类专家或用户处获取关于模型性能的意见和建议,并用于指导强化学习过程。
3.2 算法步骤详解
3.2.1 环境构建
环境构建是HF-RL的第一步。我们需要根据实际应用场景设计一个能够反映任务特点的环境。例如,在NLP任务中,环境可以是一个文本生成系统,智能体通过生成文本并获取人类反馈来学习。
3.2.2 智能体设计
智能体是HF-RL中的核心组件,其目标是学习到最优策略。智能体通常由以下几部分组成:
- 状态空间:描述智能体当前所处状态的集合。
- 动作空间:描述智能体可以执行的动作集合。
- 策略:描述智能体在给定状态下选择动作的规则。
3.2.3 强化学习
强化学习算法用于指导智能体学习最优策略。常见的强化学习算法包括:
- Q-Learning:通过学习Q值函数来指导动作选择。
- Policy Gradient:通过学习策略参数来指导动作选择。
- 深度Q网络(DQN):结合深度学习技术,学习Q值函数。
3.2.4 人类反馈
人类反馈是HF-RL中不可或缺的一环。通过收集人类专家或用户的反馈,我们可以指导强化学习过程,使模型更好地满足人类需求。
3.3 算法优缺点
3.3.1 优点
- 适应性强:HF-RL能够根据人类反馈快速调整模型策略,适应不断变化的需求。
- 可解释性强:通过分析人类反馈,我们可以了解模型在哪些方面存在问题,从而指导模型改进。
- 泛化能力强:HF-RL能够帮助模型学习到更通用的策略,提高模型在未知场景下的表现。
3.3.2 缺点
- 数据依赖性:HF-RL需要大量的人类反馈数据,数据获取成本较高。
- 反馈质量:人类反馈的质量直接影响模型学习效果,如何有效获取高质量反馈是一个挑战。
- 计算复杂度:HF-RL涉及多个模块,计算复杂度较高。
3.4 算法应用领域
HF-RL在多个领域均有应用潜力,以下是一些典型应用:
- 自然语言处理:文本生成、机器翻译、问答系统等。
- 计算机视觉:图像分类、目标检测、视频理解等。
- 游戏:游戏AI、智能决策等。
- 其他领域:智能客服、智能交通、机器人控制等。
4. 数学模型和公式 & 详细讲解 & 举例说明
4.1 数学模型构建
HF-RL的数学模型主要包括以下几个部分:
- 状态空间( S ):描述智能体当前所处状态的集合。
- 动作空间( A ):描述智能体可以执行的动作集合。
- 策略( \pi ):描述智能体在给定状态下选择动作的规则,通常表示为( \pi(s) = P(a|s) )。
- 奖励函数( R ):描述智能体执行动作后获得的奖励,通常与目标函数相关。
- 价值函数( V ):描述智能体在给定状态下采取最优策略的期望奖励,通常表示为( V(s) = \max_{a \in A} \sum_{s' \in S} \gamma^{s'} R(s, a, s') )。
- 策略迭代( \pi_t ):第( t )次迭代时的策略。
4.2 公式推导过程
以下以Q-Learning为例,介绍HF-RL中的公式推导过程:
- 初始化Q值函数:随机初始化( Q(s, a) )。
- 选择动作:在给定状态( s )下,根据策略( \pi )选择动作( a )。
- 执行动作并获取奖励:执行动作( a ),获得奖励( r )并转移到状态( s' )。
- 更新Q值函数:根据新获得的奖励和目标函数,更新( Q(s, a) )。
- 迭代:重复步骤2-4,直至满足停止条件。
Q-Learning的更新公式如下:
$$ Q(s, a) \leftarrow Q(s, a) + \alpha [R(s, a, s') + \gamma \max_{a' \in A} Q(s', a') - Q(s, a)] $$
其中:
- ( \alpha )是学习率,控制Q值更新的幅度。
- ( \gamma )是折扣因子,控制未来奖励的权重。
4.3 案例分析与讲解
以下以机器翻译任务为例,说明HF-RL在NLP领域的应用。
- 环境构建:构建一个机器翻译环境,包括源文本和目标文本。
- 智能体设计:设计一个能够执行翻译动作、观察源文本和目标文本、获取人类反馈的智能体。
- 强化学习:使用Q-Learning算法指导智能体学习最优翻译策略。
- 人类反馈:收集人类专家对翻译结果的意见和建议,用于指导强化学习过程。
通过HF-RL,智能体可以不断调整翻译策略,提高翻译质量。
4.4 常见问题解答
4.4.1 HF-RL与其他机器学习方法的区别?
HF-RL是一种基于强化学习的方法,与传统的监督学习和无监督学习方法相比,HF-RL能够更好地适应复杂任务和与人类交互。此外,HF-RL可以利用人类反馈来指导学习过程,提高模型性能。
4.4.2 如何获取高质量的人类反馈?
