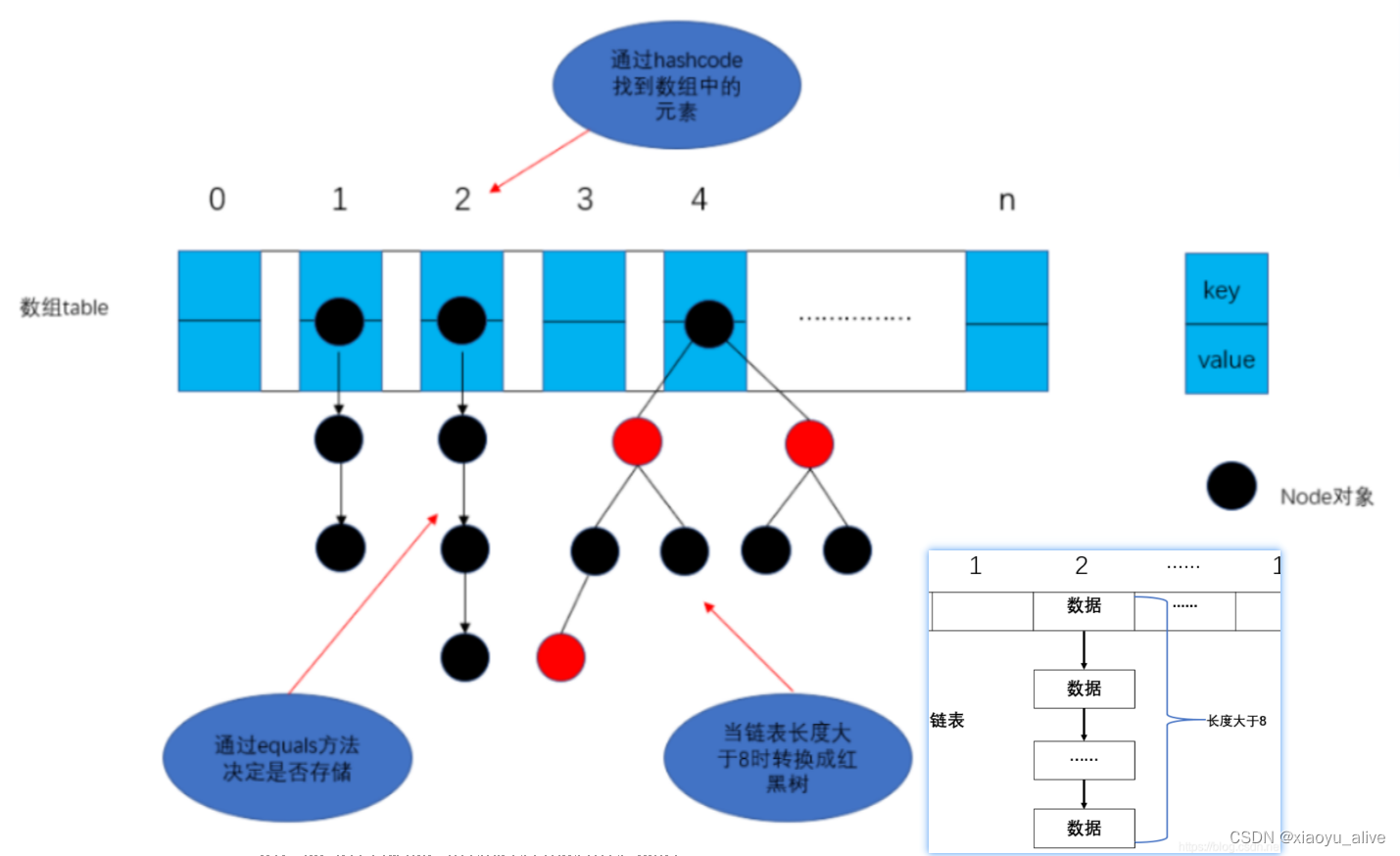
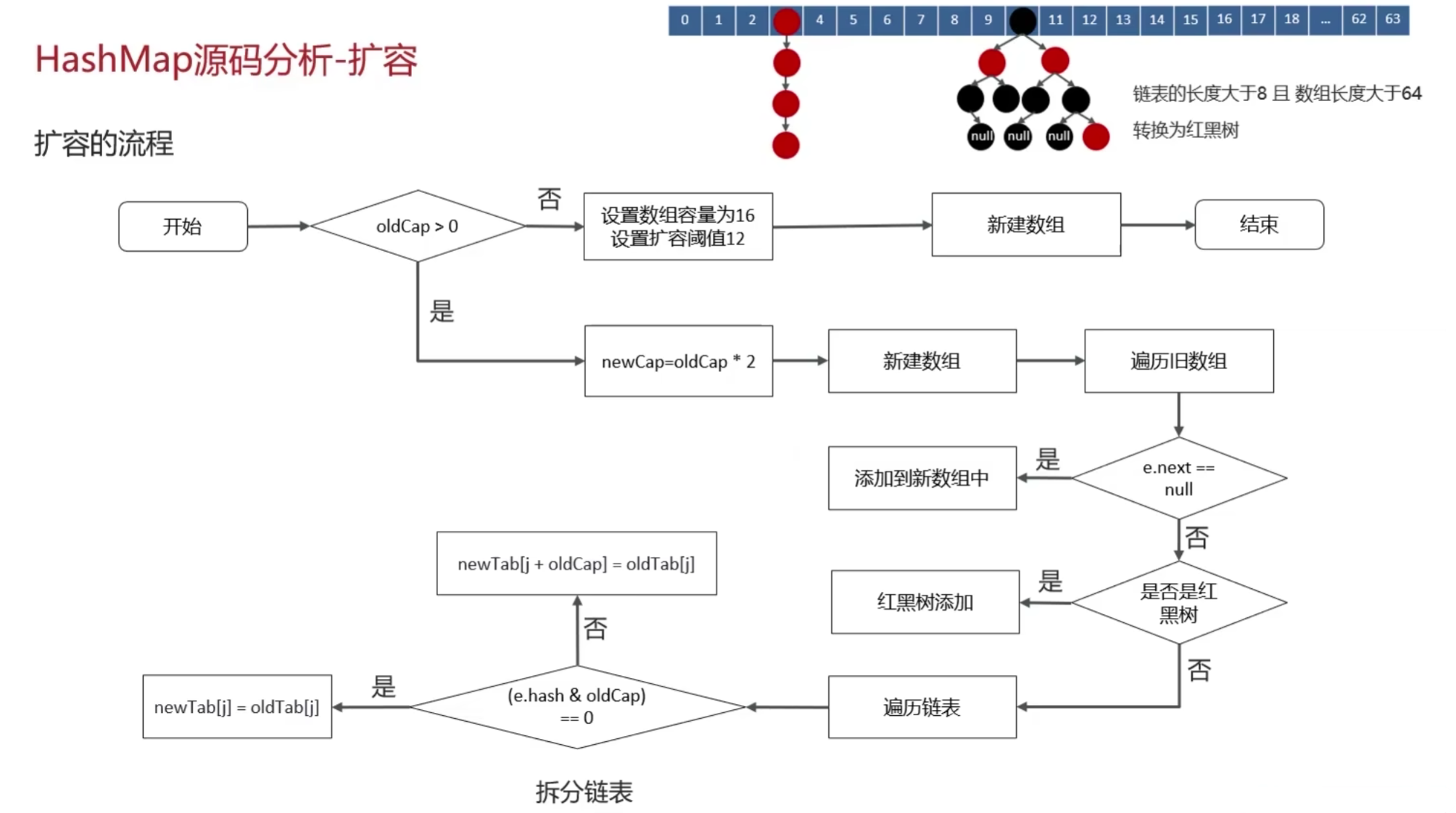
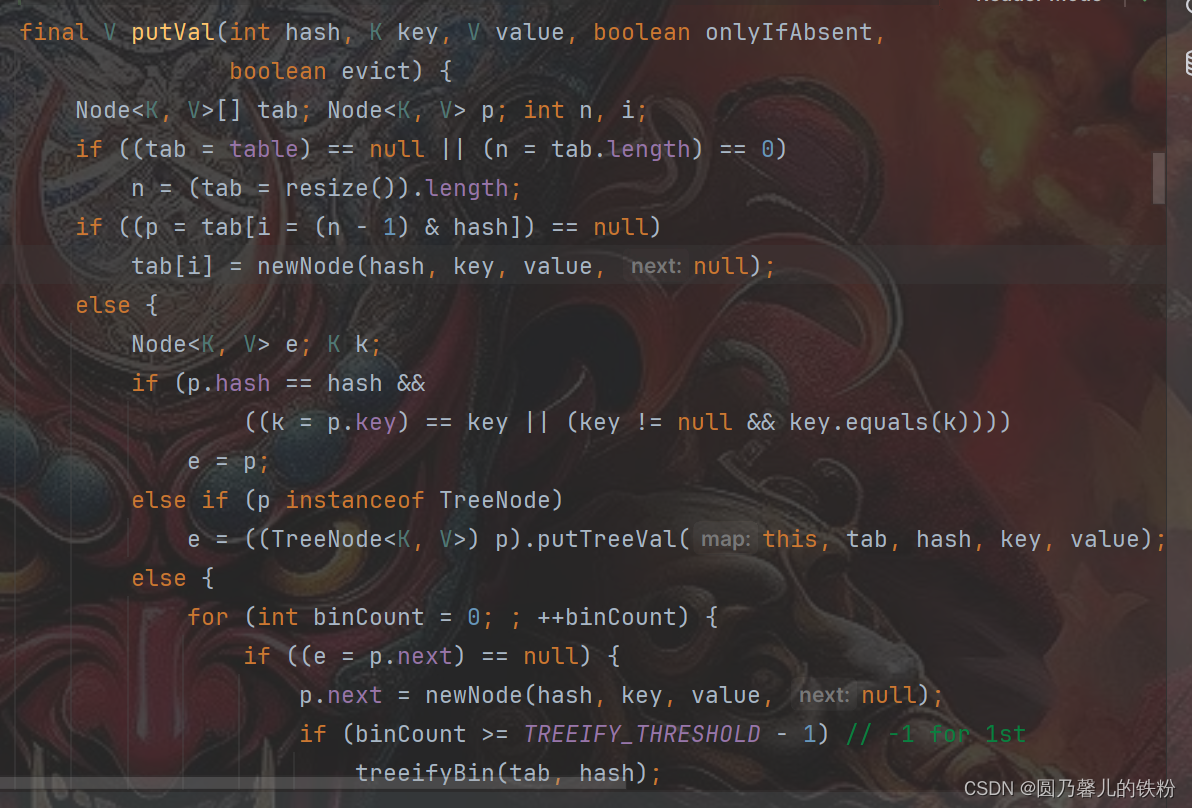
一、序言
本文介绍 HashMap 中的 resize() 源码。
二、源码概览
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 创建新的 Hash 表
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
上述代码是 HashMap 中 resize() 方法的源码,有兴趣的小伙伴可以先试着读一下哦。
三、源码分析
3.1 获取原 Hash 表参数
// 保存旧 Hash 表数组
Node<K,V>[] oldTab = table;
// 保存旧 Hash 表容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 保存旧 Hash 表阈值(阈值就是扩容的边界条件)
