随着基础大模型多样化和迭代速度的日益加快,“大模型+”的应用拐点正在到来,语言大模型、多模态大模型、具身智能开始广泛落地到各类业务场景中。巨大的市场潜力,吸引了各领域科技巨头纷纷布局大模型。
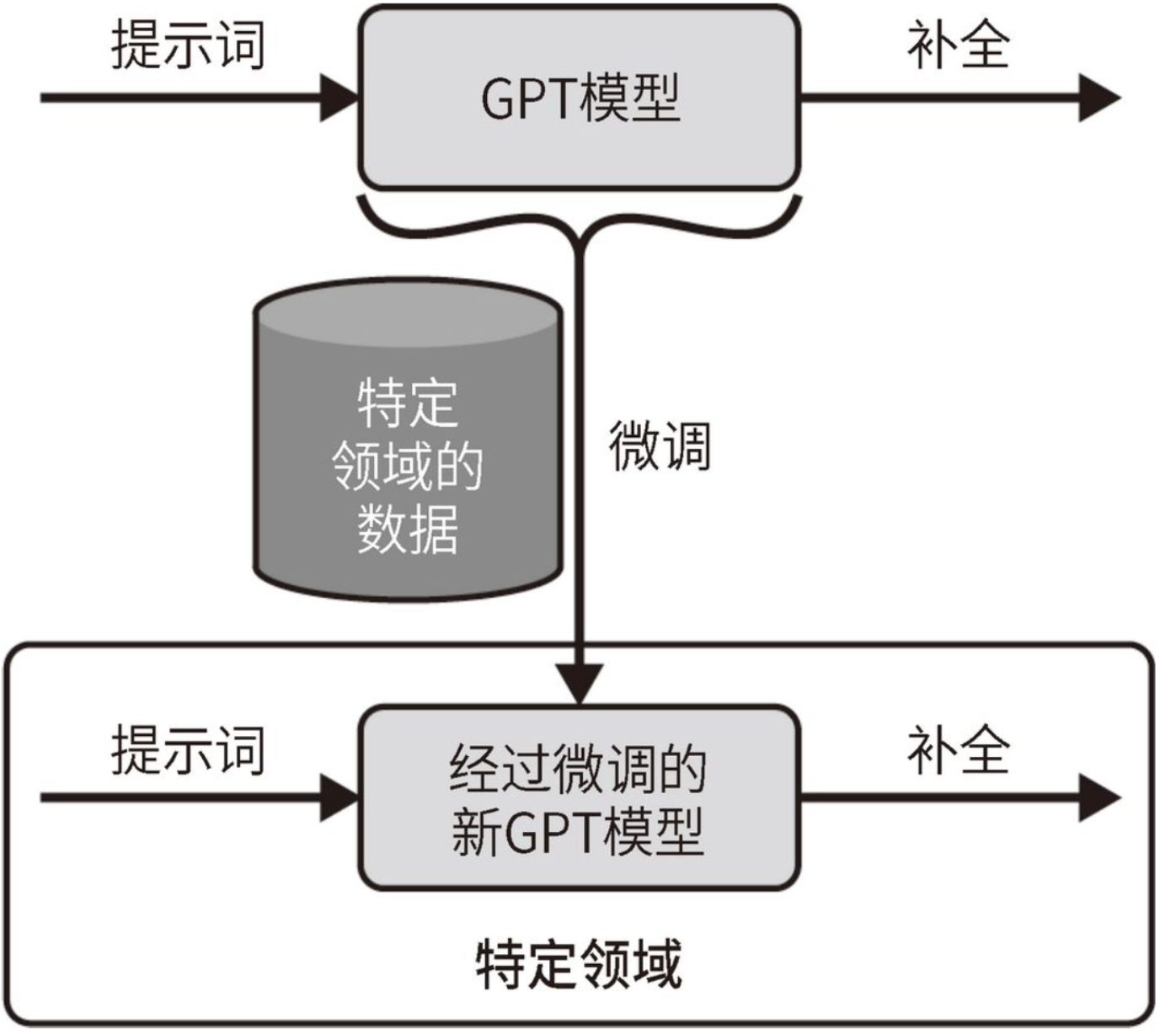
对于绝大多数企业来说,真正的机会并不是从头开始做ChatGPT这样的基础大模型,而是基于通用大语言模型,进行针对性的再训练、微调和评估,从而开发出适合自身业务场景的应用。
训练或直接使用大模型,根本目标是提升业务的智能化水平。从性价比角度分析,优先评估大模型是否满足当前的业务需求,从而选择使用已有大模型,或对模型进行二次训练。模型二次训练可以实现的目标:知识嵌入模型,满足知识补足场景;提升指令遵循能力,满足特定任务场景;提升基础模型性能,满足通用能力提升。
基座模型的性能、参数量决定着模型微调的性价比。企业应该如何选择符合企业自身的基座模型,进行模型的再训练和微调呢?下文将从大模型应用的技术路线,为什么要微调大模型,大模型微调方案有哪些这些方面对这一问题进行梳理和解答。
如果你对这篇文章感兴趣,而且你想要了解更多关于AI领域的实战技巧,可以关注「神州问学」公众号。在这里,你可以看到最新最热的AIGC领域的干货文章和前沿资讯。
大模型应用的技术路线
基于大模型实现业务智能化的解决方案,产业界已经探索出了多条技术路线,按实现的复杂程度划分:
提示工程(Prompt Engineering)。提示工程的核心是在提供尽可能多的上下文信息的同时,通过提供少量示例(few-shot learning)来更好地让大模型了解目标需求。虽然结果在孤立情况下看起来令人印象深刻,但与本文中讨论的其他方法相比,它产生的结果最不准确。
检索增强生成(Retrieval Augmented Generation,RAG)。检索增强生成通过使用向量化技术进行关键信息的匹配计算和召回,并通过扩展上下文将信息注入模型,可以取得高质量的结果。与提示工程相比,它产生了大幅改善的结果,并且可以减少幻觉的出现。
微调(Fine-tuning)。微调在准确性方面提供了相当高的结果,其输出质量与RAG相媲美。由于我们正在使用特定领域的数据更新模型权重,因此该模型能够产生更具上下文的回复。通常选择微调的原因不仅仅是准确性,还包括数据变化频率、控制模型以符合监管、合规和可复现性等方面的考虑。
从零开始训练自己的基础模型(From scratch Foundation Model)
