| 『大模型笔记』LLM秘密:温度、Top-K和Top-P抽样技术解析! |
文章目录
一. LLM秘密:温度、Top-K和Top-P随机采样技术解析!
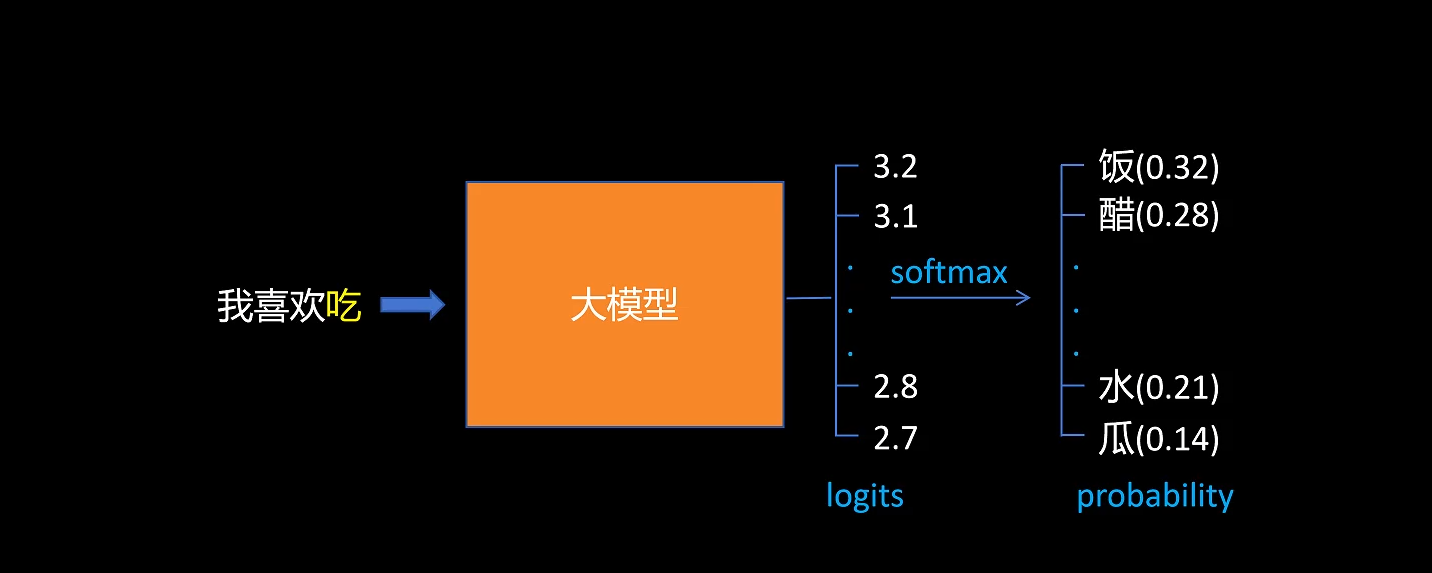
嗨,大家好!今天我们将学习 大语言模型中的随机采样技术,这是一个关键算法,我们还将探讨三个重要的辅助技术:温度(Temperature)、TopK和TopP采样。首先,让我们回顾一下大语言模型是如何生成文本的。简单来说,它们通过自回归方式生成文本,即在每个步骤生成一个Token时,利用一定窗口内的前几个Token的信息,为每个单词创建一个概率分布,从中选择当前步骤的最佳候选词。
通常,我们可以简单地选择概率最高的单词,这种方法被称为 贪婪解码(greedy decoding)。例如,对于句子“today the weather is”,会选择单词“sunny”。然而,这种方法往往会导致输出过于确定和重复,这在某些需要精确结果的情况下是有用的,比如语音识别系统的语音转录。
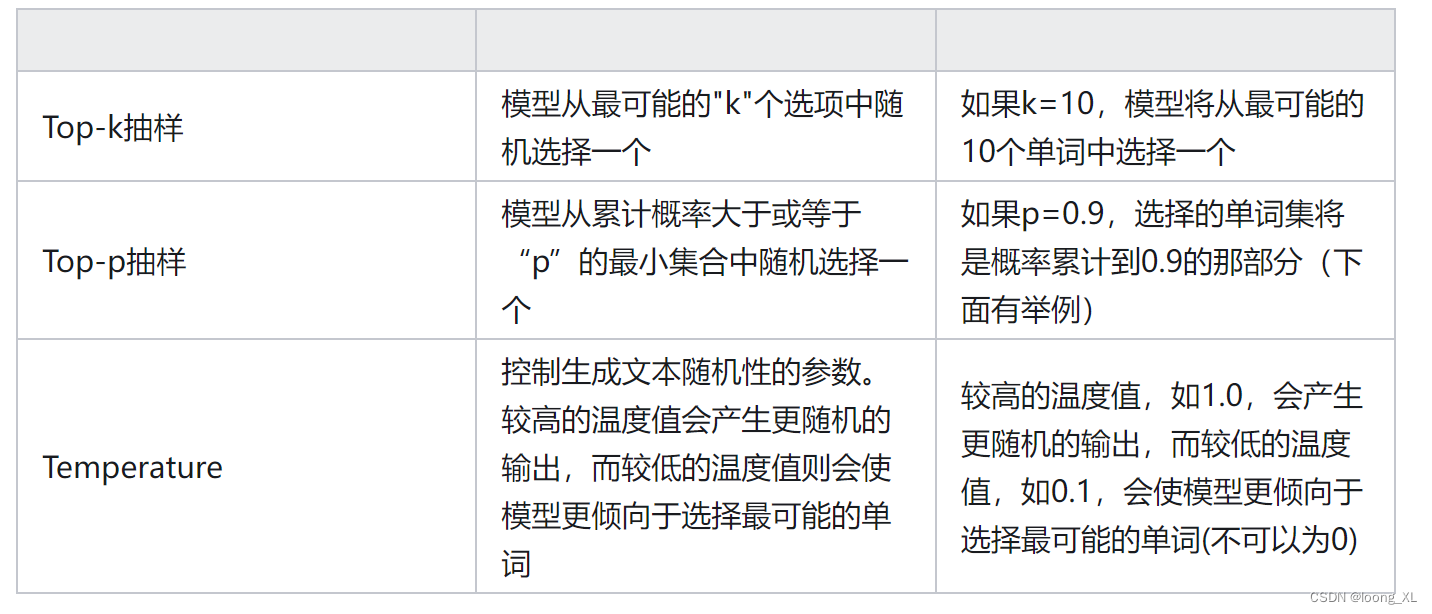
但在大语言模型中,我们的目标往往是生成具有一定创造性的输出。这些模型被设计用来捕捉和再现人类语言的复杂性,其中多样性和原创性是很重要的。通过温度、TopK和TopP
![[<span style='color:red;'>LLM</span>]<span style='color:red;'>大</span>语言<span style='color:red;'>模型</span>文本生成—解码策略(<span style='color:red;'>Top</span>-<span style='color:red;'>k</span> & <span style='color:red;'>Top</span>-<span style='color:red;'>p</span> & Temperature)](https://img-blog.csdnimg.cn/direct/7ec10941a7fa4426992cc5309b6789c4.png)