本文章是我在进行深度学习时做的数据增强,接着我们上期的划分测试集和训练集来做.
文章目录
前言
很多人在深度学习的时候在对数据的处理时一般采用先数据增强在进行对训练集和测试集的划分,其实我感觉这样做还是有点不好的,其实这里也是分情况的.
1.如果你的数据集很少每个类别很少,我建议先进行数据增强,后进行训练集和测试集的划分还是可以的,但要注意也是因为你的数据集很小,所以有必要对你的模型进行k-折交叉验证.
2.如果你的数据量还可以的话,我建议先划分测试集和训练集,之后再进行数据增强,再训练的时候再对你的增强后的数据再进行训练和验证集的划分,这是因为你先进行数据增强后划分训练集和测试集,很有可能将你的测试集信息透露给了训练集,这样模型感觉很不错,但最后投入到实际就拉跨了,如果你想模型感觉很好的话当我没说,当然可以先数据增强在划分很多人也是这么干的.
3.如果你的数据量非常的大,那基本上也不用数据增强了,这一点还是要根据实际的情况.
数据增强有什么好处?
正确使用数据增强能够带来如下好处:
- 降低数据采集和数据标记的成本
- 通过赋予模型更多的多样性和灵活性来改进模型泛化
- 提高模型在预测中的准确性,因为它使用更多数据来训练模型
- 减少数据的过拟合
- 通过增加少数类中的样本来处理数据集中的不平衡
一、构造数据增强函数
我们使用opencv对我们的数据进行数据增强
1.添加椒盐噪声
2.高斯噪声
3.昏暗
4.亮度
5.旋转翻转
# -*- coding: utf-8 -*-
import cv2
import numpy as np
import os.path
import copy
# 椒盐噪声
def SaltAndPepper(src,percetage):
SP_NoiseImg=src.copy()
SP_NoiseNum=int(percetage*src.shape[0]*src.shape[1])
for i in range(SP_NoiseNum):
randR=np.random.randint(0,src.shape[0]-1)
randG=np.random.randint(0,src.shape[1]-1)
randB=np.random.randint(0,3)
if np.random.randint(0,1)==0:
SP_NoiseImg[randR,randG,randB]=0
else:
SP_NoiseImg[randR,randG,randB]=255
return SP_NoiseImg
# 高斯噪声
def addGaussianNoise(image,percetage):
G_Noiseimg = image.copy()
w = image.shape[1]
h = image.shape[0]
G_NoiseNum=int(percetage*image.shape[0]*image.shape[1])
for i in range(G_NoiseNum):
temp_x = np.random.randint(0,h)
temp_y = np.random.randint(0,w)
G_Noiseimg[temp_x][temp_y][np.random.randint(3)] = np.random.randn(1)[0]
return G_Noiseimg
# 昏暗
def darker(image,percetage=0.9):
image_copy = image.copy()
w = image.shape[1]
h = image.shape[0]
#get darker
for xi in range(0,w):
for xj in range(0,h):
image_copy[xj,xi,0] = int(image[xj,xi,0]*percetage)
image_copy[xj,xi,1] = int(image[xj,xi,1]*percetage)
image_copy[xj,xi,2] = int(image[xj,xi,2]*percetage)
return image_copy
# 亮度
def brighter(image, percetage=1.5):
image_copy = image.copy()
w = image.shape[1]
h = image.shape[0]
#get brighter
for xi in range(0,w):
for xj in range(0,h):
image_copy[xj,xi,0] = np.clip(int(image[xj,xi,0]*percetage),a_max=255,a_min=0)
image_copy[xj,xi,1] = np.clip(int(image[xj,xi,1]*percetage),a_max=255,a_min=0)
image_copy[xj,xi,2] = np.clip(int(image[xj,xi,2]*percetage),a_max=255,a_min=0)
return image_copy
# 旋转
def rotate(image, angle, center=None, scale=1.0):
(h, w) = image.shape[:2]
# If no rotation center is specified, the center of the image is set as the rotation center
if center is None:
center = (w / 2, h / 2)
m = cv2.getRotationMatrix2D(center, angle, scale)
rotated = cv2.warpAffine(image, m, (w, h))
return rotated
# 翻转
def flip(image):
flipped_image = np.fliplr(image)
return flipped_image
二、数据增强
from PIL import Image, ImageEnhance
import os
import random
import shutil
def augment_image(image_path, save_path):
img = cv2.imread(image_path)
image_name = os.path.basename(image_path) # 获取图片名称
split_result = image_name.split('.')