// 例如:Hash 表的初始容量是 16,加载因子是 0.75,阈值即是 16 * 0.75 = 12
// 若 Hash 表数组中的数据达到 12 就会触发扩容
int oldThr = threshold;
3.2 计算新 Hash 表容量和阈值
// 初始化新的 Hash 表。容量、阈值都为 0
int newCap, newThr = 0;
// 如果旧容量大于 0,则进行扩容操作
if (oldCap > 0) {
// 如果旧容量已经达到最大容量限制,则将阈值设置为最大整数值,并返回旧哈希表
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 否则,新容量为旧容量的两倍,但不能超过最大容量限制,并且旧容量不能低于默认的初始容量
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // 阈值翻倍
}
// 如果旧容量为 0,但是阈值大于 0,则使用阈值作为新容量
else if (oldThr > 0)
newCap = oldThr;
// 如果旧容量和阈值都为 0,则使用默认的初始容量和负载因子来计算新容量和阈值
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
这段代码的作用是根据哈希表的旧容量和旧阈值来计算出扩容后的新容量和新阈值,以便在扩容时能够按照一定的策略进行扩容,并保持哈希表的性能。

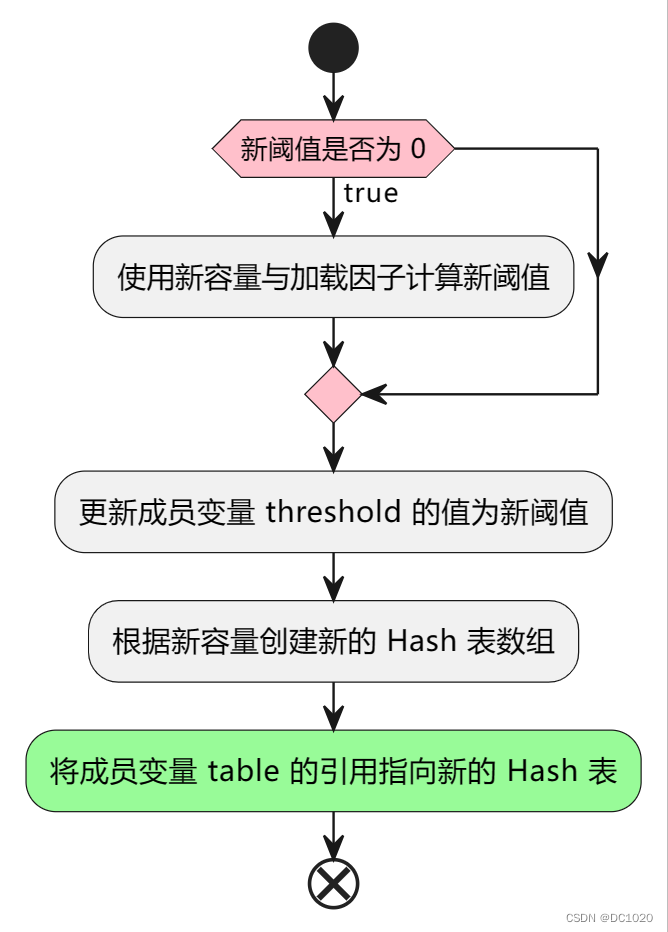
3.3 创建新 Hash 表
// 如果新的阈值为 0,则根据新的容量和负载因子计算新的阈值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 更新阈值
threshold = newThr;
// 创建新的哈希表数组
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
