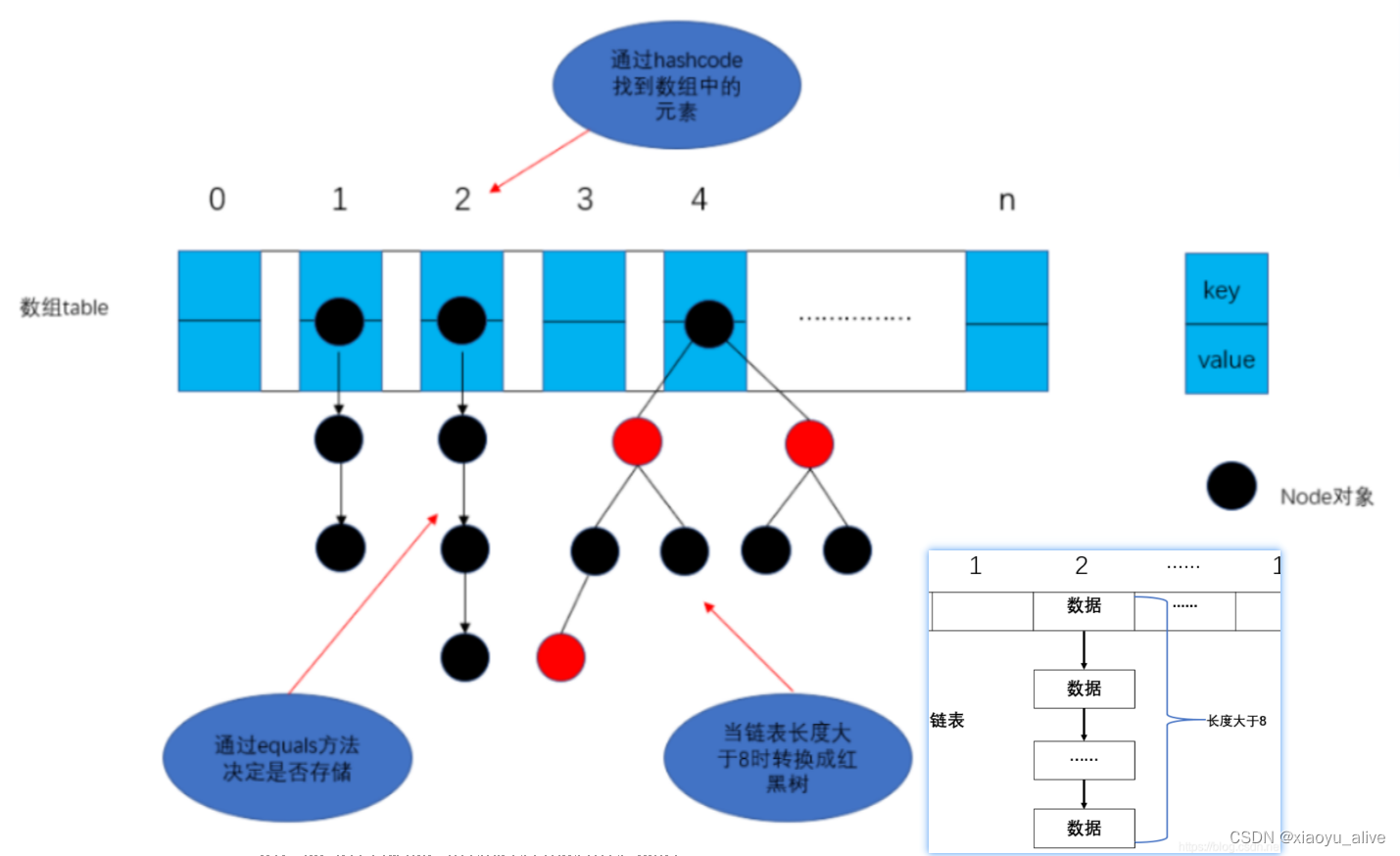
在Java的集合框架中,HashMap无疑是最常用且功能强大的数据结构之一。它基于哈希表实现,能够快速地存储和检索键值对。下面将剖析HashMap中的putVal方法,了解它是如何工作的,以及它背后的设计思想。
putVal方法是HashMap中用于插入键值对的核心方法。它不仅处理了基本的插入逻辑,还涉及了哈希表的初始化、扩容、链表与红黑树的转换等多个关键操作。通过理解这个方法,我们可以更好地掌握HashMap的性能特性和使用场景。
目录
putVal方法详解
1. 初始化与扩容检查
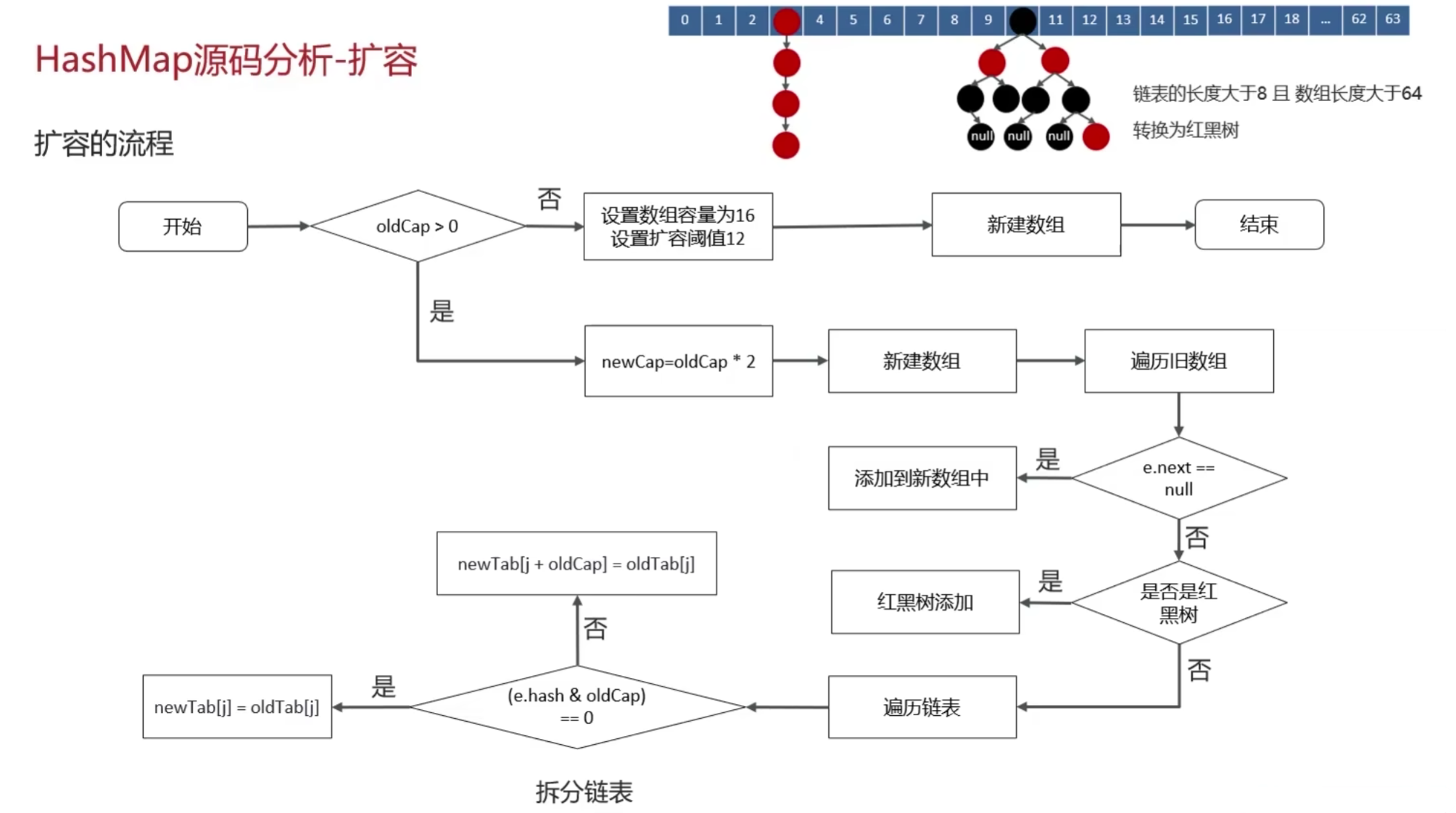
在插入键值对之前,putVal方法首先会检查哈希表(table)是否已经初始化或是否为空。如果未初始化或长度为0,则会调用resize()方法进行初始化或扩容,并更新哈希表的长度(n)。
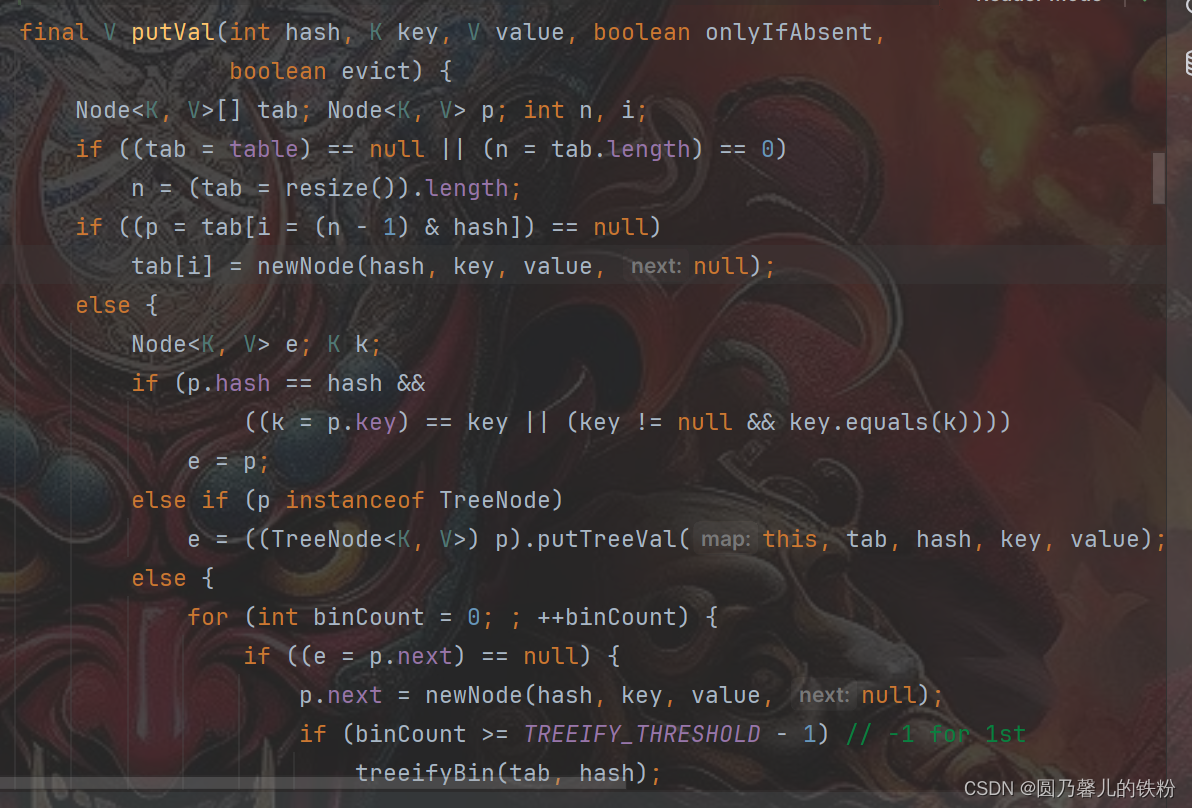