获取高质量的人类反馈可以通过以下几种方式:
- 聘请专业领域的专家进行评估。
- 设计有效的评估指标,如BLEU、METEOR等,以便从大量数据中筛选出高质量反馈。
- 采用众包平台,如Amazon Mechanical Turk,收集大量用户的反馈。
5. 项目实践:代码实例和详细解释说明
5.1 开发环境搭建
首先,我们需要安装所需的库:
pip install torch transformers gym5.2 源代码详细实现
以下是一个基于PyTorch和Transformers的HF-RL项目示例:
import torch
import torch.nn as nn
import torch.optim as optim
from transformers import GPT2LMHeadModel, GPT2Tokenizer
from gym import spaces
import gym
import numpy as np
# 加载预训练模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 构建环境
class TranslationEnv(gym.Env):
def __init__(self):
super(TranslationEnv, self).__init__()
self.action_space = spaces.Discrete(512) # GPT2的词汇表大小
self.observation_space = spaces.Box(low=np.array([0.0]*512), high=np.array([1.0]*512), dtype=np.float32)
def step(self, action):
# 根据动作生成翻译
input_ids = tokenizer.encode("翻译:", return_tensors='pt')
input_ids = torch.cat([input_ids, action.unsqueeze(0)], dim=0)
output = model.generate(input_ids, max_length=30)
# 获取人类反馈
feedback = self.get_feedback(output)
reward = self.calculate_reward(feedback)
return output, reward, False, {}
def reset(self):
return torch.rand(1, 512)
def get_feedback(self, output):
# ...此处省略获取人类反馈的代码...
def calculate_reward(self, feedback):
# ...此处省略计算奖励的代码...
# 构建HF-RL模型
class HFRL(nn.Module):
def __init__(self, action_space_size):
super(HFRL, self).__init__()
self.model = model
self.action_space_size = action_space_size
self.fc = nn.Linear(action_space_size, action_space_size)
def forward(self, x):
return self.fc(x)
# 训练HF-RL模型
def train(model, env, optimizer, epochs=10):
for epoch in range(epochs):
state = env.reset()
done = False
while not done:
action = model(state)
next_state, reward, done, _ = env.step(action)
optimizer.zero_grad()
loss = -torch.log_softmax(model(next_state), dim=-1)[0].gather(1, action).mean()
loss.backward()
optimizer.step()
state = next_state
# 创建环境、模型和优化器
env = TranslationEnv()
model = HFRL(env.action_space.n)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
train(model, env, optimizer)
# 评估模型
state = env.reset()
done = False
while not done:
action = model(state)
_, _, done, _ = env.step(action)
print(tokenizer.decode(action, skip_special_tokens=True))5.3 代码解读与分析
- TranslationEnv类:定义了机器翻译环境,包括动作空间、状态空间、步骤函数、重置函数等。