// 更新哈希表数组的引用
table = newTab;
这段代码的作用是根据计算出的新容量和负载因子重新计算阈值,然后根据新容量创建一个新的哈希表数组,并将哈希表的引用指向新的数组,完成哈希表的扩容操作。
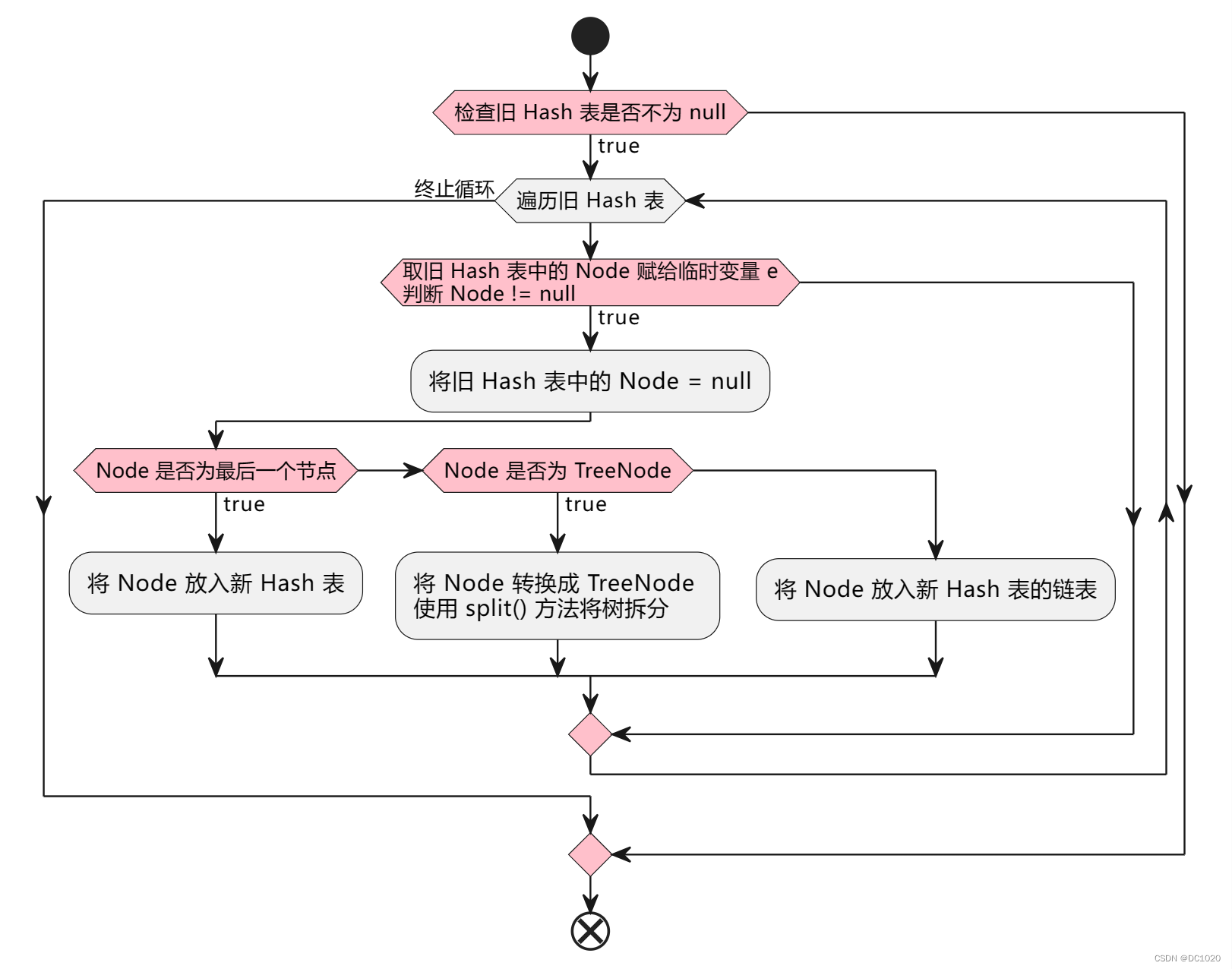
3.4 将旧 Hash 表中节点重新分配到新 Hash 表
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
上面这段源码还是有点过于复杂,我们分拆一下。
3.4.1 重新分配核心逻辑
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 省略移入新 Tab 链表的逻辑
}
}
}
}
这段代码负责遍历旧哈希表中的每个位置,将节点重新分配到新哈希表中的正确位置。如果节点是链表中的最后一个节点,则直接放置在新哈希表中的相应位置上;如果节点是树节点,则进行树节点的拆分;否则,根据节点的顺序将节点移动到新哈希表中的适当位置。