这里没有对比使用预训练基础大模型选项,因为几乎没有任何业务用例可以有效地使用基础大模型来解决。原封不动地使用基础大模型可以很好地用于一般搜索,但如果要做好特定的业务,则需要考虑上述选项之一。在理想情况下,从头开始训练可以产生最高质量的结果,由于模型是根据特定用例的数据进行训练,幻觉的可能性几乎为零,并且输出的准确性也是很高的。当然,这对模型训练者的工程和算法知识要求较高。
在大模型应用方案落地过程中,技术路线的选择会影响业务需求的推进,选择不当会产生非常消极的结果。例如:
大模型在特定任务上的性能不佳,导致业务结果不准确。
如果未针对业务用例进行优化,则会增加模型训练和推理的计算成本。
如果实现过程中需要转向不同的技术,则需要额外的开发和迭代时间。
部署应用程序并将其呈现在用户面前时出现延迟。
如果您选择过于复杂的适应方法,则缺乏模型可解释性。
由于尺寸或计算限制,难以将模型部署到生产中。
为了保证大模型在业务场景落地,一般从以下几个角度衡量技术方案:
准确性(回答的准确程度如何?),实施复杂性(实施过程有多复杂?),工作量(需要多少努力来实现?),总拥有成本(TCO)(拥有解决方案的总成本是多少?),更新和更改的便利性(架构是否耦合度低?替换/ 升级组件是否容易?)。
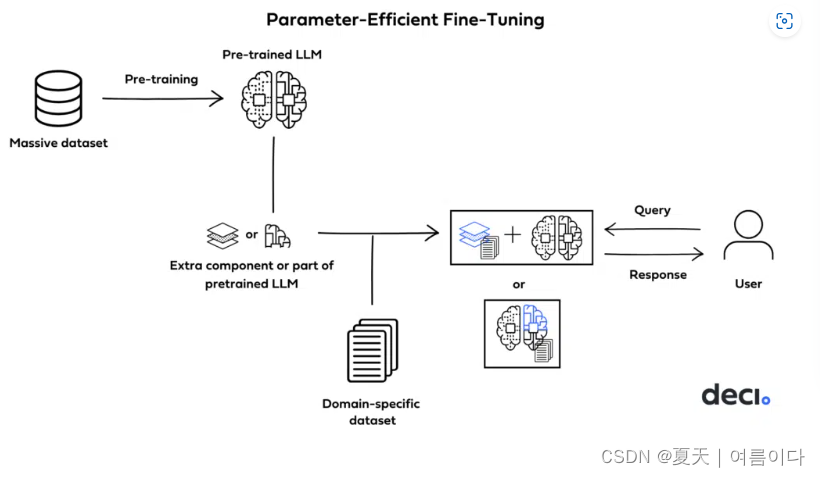
为什么要微调大模型
微调(Fine-tuning)是在基础大模型上,通过更多的数据进行训练获得更专业化的大模型,使其更适合某些特定任务。经过微调,模型能够处理更多数据并从中学习知识,提高准确性和一致性。微调还能减少模型的误差和幻觉,提供更专业的回答。此外,微调也能增强隐私保护和性能。
选择预训练模型作为基础模型,当预训练模型和下游任务差距不大,且预训练模型中包含微调任务中所需要的知识时,往往可以取得不错的效果。但在实际情况中,我们通常会遇到一些问题,使得我们无法直接使用一些开源大模型作为有骨干网络:
大模型的参数量非常大,训练成本非常高,每家公司都去从头训练一个自己的大模型,性价比非常低;
Prompt Engineering的方式是一种相对来说容易上手的使用大模型的方式,但是通常大模型的实现原理,都会对输入序列的长度有限制,Prompt Engineering 的方式会把Prompt搞得很长。对于对外提供服务的企业来说,要想在自己的服务中接入大模型的能力,推理成本是不得不要考虑的一个因素,微调相对来说就是一个更优的方案。