name = split_result[:-1]
extension = split_result[-1]
# cv2.imshow("1",img)
# cv2.waitKey(5000)
# 旋转
rotated_90 = rotate(img, 90)
cv2.imwrite(save_path + "".join(name) + '_r90.'+ extension, rotated_90)
rotated_180 = rotate(img, 180)
cv2.imwrite(save_path + "".join(name) + '_r180.'+ extension, rotated_180)
flipped_img = flip(img)
cv2.imwrite(save_path + "".join(name) + '_fli.'+ extension, flipped_img)
# 增加噪声
# img_salt = SaltAndPepper(img, 0.3)
# cv2.imwrite(save_path + img_name[0:7] + '_salt.jpg', img_salt)
img_gauss = addGaussianNoise(img, 0.3)
cv2.imwrite(save_path + "".join(name) + '_noise.'+ extension,img_gauss)
#变亮、变暗
img_darker = darker(img)
cv2.imwrite(save_path + "".join(name) + '_darker.'+ extension, img_darker)
img_brighter = brighter(img)
cv2.imwrite(save_path + "".join(name) + '_brighter.'+ extension, img_brighter)
blur = cv2.GaussianBlur(img, (7, 7), 1.5)
# cv2.GaussianBlur(图像,卷积核,标准差)
cv2.imwrite(save_path + "".join(name) + '_blur.'+ extension,blur)
target_num = 2000 # 目标增强图片数量
image_folder = 'D:/plantsdata/data/train/' # 图片文件夹路径
save_folder = 'D:/plantsdata/data/train_with_augmentation/' # 保存增强后的图片的文件夹路径# 获取所有类别的文件夹路径
class_folders = os.listdir(image_folder)
# 遍历类别文件夹
for class_folder in class_folders:
if not os.path.isdir(os.path.join(image_folder, class_folder)):
continue
target_subfolder = os.path.join(save_folder,class_folder)
os.makedirs(target_subfolder, exist_ok=True)
image_list = os.listdir(os.path.join(image_folder, class_folder))
# 获取当前文件夹中所有图片的路径
images = []
for file_name in image_list:
images.append(os.path.join(image_folder, class_folder, file_name))
num_images = len(images)
print(num_images)
print(target_num)
if num_images < target_num:
for image_path in images:
with Image.open(image_path) as img:
name = os.path.basename(image_path)
target_path = os.path.join(target_subfolder, name)
shutil.copy(image_path, target_path)
i = num_images
j = 0
random_image = random.sample(image_list,k=num_images)
while i<target_num and j<=num_images-1:
image_path = os.path.join(image_folder, class_folder, random_image[j])
target_path = target_subfolder + '/'
augment_image(image_path, target_path)
i+=7
j+=1
print(i)
else:
# 随机选择2000张图片
selected_images = random.sample(images,k=2000)
# 将选中的图片复制到目标文件夹
for image_path in selected_images:
with Image.open(image_path) as img:
name = os.path.basename(image_path)
target_path = os.path.join(target_subfolder, name)
shutil.copy(image_path, target_path)数据增强将文件夹中的每个类别的文件夹中的图片数据首先复制到目标文件夹,如果大于2000张随机挑选2000张图片复制,不够的画在进行数据增强,目标每个类别2000张,如果类别文件夹的图片数量太小,那就缩小目标数目,或者在找些图片.
