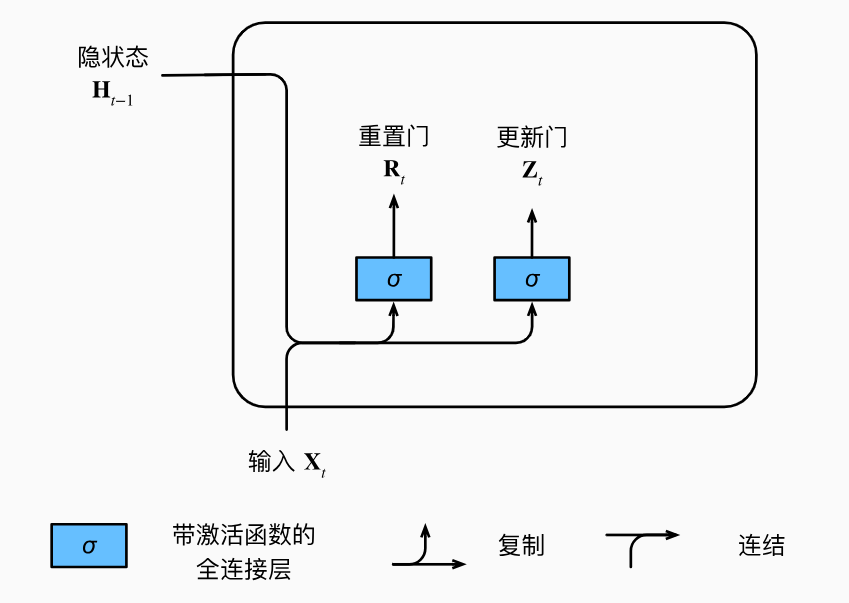
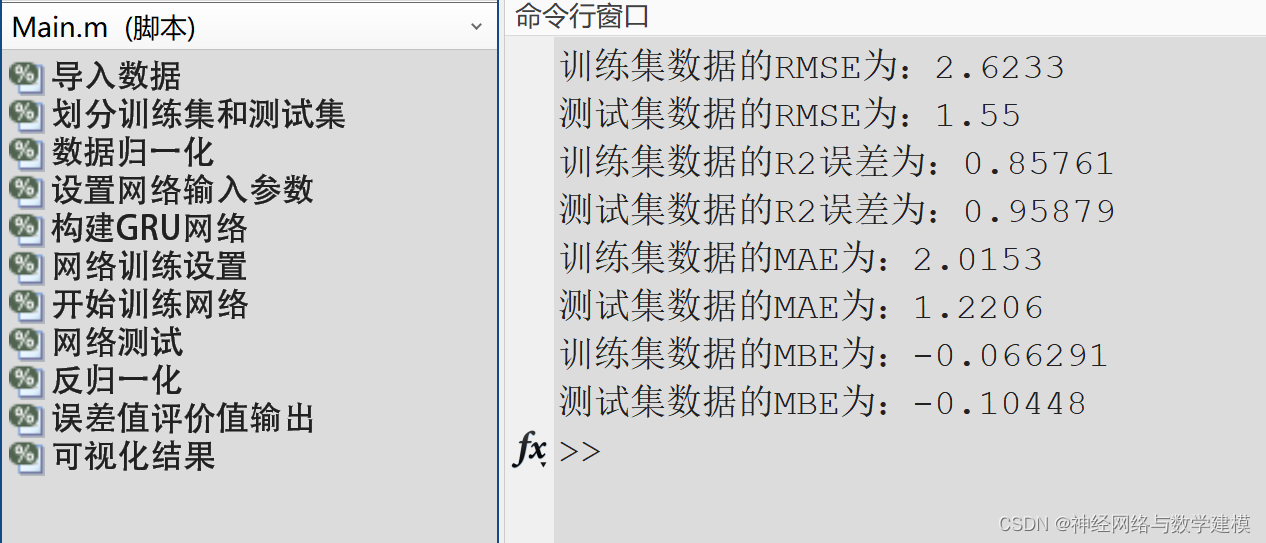
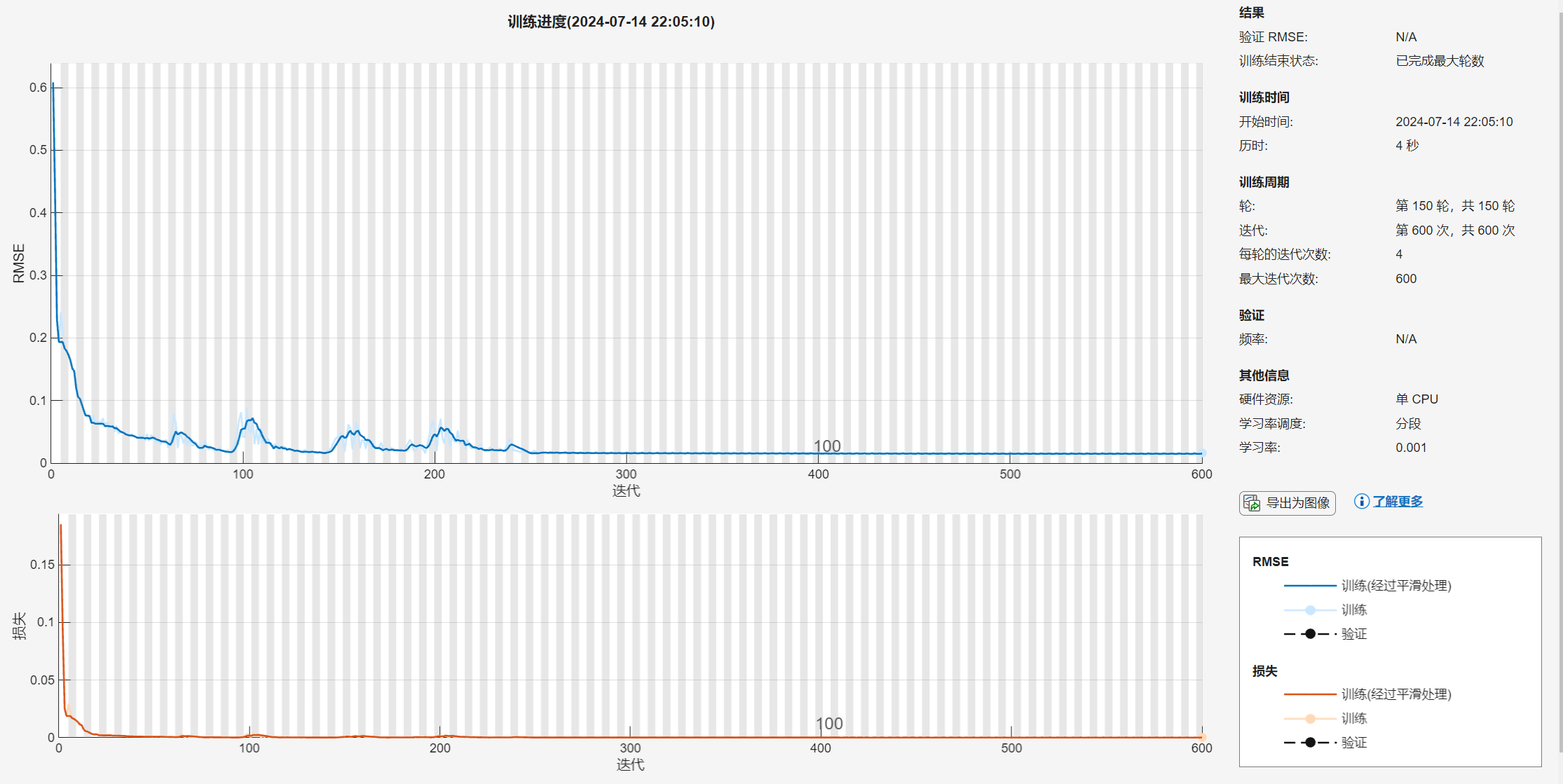
门控循环单元(Gated Recurrent Unit,简称GRU)是一种常用于处理序列数据的循环神经网络(RNN)变种。GRU模型结合了长短时记忆网络(LSTM)和标准循环神经网络的优点,通过门控机制帮助网络更好地捕捉长期依赖关系,同时减少参数数量和计算成本。
门控循环单元的背景源于RNN在处理长序列数据时的困难。传统RNN容易受到梯度消失或梯度爆炸的问题影响,导致难以捕捉序列中的长期依赖关系。为了解决这一挑战,LSTM被提出并取得了成功,但其复杂的门控机制也增加了计算成本。GRU由Cho等人于2014年提出,在保持简单性的基础上,引入了更新门和重置门来控制信息流动,使得网络在长序列数据上更容易训练。
GRU模型的原理主要包括更新门和重置门。更新门控制前一个时间步的记忆状态被保留还是更新,以便网络能够灵活地记忆或遗忘信息。重置门则帮助网络决定如何结合当前输入和前一个时间步的隐藏状态,以便更好地适应当前序列信息。通过这些门控机制,GRU能够自适应地调整信息流,从而更好地学习序列数据中的模式和关系。
实现门控循环单元(GRU)模型涉及以下几个关键步骤。首先,需要定义网络结构,包括输入层、隐藏层和输出层的结构,以及更新门和重置门的参数。其次,需要初始化网络参数,通常使用随机初始化方法。然后,在进行前向传播时,通过更新门和重置门的计算来更新记忆状态和隐藏状态,并输出相应的预测结果。最后,通过反向传播算法来计算网络误差,并利用梯度下降等方法更新网络参数,以最小化损失函数。