RAG的效果达不到要求,企业又有比较好的自有数据,能够通过自有数据,更好的提升大模型在特定领域的能力。这时候微调就非常适用。
要在个性化的服务中使用大模型的能力,这时候针对每个用户的数据,训练一个轻量级的微调模型,就是一个不错的方案。
数据安全的问题。如果数据是不能传递给第三方大模型服务的,那么搭建自己的大模型就非常必要。通常这些开源的大模型都是需要用自有数据进行微调,才能够满足业务的需求,这时候也需要对大模型进行微调。
使用微调时,可以更好地控制模型的组件,并进行版本管理。当领域特定术语与数据(比如法律、生物学等)相关度高时,它会非常有用。基于上述分析,会总结出微调基础大模型有以下意义:节省时间和资源,减少数据需求,实现持续学习,知识可定制。
大模型微调方案
大模型微调是一项复杂的系统工程,最终的性能提升依赖各个环节的实验和精调。从数据工程角度需要制定数据格式、数据配比,从微调技术角度需要选择全参数微调还是高效微调,从模型角度需要选择基础模型是Base模型还是Chat模型。
数据集
用于模型微调的数据集,包括通识数据、领域数据、指令数据、对齐数据等。在模型训练时,可以根据训练目标选择不同的数据集、数据配比和数据顺序,当然要保证数据格式的一致性,还需要对其质量,数量等方面进行衡量。
模型微调数据集分为开源数据和私域数据,包括公开数据集、开源的NLP
Benchmarks数据、Domain Knowledge领域知识、Hand-crafted Instructions人工标记数据、Human Preference Data人类偏好数据等,也有一些特定领域的微调数据,包括推理微调Reasoning Instructions(包括通用常识推理,代码code,数学math)、对话Conversational Instructions数据、Multilingual Instructions多语种微调数据。数据集的构建除收集、人工标注外,还可以利用包括self instruction方式进行迭代生成。
模型微调的性能来源于数据质量、模型规模、数据数量和模型训练策略等因素,每项因素都有助于微调性能的提升,但这些因素如何组合更好的提升模型性能需要进一步探索。普遍认为模型的知识都是在预训练时候得到的,微调只是为了学会和用户交互的风格或格式。实践中发现不同任务类型需要的数据量不同, 翻译、生成等任务使用200万或更少数据即可训练出性能优良的模型,分类、问答、总结等任务随着数据量增加性能会继续提升。在性能更好的基础模型上进行微调,使用更少的数据便可获得同样的效果。使用1000条多样性高质量数据进行微调,也能获得可观的模型性能提升。
