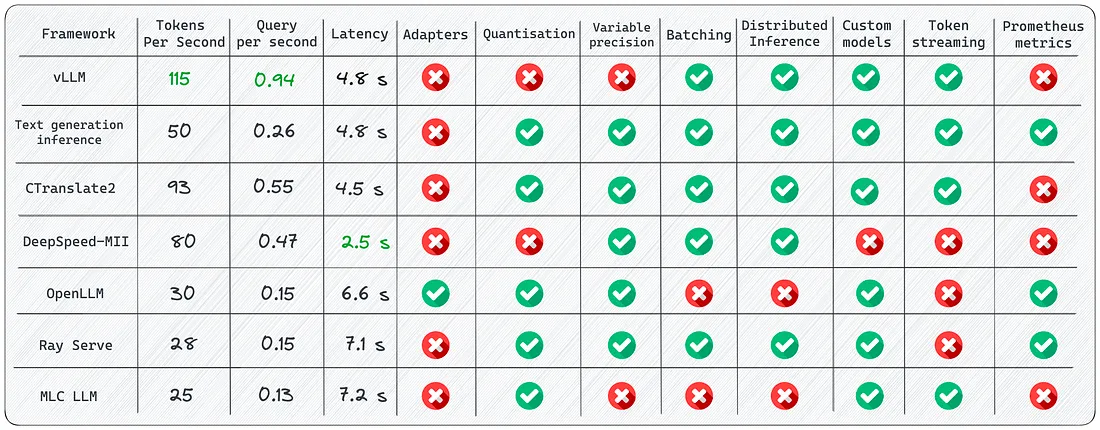
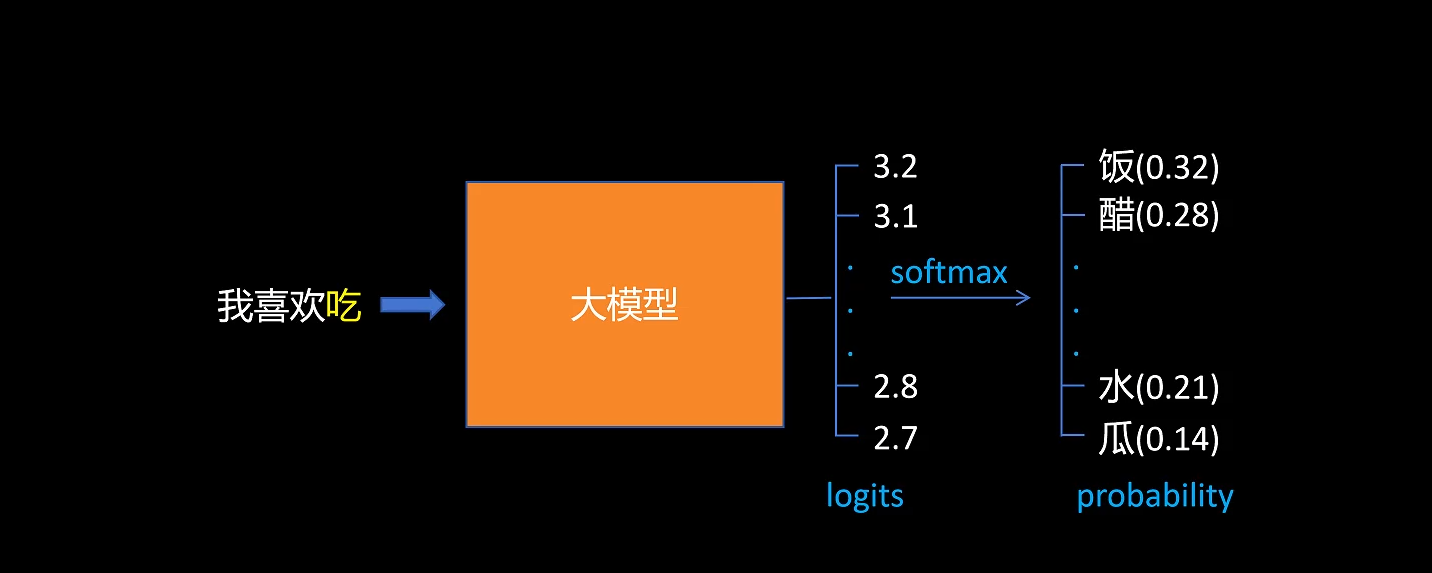
正常LLM做 next token predicate 时,对输出的 logits 做 softmax,选择概率最大的token。
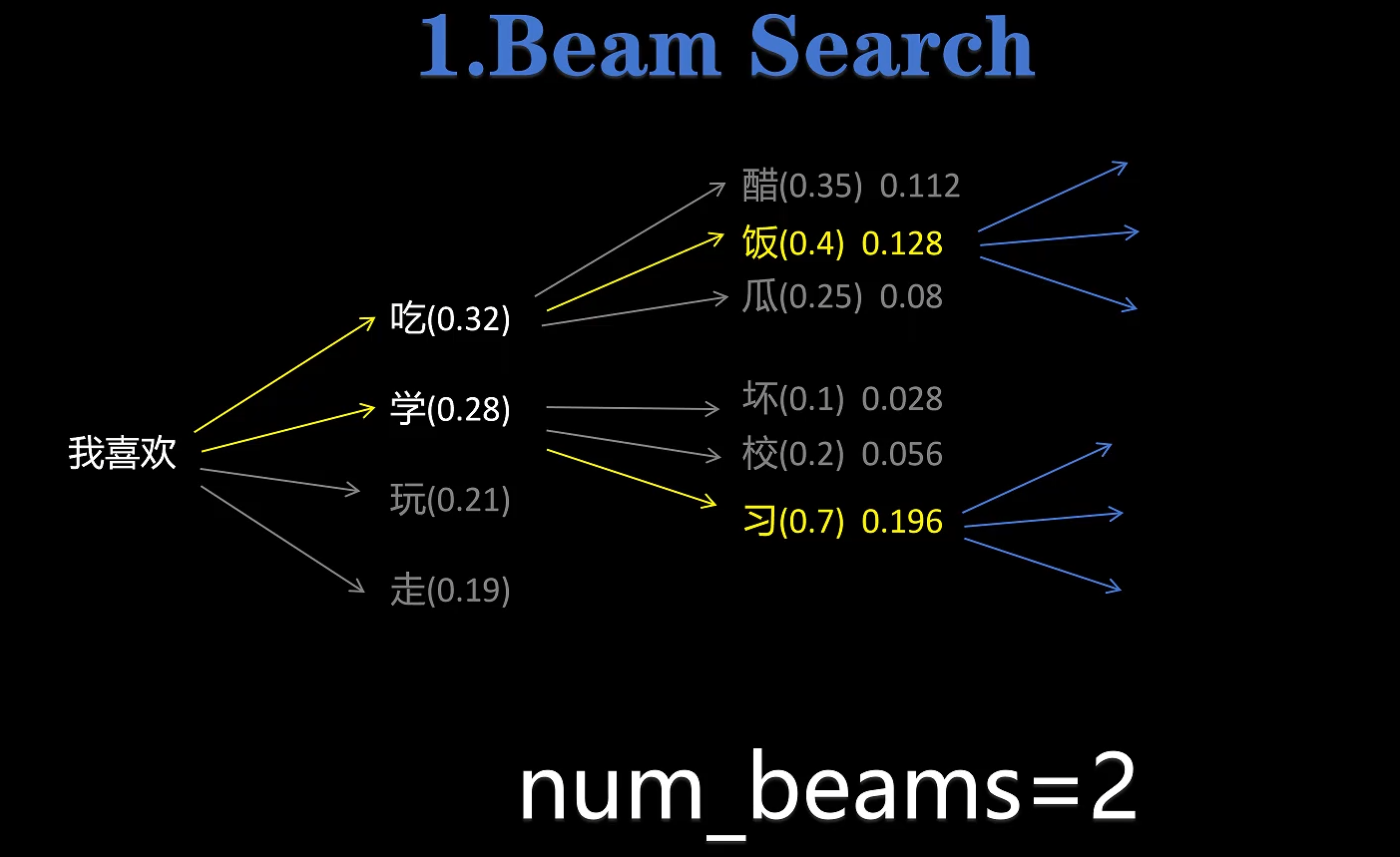
num_beams :当我们设置 num_beams=2 后,就使用了 beam search 的方法,每次不是只直接选择概率最大的 token,而是保留 num_beams 个概率最大的 token 选择,接着进行下一轮的 next token predicate,把两次预测的 token的 联合概率作为选择标准,选取联合概率最大的分支。
top_k:当我们设置top_k=2之后,会对LLM输出的 logits 保留 top_k 个最大的,然后其他 token 的 logits 设置为负无穷-inf,再对所有 logits 进行 softmax,那么-inf就会变成0,选概率最大的token即可。实现了在top_k个概率最大的 token 中选取。

top_p:当我们设置top_p=0.8之后,对每个token的softmax的概率累积求和,当概率达到top_p之后,后面概率更小的token概率设置为-inf,然后再经过一次softmax重新分配概率,取概率最大的token。

temperature:当我们设置temperature=[0,2]之后,就是对softmax进行调节。temperature越大,softmax得到的各个token概率越平均,生成的随机性越大。