在前面LLaMA 系列模型的进化(一)中学习了LLama模型的总体进化发展,再来看看其中涉及的一些重要技术。
PreLayerNorm
Layer Norm有Pre-LN和Post-LN两种。Layer Normalization(LN)在Transformer架构中的放置位置对模型的训练稳定性和性能有影响。根据研究,Post-LN(将LayerNorm放在残差连接之后)在训练初期可能会导致梯度在网络深层比浅层大,这可能会使得训练过程不稳定。为了解决这个问题,Pre-LN(将LayerNorm放在残差连接之前)被提出,并且在实践中显示出可以提高训练的稳定性和速度。

然而,Pre-LN也有其问题,比如在预训练期间,早期层的梯度会比后期层大,这同样可能影响训练稳定性。
因此,一些研究工作提出了改进方案,比如NormFormer,通过在每个Transformer层中增加额外的归一化操作来解决Pre-LN的梯度幅度不匹配问题,从而进一步提高了模型的预训练困惑度和下游任务性能。这表明,尽管Pre-LN在很多大型预训练模型中被采用,但研究者们仍在不断探索更优的归一化策略来提高Transformer模型的训练效率和性能。
RMSNorm,均方根层归一化(root-mean-squared layer-normalization )
在LLaMA模型中,RMSNorm(Root Mean Square Layer Normalization)是一种用于归一化的技术。与传统的Layer Norm不同,RMSNorm不使用均值和方差进行归一化,而是直接除以输入数据的均方根值。
传统的LayerNorm定义:

RMSNorm的公式定义:

RMSNorm相对于LayerNorm的优势主要在于计算上,因为它只对方差进行操作,而不需要计算均值,这可能会在某些情况下使得计算速度略快。然而,RMSNorm可能在数值稳定性和归一化效果上与LayerNorm有所不同,因为LayerNorm同时考虑了均值和方差,而RMSNorm只关注方差。
关于RMSNorm的效果是否与LayerNorm相当,这可能取决于具体的应用场景和模型架构。在某些情况下,RMSNorm可能与LayerNorm有相似的性能,但在其他情况下,两者之间可能会有显著的差异。总的来说,选择哪种归一化方法应该基于具体任务的需求和实验结果。
RMSNorm论文链接:https://proceedings.neurips.cc/paper_files/paper/2019/file/1e8a19426224ca89e83cef47f1e7f53b-Paper.pdf
SwiGLU激活函数代替ReLU
SwiGLU(Switched Gated Linear Unit)是一种改进的激活函数,,是对传统门控线性单元(Gated Linear Unit, GLU)的一个变种,它在自然语言处理,特别是Transformer模型中,用于增强模型的非线性能力。工作原理说明如下:

