大模型赋能网络爬虫
简单来说,网页抓取就是从网站抓取数据和内容,然后将这些数据保存为XML、Excel或SQL格式。除了用于生成潜在客户、监控竞争对手和市场研究外,网页抓取工具还可以用于自动化你的数据收集过程。
借助AI网页抓取工具,可以解决手动或纯基于代码的抓取工具的限制:动态或非结构化的网站可以轻松处理,所有这些都无需人工干预。
在这里,我们介绍一些可供选择的开源AI网页抓取工具。
Reader

Reader 是 Jina AI 提供的一个工具。你可以通过添加一个简单的 https://r.jina.ai/ 将任何URL转换为LLM友好的输入,并且你可以免费为你的代理和RAG系统获取结构化输出。
自从上个月(确切地说是4月15日)首次发布以来,他们已经从世界各地处理了超过1800万次请求,该项目本身已经获得了4.5K星标。
使用方式很简单,就是在 https://r.jina.ai/ 后面跟上你要抓取的URL即可
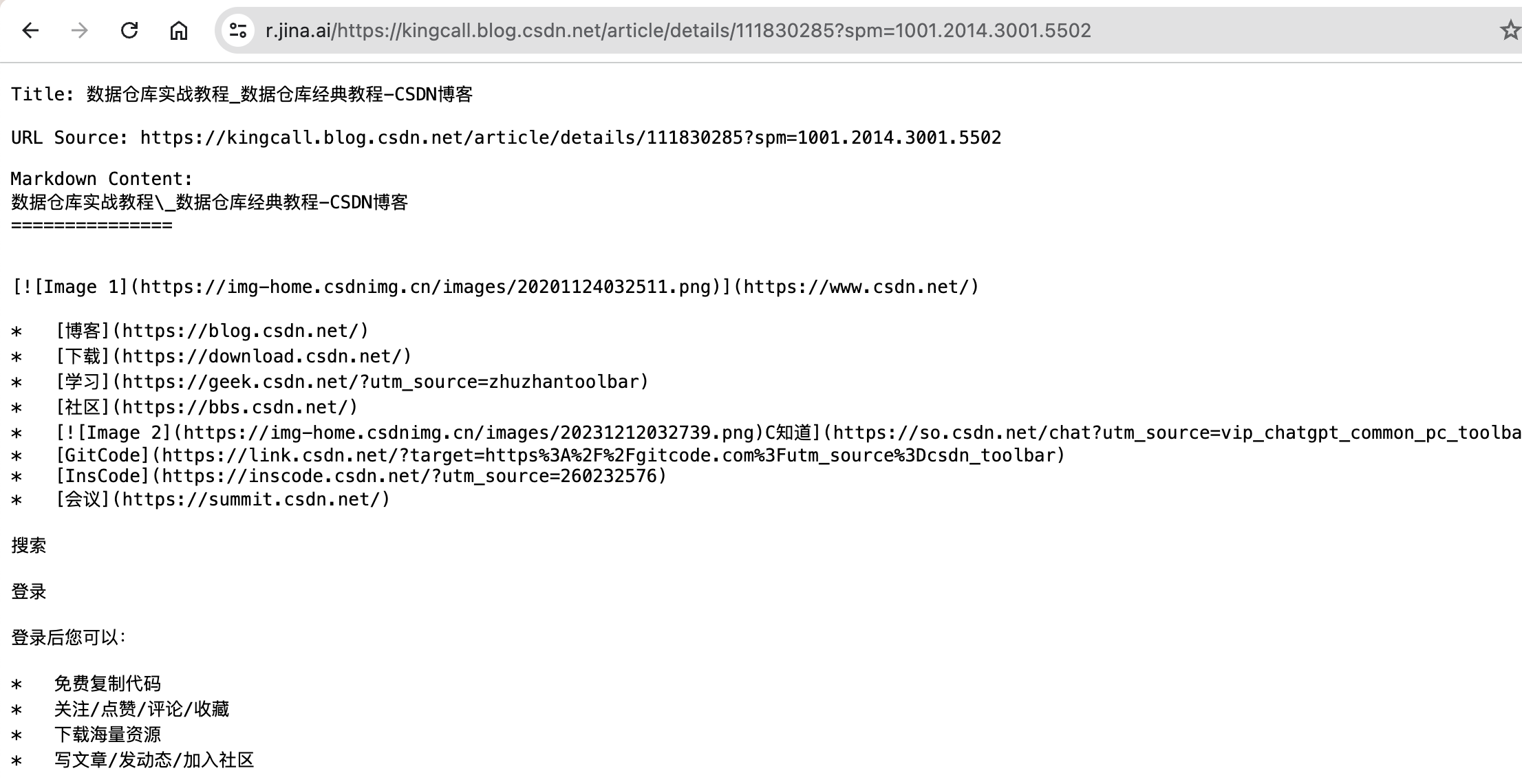
除了抓取任何URL,Jina刚刚发布了另一个功能,你可以使用 https://s.jina.ai/YOUR_SEARCH_QUERY 来从互联网上获取最新的知识。结