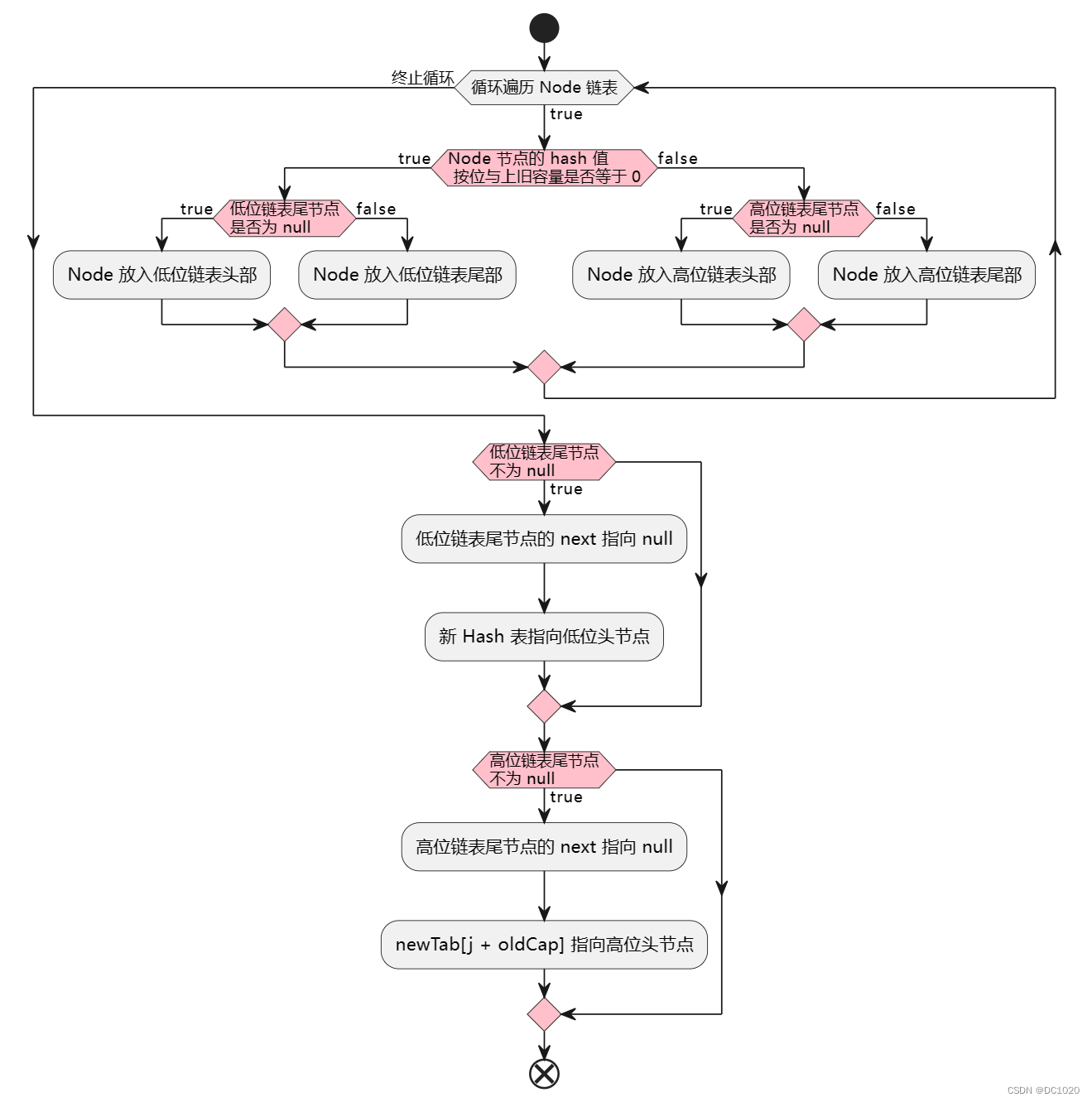
3.4.2 重新分配放入链表的逻辑
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
这段代码的作用是将原链表中的节点按照哈希值和旧容量的关系重新分配到新的哈希桶中,以保证在哈希表扩容时仍然能够维持良好的性能。
四、resize() 扩容核心逻辑
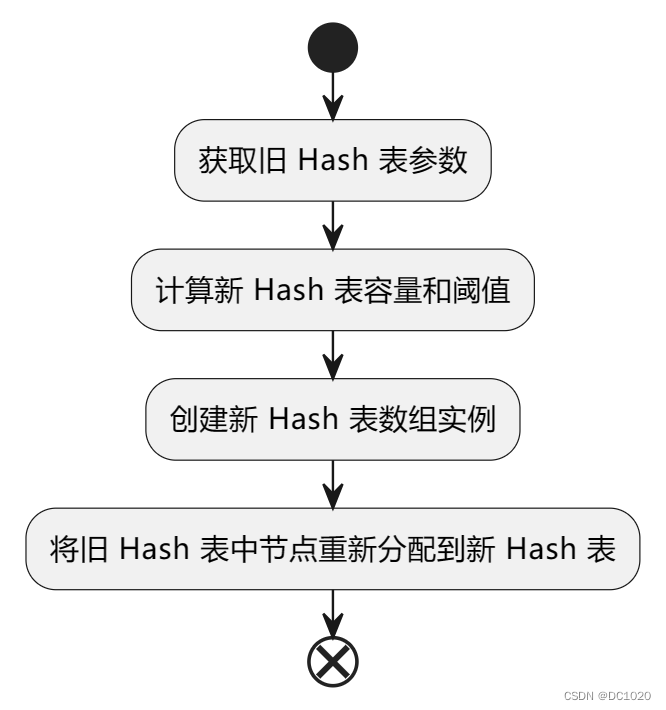
- 获取旧 Hash 表参数(包括旧 Hash 表、旧 Hash 表容量、旧 Hash 表阈值)
- 通过旧 Hash 表参数计算新 Hash 表容量和阈值
- 通过新 Hash 表的容量和阈值参数创建新 Hash 表数组实例
- 将旧 Hash 表中节点重新分配到新 Hash 表中
五、FAQ
5.1 高位链表、低位链表是什么
当哈希表进行扩容时,通常会将哈希桶的容量扩大为原来的两倍。假设原哈希表的容量为 16,扩容后容量为 32。在这种情况下,原来的哈希桶可以分为两部分:低位桶和高位桶。
