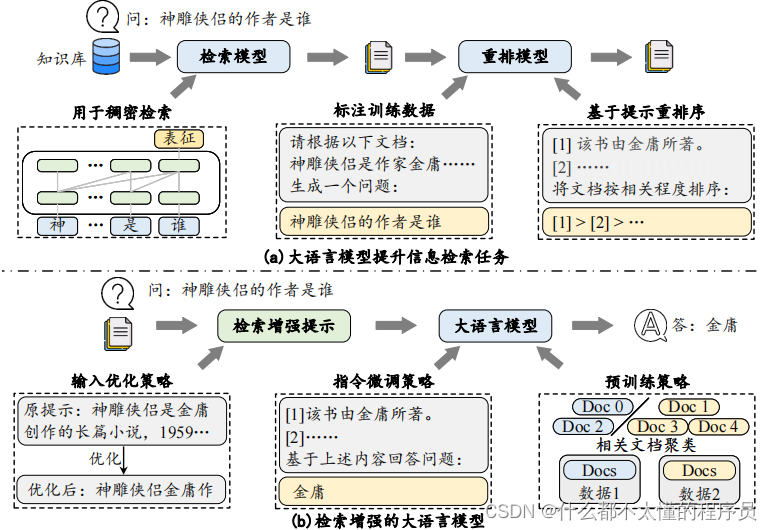
1. MRR (Mean Reciprocal Rank)平均倒数排名:
衡量检索结果排序质量的指标。
计算方式: 对于每个查询,计算被正确检索的文档的最高排名的倒数的平均值,再对所有查询的平均值取均值。
意义: 衡量对于多次查询,检索结果的排名,适用于评估检索结果排序效果好坏的情况。强调“顺序性”。
公式: |Q|表示查询的总次数, r a n k i rank_{i} ranki表示第i次查询中第一个准确结果的排序。
M R R = 1 ∣ Q ∣ ∑ i = 1 ∣ Q ∣ 1 r a n k i MRR = \frac{1}{{|Q|}}\sum_{i=1}^{|Q|}\frac{1}{rank_{i} } MRR=∣Q∣1i=1∑∣Q∣ranki1
2. AP(Average Precision)平均精度:
衡量检索结果排序质量的指标。
计算方式: 一次查询结果正确结果的精确率求和除以查询结果的总数
意义: 衡量对于一个查询,检索结果中所有与 ground-truth相关的文档是否都有较高的排序。AP衡量的是整个排序的平均质量。
公式: K表示一次查询共查询K个文档,Pre代表精确率,Rel(n)表示这次查询结果中的第n个结果相关性分数,这里命中为1,未命中为0。
A P = ∑ n = 1 K P r e @ n ∗ R e l ( n ) K AP = \frac{\sum_{n=1}^{K}Pre@n*Rel(n)}{K} AP=K∑n=1KPre@n∗Rel(n)
2. MAP(Mean Average Precision)平均准确率:
衡量检索结果排序质量的指标。
计算方式: 对于每个查询,计算被正确检索的文档的平均精确率,再对所有查询的平均值取均值。
意义: 衡量对于多个查询,检索结果的平均精确率,适用于评估排序结果精确度的情况。
公式: |Q|表示查询的总次数,AP(i)表示第i次查询的平均精度。
M A P = 1 ∣ Q ∣ ∑ i = 1 ∣ Q ∣ A P ( i ) MAP = \frac{1}{{|Q|}}\sum_{i=1}^{|Q|}AP(i) MAP=∣Q∣1i=1∑∣Q∣AP(i)
3. NDCG(Normalized Discounted Cumulative Gain)归一化折损累积增益:
衡量检索结果排序质量的指标。
计算方式: 对于每个查询,对每个被检索到的结果计算其相对于理想排序的增益值,然后对这些相对增益值进行加权求和,再除以理想排序的增益值。
意义: 衡量对于一个查询,检索结果的绝对和相对排序质量,适用于评估排序结果的质量与排名准确度的情况。
公式: @k表示一次查询搜索k个文档;
N D C G @ k = D C G @ k I D C G @ k NDCG@k = \frac{DCG@k}{IDCG@k} NDCG@k=IDCG@kDCG@k
其中:
DCG@k(Discounted Cumulative Gain)代表这次k个查询结果列表中每个文档与查询的相关程度。
IDCG@k代表最理想的这次k个查询结果列表中的结果。
DCG@k的公式为: Rel(n)表示这次查询结果中的第n个结果相关性分数,这里命中为1,未命中为0。
D C G @ k = ∑ i = 1 k R e l ( i ) log 2 i + 1 R e l ( i ) DCG@k=\sum_{i=1}^{k}\frac{Rel(i)}{\log_{2}{i+1} }Rel(i) DCG@k=i=1∑klog2i+1Rel(i)Rel(i)
IDCG@k是按照Rel(i)从高到低排序的DCG@k
4. Recall(召回率)
计算方式: 对于一个查询,所有被召回的样本中正样本的比例。
意义: 关注于用户感兴趣的物品。
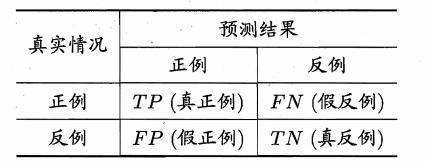
公式: 符号含义见下面的混淆矩阵。
r e c a l l = T P T P + F N recall = \frac{TP}{TP+FN} recall=TP+FNTP
在搜索任务中,R表示检索出的正确文档集合,T表示检索出的所有文档。
r e c a l l = R ∩ T T recall = \frac{R\cap T}{T} recall=TR∩T
5. Hit Rate(Recall@K)命中率
衡量检索结果准确性的指标。
计算方式: 对于一个查询,计算被正确检索的文档的占所有被检索的文档的比例。
意义: 衡量用户想要的项目有没有被检索到,强调预测的“准确性”。
公式:
6. Precision(精确率)
计算方式: 对于一个查询, 预测为正样本的样本中确实为正样本的比例。
意义: 关注于要推荐的物品。
公式: 符号含义见下面的混淆矩阵。
P r e = T P T P + F P Pre = \frac{TP}{TP+FP} Pre=TP+FPTP
在搜索任务中,R表示检索出的正确文档集合,T表示检索出的所有文档。
r e c a l l = R ∩ T T recall = \frac{R\cap T}{T} recall=TR∩T
7. Accuracy (准确率)
计算方式: 预测正确的样本在所有样本中的比例。
意义: 每个样本的预测是否正确。
公式: 符号含义见下面的混淆矩阵。
A C C = T P + T N T P + F P + T N + F N ACC = \frac{TP+TN}{TP+FP+TN+FN} ACC=TP+FP+TN+FNTP+TN
参考
【基础】推荐系统常用评价指标Recall、NDCG、AUC、GAUC
信息检索与数据挖掘 | 【实验】检索评价指标MAP、MRR、NDCG
谈谈NDCG的计算