分组查询注意力,GQA
在LLaMA模型中,分组查询注意力(Grouped-Query Attention, GQA)是一种用于提高训练和推理效率的机制。具体来说,GQA通过将查询(Query)进行分组,并在组内共享键(Key)和值(Value)投影,从而减少与缓存相关的内存成本。
这种机制允许在多头注意力(MHA)模型中共享键和值投影,使得K和V的预测可以跨多个头共享,从而显著降低计算和内存需求,提升推理速度。此外,GQA还被视为在不同维度上的粗粒度稀疏表示方法之一,其中MoE(混合专家系统)是在Linear layer维度上实现的。
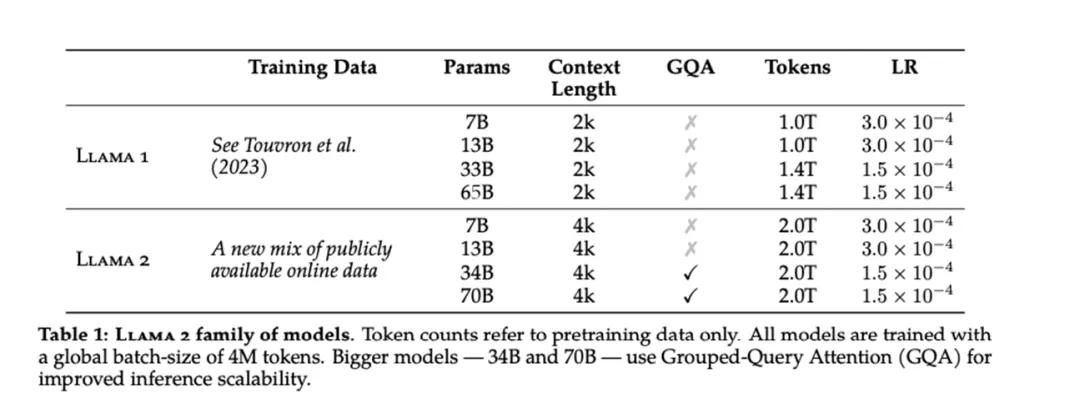
在LLaMA 2和LLaMA 3模型中,GQA被广泛采用以优化内存使用并提高模型的推理性能。例如,在LLaMA 2的70B参数版本中,GQA显著提升了推理性能。同样,在LLaMA 3的所有模型中,包括8B和70B版本,也采用了GQA来处理更长的上下文并提高效率。
在实际应用中,LLaMA模型使用GQA(分组查询注意力机制)处理长文本的能力表现出色。根据证据显示,LLaMA-2及其变种如LLaMA 2-Long通过采用GQA机制,显著提高了推理速度和内存效率。
多头注意力(MHA):
多头注意力是一种在Transformer架构中广泛使用的注意力机制,通过将查询、键和值分别投影到多个不同的空间上,并并行计算这些空间上的注意力得分,从而获得更加丰富和细致的特征表示。
多查询注意力(MQA):
多查询注意力是MHA的一种变种,它通过共享单个key和value头来提升性能,但可能会导致质量下降和训练不稳定。MQA在保持速度的同时提高了模型的推理效率,但在某些情况下可能无法达到与MHA相同的效果。
分组查询注意力(GQA):
分组查询注意力是MQA和MHA之间的插值方法,旨在同时保持MQA的速度和MHA的质量。GQA通过使用中间数量的键值头(大于一个,小于查询头的数量),实现了性能和速度的平衡。具体来说,GQA通过分组的方式减少了需要处理的头数,从而降低了内存需求和计算复杂度。
分组查询注意力(Grouped-Query Attention,简称GQA)是一种用于提高大模型推理可扩展性的机制。其具体实现机制如下:
1、基本概念:GQA是多头注意力(Multi-Head Attention,MHA)的变种,通过将查询头(query heads)分成多个组来减少内存带宽的需求。每个组共享一个键头(key head)和一个值头(value head),从而降低了每个处理步骤中加载解码器权重和注意力键/值的内存消耗。
2、实现方式:在实际应用中,GQA将查询头分成G个组,每组共享一个键头和一个值头。例如,GQA-G表示有G个组,而GQA-1则表示只有一个组,这相当于传统的MQA(Multi-Group Query Attention)。当GQA的组数等于查询头的数量时,它等同于标准的MHA。
3、性能与效率平衡:GQA通过这种方式有效地平衡了性能和内存需求。它允许模型在不显著降低性能的情况下,处理更多的请求并提高推理效率。此外,使用GQA可以避免由于加载大量解码器权重和注意力键/值而导致的内存瓶颈问题
旋转位置嵌入
现在大模型已经普遍的应用RoPE。
关于RoPE,直接看苏神的文章《Transformer升级之路:“复盘”长度外推技术》,(https://mp.weixin.qq.com/s/oQtaYtIWJo2qlZHeqBwfxA)
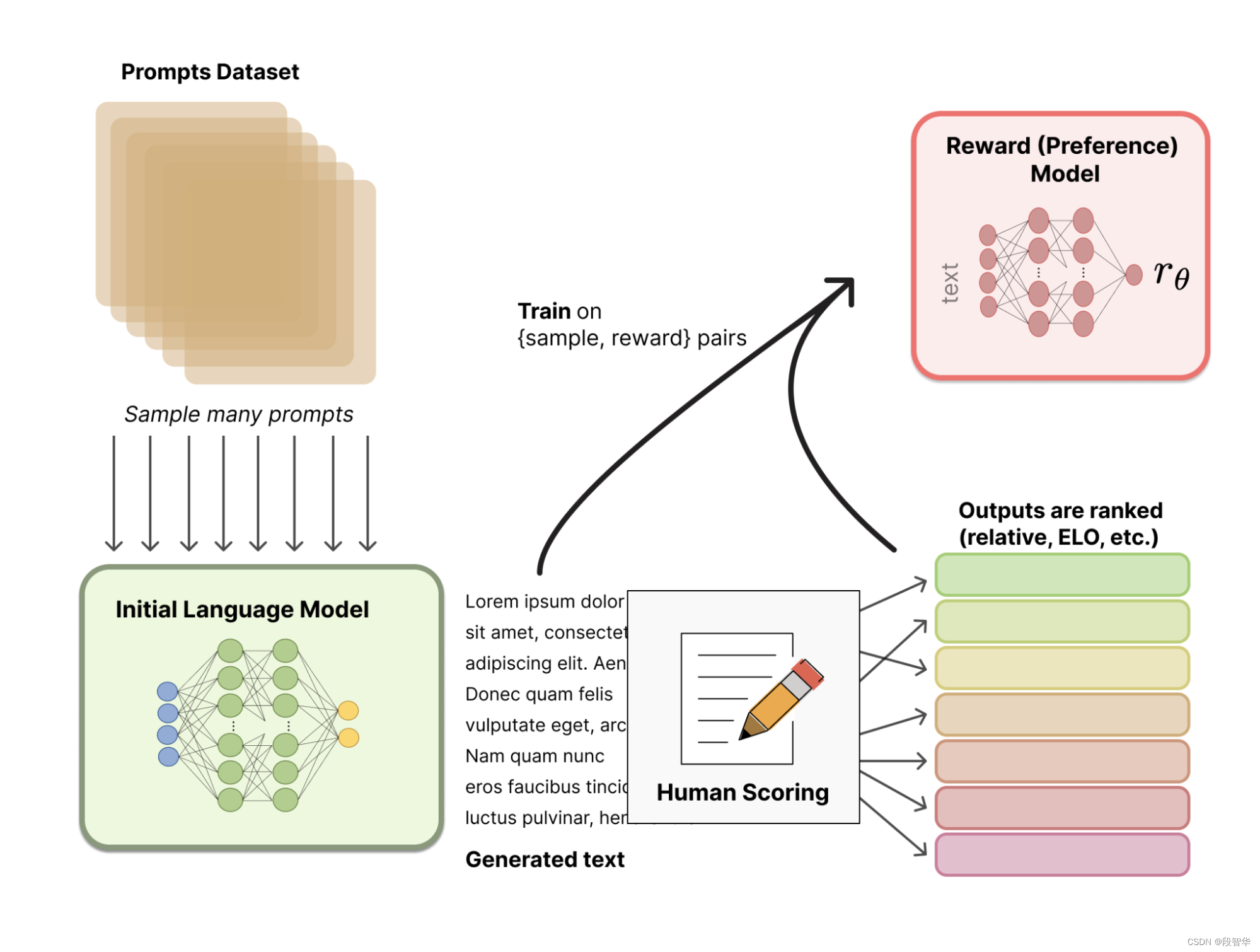
RLHF
关于RLHF,有很多分析文章。推荐《图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读》,清晰易懂
文章链接:https://mp.weixin.qq.com/s/mhPJzhQvPJlAWsO2nW9BHg
有观点认为,有用性和安全性之间会存在权衡,所以LLAMA2训练了两个独立的奖励模型。一个针对有用性进行优化(称为有用性奖励模型,Helpfulness RM),另一个针对安全性进行优化(称为安全性奖励模型,Safety RM)。这样可以分别在有用性和安全性方面取得更好的效果,使得Llama 2-Chat在强化学习人类偏好(RLHF)过程中更好地符合人类偏好,提高生成回答的有用性和安全性。
迭代训练中,LLAMA2采用了两种强化学习算法:PPO和拒绝采样算法。
SELF-INSTRUCT
Stanford Alpaca 是第一个基于LLaMA (7B) 进行微调的开放式指令遵循模型。通过使用 Self-Instruct 方法借助大语言模型进行自动化的指令生成,Stanford Alpaca 生成了 52K 条指令遵循样例数据(Alpaca-52K)用于训练,其指令数据和训练代码在随后的工作中被广泛采用。
下面这个图展示了具体过程。