- HFRL类:定义了HF-RL模型,包括GPT2模型和全连接层。
- train函数:用于训练HF-RL模型。
- 评估模型:在训练完成后,我们可以使用模型生成翻译结果,并打印输出。
5.4 运行结果展示
运行上述代码,我们可以看到模型生成的翻译结果。通过不断训练和优化,模型的翻译质量将不断提高。
6. 实际应用场景
HF-RL在多个领域均有应用潜力,以下是一些典型应用:
6.1 自然语言处理
- 机器翻译:利用HF-RL技术,模型可以学习到更符合人类需求的翻译策略,提高翻译质量。
- 文本生成:利用HF-RL技术,模型可以生成更符合人类需求的文本内容,如新闻报道、小说、诗歌等。
- 问答系统:利用HF-RL技术,模型可以更好地理解用户问题,并给出更准确的答案。
6.2 计算机视觉
- 图像分类:利用HF-RL技术,模型可以学习到更符合人类需求的分类策略,提高分类准确率。
- 目标检测:利用HF-RL技术,模型可以更好地识别和定位目标,提高检测精度。
- 视频理解:利用HF-RL技术,模型可以更好地理解视频内容,提取关键信息。
6.3 游戏
- 游戏AI:利用HF-RL技术,模型可以学习到更符合人类玩家策略的游戏策略,提高游戏水平。
- 智能决策:利用HF-RL技术,模型可以在游戏中做出更合理的决策,提高游戏表现。
6.4 其他领域
- 智能客服:利用HF-RL技术,模型可以更好地理解用户问题,并给出更准确的解答。
- 智能交通:利用HF-RL技术,模型可以优化交通信号灯控制,提高道路通行效率。
- 机器人控制:利用HF-RL技术,模型可以优化机器人运动策略,提高机器人作业效率。
7. 工具和资源推荐
7.1 学习资源推荐
- 书籍:
- 《深度学习》
- 《强化学习》
- 在线课程:
- Coursera: Deep Learning Specialization
- Udacity: Deep Learning Nanodegree
- fast.ai: Practical Deep Learning for Coders
7.2 开发工具推荐
- PyTorch:深度学习框架,适用于构建和训练模型。
- Transformers:基于PyTorch的NLP库,提供了多种预训练模型和工具。
- Gym:开源的强化学习环境库。
7.3 相关论文推荐
- 《Human-level language understanding with a pre-trained language model》
- 《The State of Reinforcement Learning》
- 《Deep Learning for NLP without a PhD》
7.4 其他资源推荐
- GitHub:开源代码和项目资源。
- arXiv:最新学术论文。
8. 总结:未来发展趋势与挑战
HF-RL技术从理论到实践,在多个领域展现出巨大的潜力。然而,HF-RL仍面临一些挑战和未来的发展趋势:
8.1 研究成果总结
- HF-RL技术能够有效提升LLMs在复杂任务中的表现,提高模型的适应性和可解释性。
- HF-RL在自然语言处理、计算机视觉、游戏等领域取得了显著成果。
- HF-RL技术有助于推动人工智能技术向通用人工智能(AGI)方向发展。
8.2 未来发展趋势
- 多模态学习:将HF-RL与其他模态学习技术相结合,实现跨模态信息的理解和生成。
- 自监督学习:利用自监督学习技术,减少对标注数据的依赖,降低数据获取成本。
- 可解释性:提高HF-RL模型的可解释性,使模型决策过程更加透明可信。
8.3 面临的挑战
- 数据获取:高质量人类反馈数据的获取成本较高,且难以保证数据质量。
- 计算复杂度:HF-RL涉及多个模块,计算复杂度较高,对计算资源要求较高。
- 模型泛化能力:如何提高HF-RL模型的泛化能力,使其在未知场景下表现良好。
8.4 研究展望
HF-RL技术在未来将迎来更多的发展机遇。通过不断创新和突破,HF-RL将为人工智能技术带来更多可能性,助力人工智能向通用人工智能(AGI)方向发展。
9. 附录:常见问题与解答
9.1 什么是HF-RL?
HF-RL是一种结合了强化学习、人类反馈和大规模语言模型的技术,旨在提升LLMs在复杂任务中的表现。
9.2 HF-RL与传统的强化学习有何区别?
HF-RL在传统的强化学习基础上引入了人类反馈,使得模型能够更好地适应复杂任务和与人类交互。
9.3 如何获取高质量的人类反馈?
获取高质量的人类反馈可以通过以下几种方式:
- 聘请专业领域的专家进行评估。
- 设计有效的评估指标,如BLEU、METEOR等,以便从大量数据中筛选出高质量反馈。
- 采用众包平台,如Amazon Mechanical Turk,收集大量用户的反馈。
9.4 HF-RL的应用前景如何?
HF-RL在自然语言处理、计算机视觉、游戏等领域具有广泛的应用前景,有助于推动人工智能技术向通用人工智能(AGI)方向发展。
9.5 HF-RL的未来发展趋势是什么?
HF-RL的未来发展趋势包括:
- 多模态学习:将HF-RL与其他模态学习技术相结合,实现跨模态信息的理解和生成。
- 自监督学习:利用自监督学习技术,减少对标注数据的依赖,降低数据获取成本。
- 可解释性:提高HF-RL模型的可解释性,使模型决策过程更加透明可信。