名词
- CPU拷贝:将内核缓存区的数据拷贝到用户缓存区
- DMA拷贝:将外设上的数据拷贝到内核缓存区
- 系统调用:应用程序调用操作系统的接口
- 上下文切换:用户态和内核态,应用调用操作系统的接口,操作系统调用CPU内核工作,需要从用户态切换到内核态。系统调用返回,就会从内核态切换成用户态。一次系统调用涉及到两次上下文切换
原理
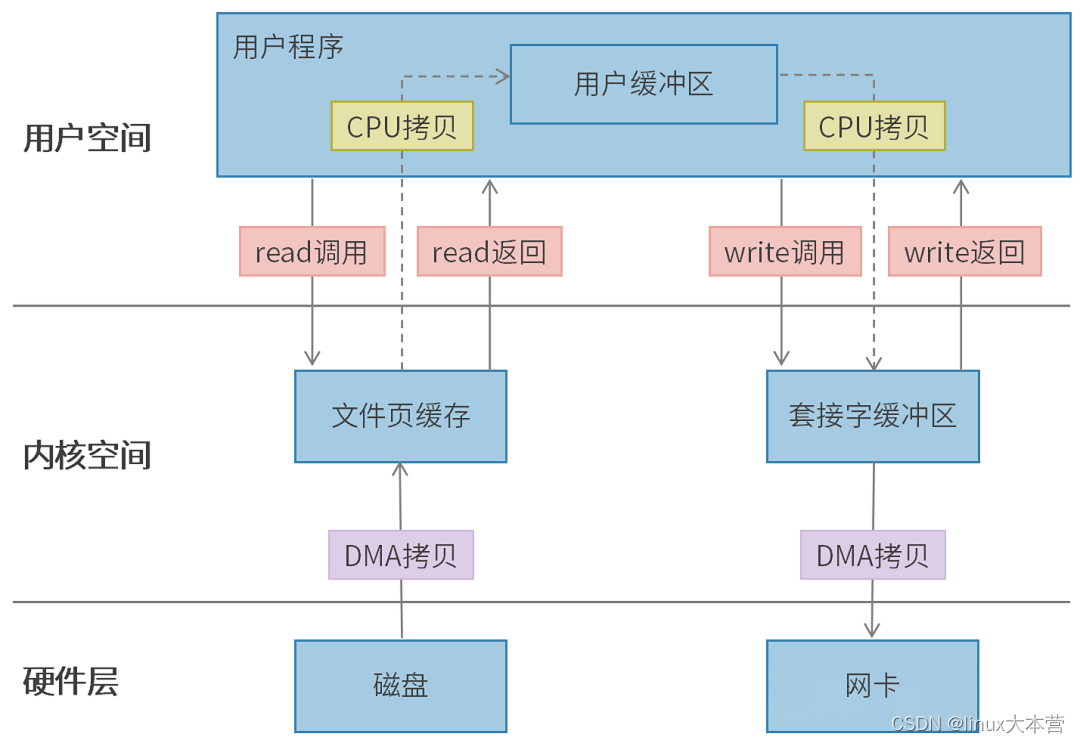
一次完整的读取数据的流程如下:
- 用户进程调用 read 方法,向操作系统发出 I/O 请求,请求读取数据到自己的用户缓冲区中,进程进入阻塞状态,用户态切换至内核态;
- 操作系统收到请求后,进一步将 I/O 请求发送 DMA,然后让 CPU 可以执行其他任务;
- DMA 进一步将 I/O 请求发送给磁盘;
- 磁盘收到 DMA 的 I/O 请求,把数据从磁盘读取到磁盘控制器的缓冲区中,当磁盘控制器的缓冲区被读满后,向 DMA 发起中断信号,告知自己缓冲区已满;
- DMA 收到磁盘的信号,将磁盘控制器缓冲区中的数据拷贝到内核缓冲区中,此时不占用 CPU,CPU 可以执行其他任务;
- 当 DMA 读取了足够多的数据,就会发送中断信号给 CPU;
- CPU 收到 DMA 的信号,知道数据已经准备好,于是将数据从内核拷贝到用户空间,系统调用返回,内核态切换至用户态;

而一个完整的读写操作如下:

可知IO操作中主要耗时操作如下: - 4次数据拷贝,其中DMA和CPU分别拷贝2次(CPU的时间多宝贵啊)
- 2次系统调用导致的4 次用户态与内核态的上下文切换
如何优化整个IO过程呢?
也就是零拷贝技术的原理原理:减少「用户态与内核态的上下文切换」和「数据拷贝」的次数。
- 减少上下文切换到次数
- 每次系统调用都需要两次上下文切换,所以需要实现减少系统调用的次数
- 如何减少「数据拷贝」的次数
- 从内核的读缓冲区-----用户的缓冲区里----- socket 的缓冲区里这个过程,去除拷贝到用户缓冲区,直接将内核缓冲区到socket缓冲区。
几种实现零拷贝技术的区别

可以看出,无论是传统的 I/O 方式,还是引入了零拷贝之后,2 次 DMA(Direct Memory Access) 拷贝是都少不了的。因为两次 DMA 都是依赖硬件完成的。零拷贝主要是减少了 CPU 拷贝及上下文的切换。



































![[MySQL][复核查询][多表查询][自连接][自查询]详细讲解](https://i-blog.csdnimg.cn/direct/6237792652e54fca980c4b6aa8765fc7.png)




