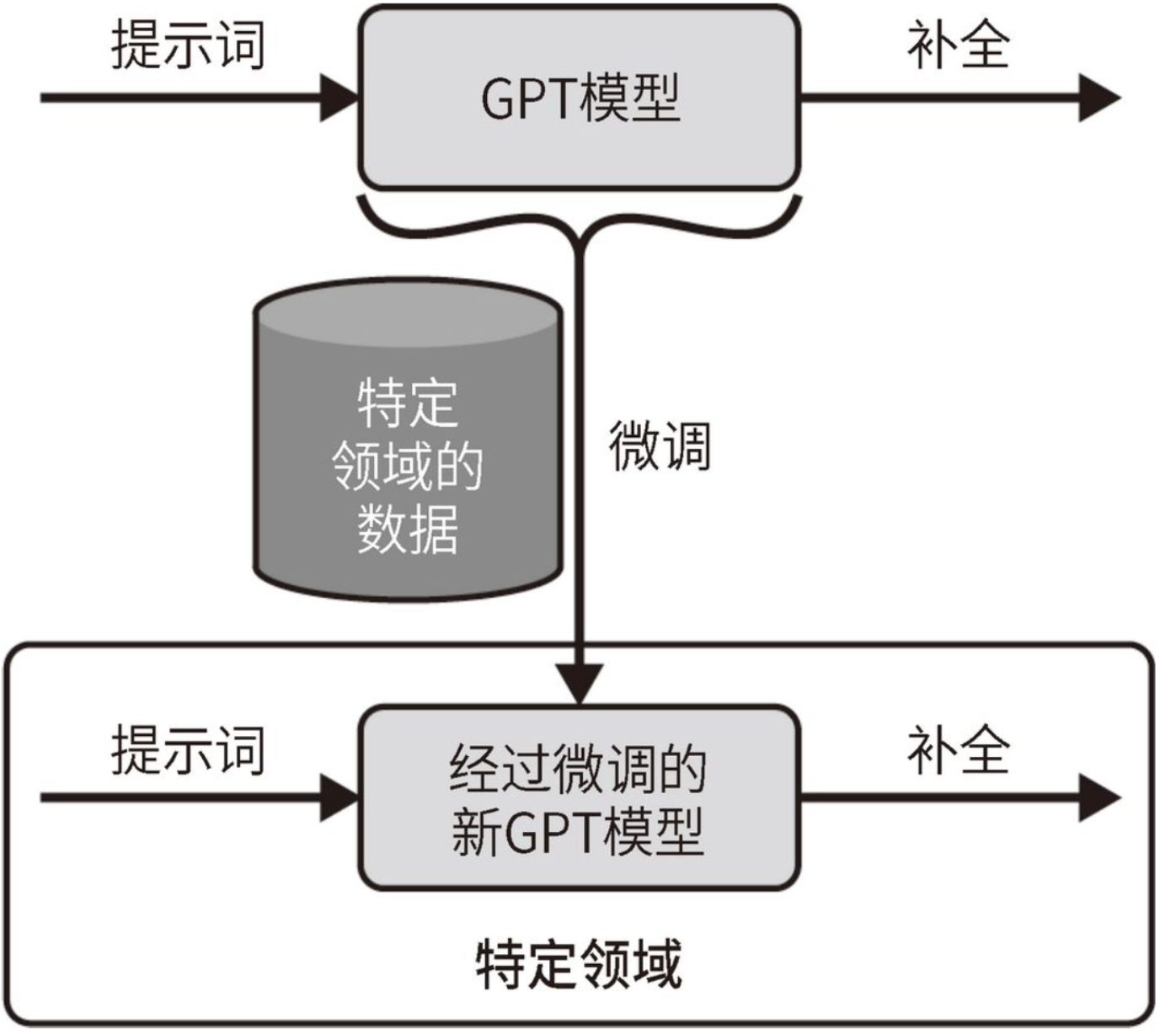
在AI Native应用中,模型微调(Fine-Tuning)是一个至关重要的技术环节,它允许开发者通过特定领域的数据对预训练模型进行再训练,从而使其更好地适应特定任务或数据集。这一技术不仅显著提升了模型的性能和准确性,还促进了AI技术在各个领域的深入应用。以下是对AI Native应用中模型微调的详细探讨,包括其重要性、方法、步骤、挑战及未来发展方向。
一、模型微调的重要性
在AI Native应用中,模型微调具有多重重要性:
提升模型性能:通过微调,预训练模型能够学习到特定任务或数据集的特征,从而在这些任务上表现出更高的准确率和召回率。这种针对性学习使得模型能够更好地理解和处理特定领域的数据,提高整体性能。
减少计算资源消耗:相比于从头开始训练一个全新的模型,微调可以在预训练模型的基础上进行,这大大减少了计算资源的消耗。预训练模型已经在大规模数据上进行了训练,具备了强大的特征提取能力,微调只需在此基础上进行微调整即可。
加速模型开发周期:模型微调简化了模型开发过程,使开发者能够更快地构建和部署模型。这对于需要快速响应市场变化或客户需求的AI Native应用尤为重要。
提升模型泛化能力:微调后的模型不仅能在训练数据集上表现优异,还能在未见过的数据上保持良好的性能。这种泛化能力使得模型更加实用和可靠。
二、模型微调的方法
在AI Native应用中,模型微调的方法多种多样,主要包括以下几种:
全量微调(Full Fine-Tuning):
全量微调是指对预训练模型的所有参数进行训练,以适应新的任务或数据。这种方法能够充分利用预训练模型的通用特征,但也需要大量的计算资源和时间。此外,全量微调可能导致灾难性遗忘问题,即模型在适应新任务时忘记了旧任务的知识。参数高效微调(Parameter-Efficient Fine-Tuning, PEFT):
参数高效微调是一种优化的微调策略,旨在减少模型微调过程中所需的参数数量和计算资源。PEFT方法包括LoRA、Prefix Tuning、Adapter Tuning等,这些方法仅对模型的少量关键参数进行训练,但仍能带来显著的性能提升。PEFT特别适用于数据量有限、资源有限的场景。监督微调(Supervised Fine-Tuning, SFT):
监督微调是使用带有标签的数据集对预训练模型进行进一步训练的方法。通过监督学习,模型可以学习到特定任务的特征表示,从而提高在该任务上的性能。无监督微调(Unsupervised Fine-Tuning):
无监督微调则使用未标注的数据对预训练模型进行训练。这种方法有助于模型发现数据的内在结构,从而在没有明确标签的情况下进行有效的学习。然而,无监督微调通常需要更多的数据和更长的训练时间。迁移学习(Transfer Learning):
迁移学习是一种特殊的微调方法,它允许模型将在一个任务上学到的知识应用到另一个相关但不同的任务上。通过迁移学习,可以减少对大量标注数据的依赖,加速模型的训练过程。
三、模型微调的步骤
在AI Native应用中进行模型微调通常包括以下几个步骤:
准备数据:
微调模型需要一个高质量的、标注好的数据集。数据的质量直接影响到微调的效果。因此,在准备数据时,需要确保数据集足够大以覆盖任务的多样性,并且数据分布与实际应用场景相符。选择合适的预训练模型:
根据任务需求选择一个合适的预训练模型作为基础。常用的预训练模型包括BERT、GPT、ResNet等,这些模型在大规模数据上进行了预训练,具有强大的特征提取能力。数据预处理:
根据任务类型对数据进行预处理。例如,对于文本数据,可能需要进行分词、去除停用词、文本规范化等操作;对于图像数据,可能需要进行缩放、归一化、数据增强等操作。配置超参数:
配置微调过程中的超参数,包括学习率、批量大小、训练轮数等。这些参数对模型的性能有很大影响,需要通过实验进行调优。进行微调训练:
将预处理后的数据输入预训练模型,并进行微调训练。在训练过程中,需要监控模型的性能指标,如准确率、召回率、F1分数等,并根据评估结果进行调整。评估和部署:
在验证集或测试集上评估微调后的模型性能,确保模型达到预期目标。然后,将微调后的模型部署到生产环境中,提供实时预测服务。
四、模型微调面临的挑战
尽管模型微调在AI Native应用中具有诸多优势,但也面临着一些挑战:
过拟合问题:
模型在微调过程中可能会过度适应训练数据,导致在未见过的数据上表现不佳,即过拟合问题。为了缓解过拟合,可以采用数据增强、早停法、正则化等技术手段。域适应性问题:
预训练模型通常在通用数据集上进行训练,而实际应用中的数据集可能与预训练数据存在较大的差异,即领域差异(domain shift)。这种差异可能导致模型在微调后的性能不如预期。为了克服这一问题,可以采用领域适应技术,如对抗性训练、领域不变表示学习等。计算资源限制:
虽然模型微调相比从头训练可以节省计算资源,但对于大规模预训练模型而言,微调仍然需要大量的计算资源。特别是对于资源受限的环境,如边缘设备或移动设备,如何高效地进行模型微调成为了一个挑战。为此,研究者们提出了轻量级模型、模型剪枝、量化等技术来降低模型大小和计算复杂度。灾难性遗忘:
在连续学习任务中,模型在微调以适应新任务时可能会忘记之前学习到的知识,即灾难性遗忘问题。这限制了模型在多个任务上的连续学习和应用能力。为了缓解这一问题,可以采用增量学习、元学习等技术来平衡新旧任务的学习。数据隐私与安全性:
在模型微调过程中,可能需要使用敏感或私有数据。如何保护这些数据不被泄露或滥用成为了一个重要问题。为此,研究者们提出了差分隐私、联邦学习等隐私保护技术,允许在保护数据隐私的同时进行模型训练。
五、未来发展方向
随着AI技术的不断发展,模型微调在AI Native应用中的未来发展方向包括:
更高效的微调方法:
研究者们将继续探索更高效、更省资源的微调方法,如参数高效微调(PEFT)的进一步发展和优化。这些方法将使得在资源受限的环境下也能进行有效的模型微调。跨模态微调:
随着多模态数据的普及,跨模态微调将成为研究热点。跨模态微调旨在使模型能够同时处理不同模态的数据(如文本、图像、音频等),并在这些模态之间进行有效的信息融合和交互。自适应微调:
自适应微调技术将使得模型能够根据不同的应用场景和数据分布自动调整微调策略,从而进一步提高模型的泛化能力和鲁棒性。强化学习与微调的融合:
强化学习(Reinforcement Learning, RL)与微调的融合将使得模型能够在复杂环境中通过试错学习来优化自身性能。这种融合方法有望推动AI技术在更广泛的领域实现自主决策和智能控制。可解释性与微调:
随着对AI模型可解释性要求的提高,研究者们将探索如何在微调过程中保持或提高模型的可解释性。这将有助于用户更好地理解模型的行为和决策过程,从而提高AI技术的信任度和接受度。
总之,模型微调作为AI Native应用中的关键技术之一,将在未来继续发挥重要作用。通过不断探索和创新,我们有望克服当前面临的挑战,推动AI技术在更多领域实现深入应用和发展。