微调技术路线
大模型微调,可以从参数规模、数据来源、训练方法等角度进行分类。不同分类角度,只是侧重点不一样,对同一个大模型的微调,也不局限于某一个方案,可以多个方案一起。微调的最终目标,是能够在可控成本的前提下,尽可能地提升大模型在特定领域的能力。
从参数规模的角度,大模型的微调分成两条技术路线:
对全量的参数,进行全量的训练,这条路线叫全量微调FFT(Full Fine Tuning),对资源需求极高;
对部分的参数进行训练,这条路线叫PEFT(Parameter-Efficient Fine Tuning),可以使用较少的资源完成训练;
从训练数据的来源、以及训练方法的角度,大模型的微调可以分为以下几条技术路线:
监督式微调SFT(Supervised Fine Tuning),这个方案主要是用人工标注的数据,用传统机器学习中监督学习的方法,对大模型进行微调;
基于人类反馈的强化学习微调RLHF,这个方案的主要特点是把人类的反馈,通过强化学习的方式,引入到对大模型的微调中去,让大模型生成的结果,更加符合人类的一些期望;
基于AI反馈的强化学习微调RLAIF,这个原理大致跟RLHF类似,但是反馈的来源是AI。这里是想解决反馈系统的效率问题,因为收集人类反馈,相对来说成本会比较高、效率比较低。
模型高效微调
从成本和效果的角度综合考虑,模型高效微调是目前业界比较流行的微调方案。几种比较流行的PEFT微调方案:LoRA、AdapterFusion、Prefix-tuning、P-tuning、prompt-tuning。
1.LoRA 的实现思想很简单,如下图所示,就是冻结一个预训练模型的矩阵参数,并选择用 A 和 B 矩阵来替代,在下游任务时只更新 A 和 B。

结合图片来看,LoRA 的实现流程如下:
在原始预训练语言模型(PLM)旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的内在秩。
训练的时候固定 PLM 的参数,只训练降维矩阵 A 与升维矩阵 B。
模型的输入输出维度不变,输出时将 BA 与 PLM 的参数叠加。
用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是 0 矩阵。