LLAMA-Adapter
论文标题:LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
论文链接:https://arxiv.org/pdf/2303.16199.pdf
LLaMA-Adapter,一种轻量级的适应方法,可以有效地将 LLaMA 微调为指令跟随模型。使用 52K self-instruct演示,LLaMA-Adapter 在冻结的 LLaMA 7B 模型上仅引入 1.2M 可训练参数,并在使用 8 个 A100 GPU 进行微调时,仅需不到一小时。具体来说,采用一组可学习的适应提示,并将其前置到更高 Transformer 层中的输入文本 token 上。然后,提出了零初始化注意力机制 (zero-gating),该机制自适应地注入新的指令提示到 LLaMA 中,同时有效地保留了其预训练知识。通过高效的训练,LLaMA-Adapter 生成了高质量的响应,与完全微调的 7B 参数的 Alpaca 相当。此外,LLaMA-Adapter扩展到多模态输入,用于学习图像条件LLaMA模型,在ScienceQA和COCO Caption基准测试中实现了卓越的推理性能。

通过下面图看一下具体方法。

Learnable Adaption Prompts
方法中涉及Learnable Adaption Prompts,直接求助kimi:

零初始化注意:流行的 PEFT 方法可能会通过直接插入随机初始化的模块来干扰预训练的语言知识。这导致在早期训练阶段具有较大损失值,使得微调不稳定。LLaMA-Adapter 采用带有门控的零初始化注意力来缓解这种情况。

统一多模式微调:以前的PEFT方法通常是为了解决特定的模态,如语言、图像和音频。相比之下,LLaMA Adapter可以以统一的方式处理语言和多模态的微调,显示出卓越的泛化能力

具体方法通过kimi:

一篇拖延了好久的问题,本来准备认真写一下,结果,就先凑一些素材吧。