三、查看数据分布情况
import os
import matplotlib.pyplot as plt
def count_photos_in_categories(folder_path):
count_dict = {}
for root, dirs, files in os.walk(folder_path):
category = os.path.basename(root)
count_dict.setdefault(category, 0)
for file in files:
count_dict[category] += 1
return count_dict
folder1 = "D:/plantsdata/data/train/"
folder2 = "D:/plantsdata/data/train_with_augmentation/"
count1 = count_photos_in_categories(folder1)
count2 = count_photos_in_categories(folder2)
categories = sorted(set(count1.keys()).union(set(count2.keys())))
x = range(-1, len(categories)-1) # 从1开始编号
width = 0.35
fig, ax = plt.subplots(figsize=(12, 6),dpi = 400)
rects1 = ax.bar(x, [count1.get(category, 0) for category in categories], width, label='train_without_augmentation')
rects2 = ax.bar([i + width for i in x], [count2.get(category, 0) for category in categories], width, label='train_with_augmentation')
ax.set_ylabel('Photo Count')
ax.set_xlabel('Category')
ax.set_title('Comparison of Photo Counts in Different Categories')
ax.set_xticks([i + width/2 for i in x])
ax.set_xticklabels(x)
# ax.set_xticklabels(categories)
ax.set_xlim(-0.5, len(categories)-1)
ax.legend()
plt.show()
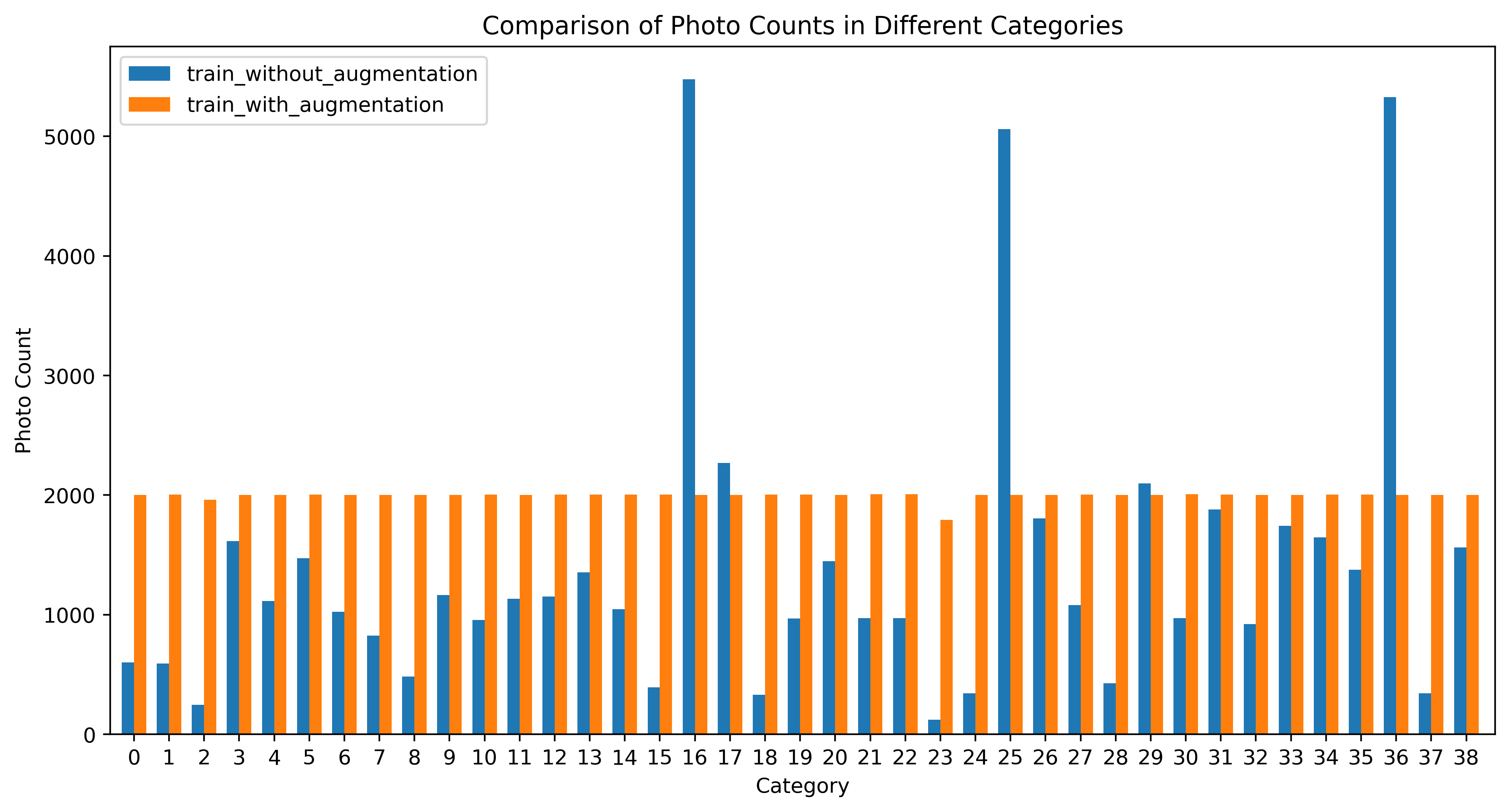
这样我们就分好啦!
总结
对数据增强的代码,帮助大家从文件夹中对图片进行处理,本文的图片增强的代码就举例几个,大家可以在搜寻图像增强的方法加入函数即可.




























![[软件工具][windows]yolov8自动标注工具自动打标签工具](https://img-blog.csdnimg.cn/direct/f217a3116a494b7c9907a3157a1037af.jpeg)