总的来说,门控循环单元(GRU)模型作为一种优秀的序列建模工具,在自然语言处理、语音识别、时间序列预测等领域都得到了广泛应用。通过灵活的门控机制,GRU能够更好地捕捉输入序列中的长期依赖关系,同时具有较少的参数数量和计算成本,使其成为处理序列数据的有力工具。
以下是使用TensorFlow Keras API构建GRU模型进行预测的简单示例:
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import GRU, Dense
# 生成虚拟数据
def generate_data(n_steps):
X = np.array([0.1 * i for i in range(n_steps)])
y = np.sin(X)
return X, y
n_steps = 20
X, y = generate_data(n_steps)
# 将输入序列重塑为适合GRU模型的格式
X = X.reshape(1, n_steps, 1)
# 定义GRU模型
model = Sequential()
model.add(GRU(50, activation='relu', input_shape=(n_steps, 1)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
# 训练模型
model.fit(X, y, epochs=100, verbose=0)
# 使用模型进行序列预测
y_pred = model.predict(X)
# 打印预测结果
print(y_pred)
在TensorFlow中,可以使用Keras API构建一个GRU模型进行序列分类。以下是一个简单的示例代码:
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import GRU, Dense
# 生成虚拟数据
def generate_data(n_samples, n_steps, n_features, n_classes):
X = np.random.randn(n_samples, n_steps, n_features)
y = np.random.randint(0, n_classes, n_samples)
return X, y
n_samples = 100
n_steps = 50
n_features = 10
n_classes = 3
X, y = generate_data(n_samples, n_steps, n_features, n_classes)
# 定义GRU模型
model = Sequential()
model.add(GRU(50, activation='relu', input_shape=(n_steps, n_features)))
model.add(Dense(n_classes, activation='softmax'))
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X, y, epochs=10, batch_size=32)
# 评估模型
loss, accuracy = model.evaluate(X, y)
print('Test loss:', loss)
print('Test accuracy:', accuracy)