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;2. 计算索引并插入新节点
接下来,putVal方法使用(n - 1) & hash计算键的哈希值对应的索引i。如果索引i处的节点p为空,则创建一个新节点并放置在索引i处。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);3. 处理键已存在的情况
如果索引i处的节点p不为空,则需要进一步处理:
- 检查哈希值和键是否相同:如果
p的哈希值和键都与要插入的键值对相同,则直接更新p的值(如果需要的话)。 - 红黑树处理:如果
p是一个TreeNode(即红黑树的节点),则调用putTreeVal方法在红黑树中插入或更新键值对。 - 链表处理:如果
p是一个普通链表节点,则遍历链表查找是否存在相同的键。如果不存在,则在链表末尾添加新节点;如果存在,则更新该节点的值(如果需要的话)。
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}4. 扩容检查
插入新节点后,putVal方法会检查哈希表的大小是否超过了阈值(threshold)。如果是,则调用resize()方法进行扩容,以确保哈希表的性能不会因为元素过多而下降。
if (++size > threshold)
resize();5. 其他操作
在插入操作完成后,putVal方法还会执行一些后续操作,如更新modCount(修改次数)和调用afterNodeInsertion方法(如果有的话)。这些操作对于维护哈希表的内部状态和外部行为至关重要。
++modCount;
afterNodeInsertion(evict);
return null;总结
通过对putVal方法的深入剖析,我们可以看到HashMap在插入键值对时所做的复杂而精细的处理。这些处理不仅保证了哈希表的高效性和可扩展性,还为其在各种场景下的应用提供了坚实的基础。希望这篇文章能够帮助你更好地理解HashMap的工作原理和使用方法。