2. AdapterFusionr算法,是Adapter算法的一种改进实现,用以实现多个 Adapter 模块间的最大化任务迁移。
AdapterFusion 将学习过程分为两个阶段:
知识提取阶段:训练 Adapter 模块学习下游任务的特定知识,将知识封装在 Adapter 模块参数中。
知识组合阶段:将预训练模型参数与特定于任务的Adapter参数固定,引入新参数学习组合多个Adapter中的知识,提高模型在目标任务中的表现。
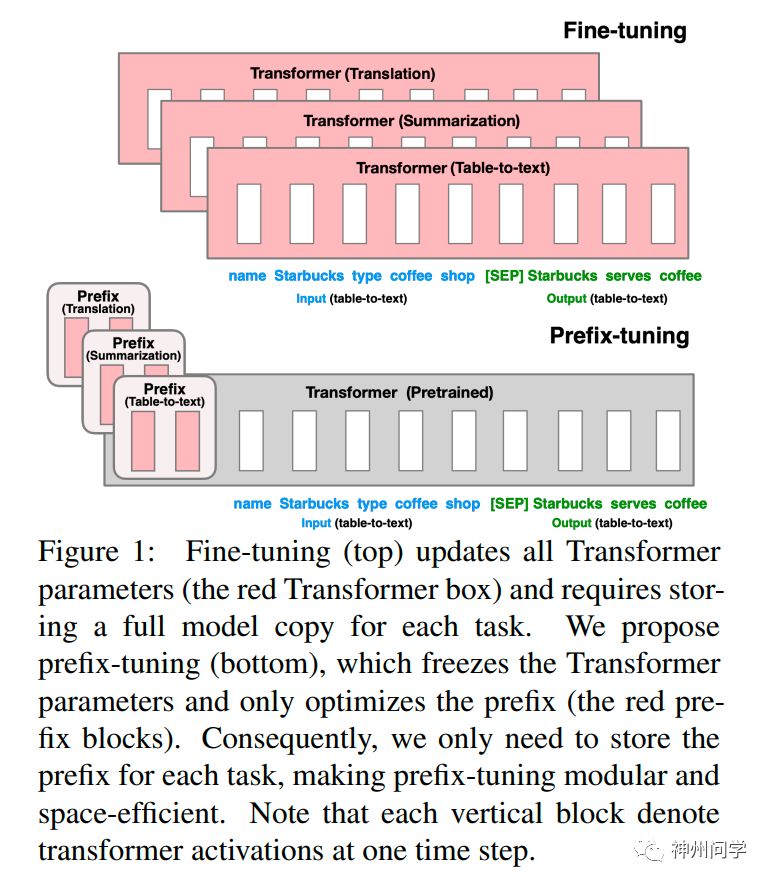
3. 前缀微调(prefix-tunning),用于生成任务的轻量微调。前缀微调将一个连续的特定于任务的向量序列添加到输入,称之为前缀,如下图中的红色块所示。与提示(prompt)不同的是,前缀完全由自由参数组成,与真正的 token 不对应。相比于传统的微调,前缀微调只优化了前缀。因此,我们只需要存储一个大型 Transformer 和已知任务特定前缀的副本,对每个额外任务产生非常小的开销。
4. P-tuning 是稍晚些的工作,主要针对 NLU 任务。对于 BERT 类双向语言模型采用模版(P1, x, P2, [MASK], P3),对于单向语言模型采用(P1, x, P2, [MASK]):
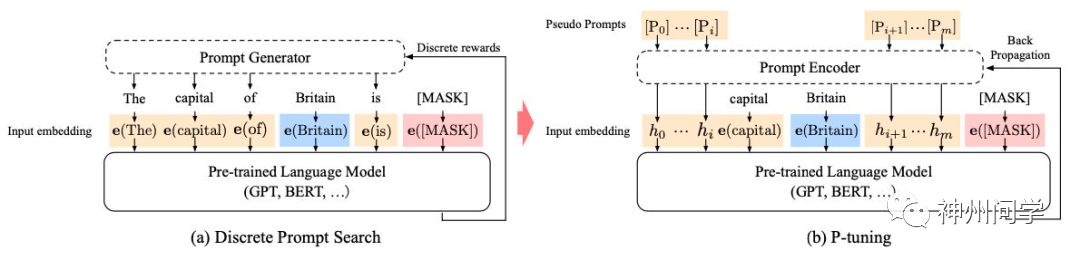
同时加了两个改动:
考虑到预训练模型本身的 embedding就比较离散了(随机初始化+梯度传回来小,最后只是小范围优化),同时prompt本身也是互相关联的,所以作者先用LSTM对 prompt进行编码;
在输入上加入了anchor,比如对于RTE任务,加上一个问号变成[PRE][prompt tokens][HYP]?[prompt tokens][mask]后效果会更好。
5. Prompt-tuning 给每个任务定义了自己的 Prompt,拼接到数据上作为输入,同时 freeze预训练模型进行训练,在没有加额外层的情况下,可以看到随着模型体积增大效果越来越好,最终追上了精调的效果:
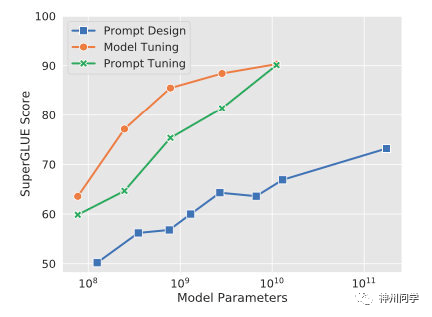
同时,Prompt-tuning 还提出了Prompt-ensembling,也就是在一个 batch 里同时训练同一个任务的不同prompt,这样相当于训练了不同「模型」,比模型集成的成本小多了。