- 低位桶包含哈希值的高位为 0 的节点,其哈希值的二进制表示中最高位为 0。
- 高位桶包含哈希值的高位为 1 的节点,其哈希值的二进制表示中最高位为 1。
通过划分低位桶和高位桶,可以使得在扩容过程中,不同的节点只需进行简单的移位操作,而无需重新计算哈希值和调整位置。这样可以大大提高扩容的效率。
举个简单例子:假设有一个哈希表,其中包含以下节点(简化表示):
| Key | Hash Value (Binary) |
|---|---|
| A | 0001 |
| B | 0010 |
| C | 1001 |
| D | 1010 |
如果原哈希表容量为 4,扩容后容量为 8。在扩容时,节点可以被分为低位桶和高位桶:
低位桶:
| Key | Hash Value (Binary) |
|---|---|
| A | 0001 |
| B | 0010 |
高位桶:
| Key | Hash Value (Binary) |
|---|---|
| C | 1001 |
| D | 1010 |
在扩容时,低位桶中的节点 A 和 B 只需将哈希值的高位补为 0 即可得到新的哈希值,而高位桶中的节点 C 和 D 只需将哈希值的高位补为 1 即可得到新的哈希值。这样就避免了重新计算哈希值和节点的移动,提高了扩容的效率。
5.2 TreeNode 中 split() 方法的作用
split() 方法的作用:
- 首先,它会判断节点所在的哈希桶在扩容后的新数组中的位置。根据节点的哈希值和新数组的长度,确定节点在新数组中的索引位置。
- 然后,它会根据节点的哈希值的高位是 0 还是 1,将节点拆分成两个链表:低位链表和高位链表。这个拆分过程是为了在扩容后保持节点的相对顺序,以便正确地重新分配节点到新的哈希桶中。
- 最后,它会将拆分后的两个链表重新分配到新的哈希表中的对应位置,保持它们的相对顺序。
总之,split() 方法在哈希表扩容时,帮助将节点分割成两个链表,并将它们重新分配到新的哈希表中,以保持节点的相对顺序,并提高扩容的效率。