在民航生成式语言模型的预训练、对齐训练和人类反馈强化学习(RLHF)阶段,都需要精心准备和选择数据集。下面是每个阶段可能需要的数据集和一般的要求:
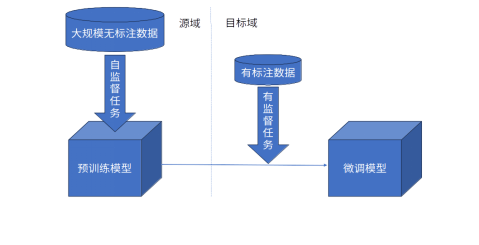
预训练阶段
数据集:
- 通用语料库:如维基百科、Common Crawl、Gutenberg 电子书等。
- 新闻文章:涵盖多个领域和主题的新闻报道。
- 社交媒体文本:如推文、论坛帖子等,以学习非正式语言和流行语。
- 对话数据:如对话语料库、聊天记录等,以学习对话模式。
- 民航专业数据:包括航班信息、安全报告、操作手册、航空法规等。
硬件要求: - 8张H100显卡进行fp16训练。
训练时间: - 取决于模型大小、数据集大小、batch size等。可能需要数周至数月不等。
对齐训练阶段
数据集:
- 领域特定的问答数据:针对民航领域的问题和答案对。
- 文本分类数据:用于分类航班信息、安全事件等。
- 文本生成数据:用于生成报告、摘要等。
硬件要求: - 4张H100显卡进行fp16训练。
训练时间: - 通常需要较短的训练时间,可能为数天至数周。
人类反馈强化学习(RLHF)阶段
数据集:
- 人类提供的偏好数据:人类评估者对模型输出质量的评分。
- 指令遵循数据:指令和对应的正确响应。
- 人类编写的示例数据:用于指导模型生成高质量输出。
数据集结构: - 标签化数据:每个数据点都有对应的标签或评分。
- 对话式数据:包含指令和响应的对话数据。
- 文本生成数据:包含输入和期望的生成文本。
硬件要求: - RLHF通常需要较少的显卡,因为它涉及到迭代的策略改进,而不是大规模的数据训练。具体数量取决于模型大小和训练效率。
训练时间: - RLHF阶段的时间可能相对较短,但需要多次迭代来优化模型。可能为数天至数周。
请注意,上述时间估计非常粗略,实际训练时间会受到许多因素的影响,包括模型的复杂性、数据集的大小、训练的epoch数量、优化器的选择等。在实际操作中,您需要根据具体的实验结果来调整训练策略和时间安排。此外,由于模型训练是一个动态调整的过程,您可能需要根据模型的性能和资源情况灵活调整硬件配置。