前言:
Multi-Head Attention 主要作用:将Q,K,V向量分成多个头,形成多个子语义空间,可以让模型去关注不同维度语义空间的信息
目录:
- attention 机制
- Multi-Head Attention
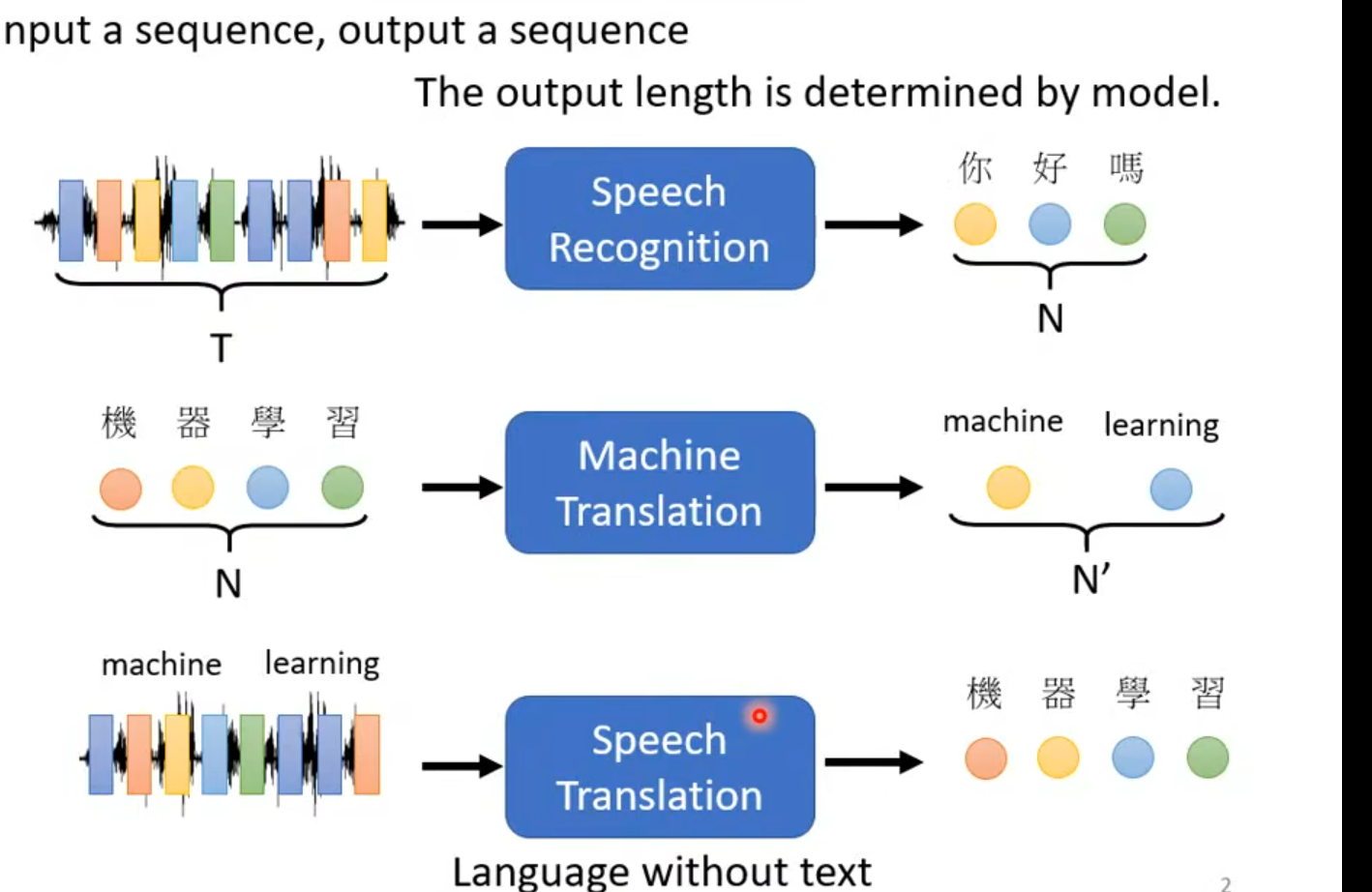
一 attention 注意力
Self-Attention(自注意力机制):使输入序列中的每个元素能够关注并加权整个序列中的其他元素,生成新的输出表示,不依赖外部信息或历史状态。
将查询Query,键Key,值Value 映射 到输出。
查询Query,键Key, 值Value 都是向量.
其输出为 值的加权求和。

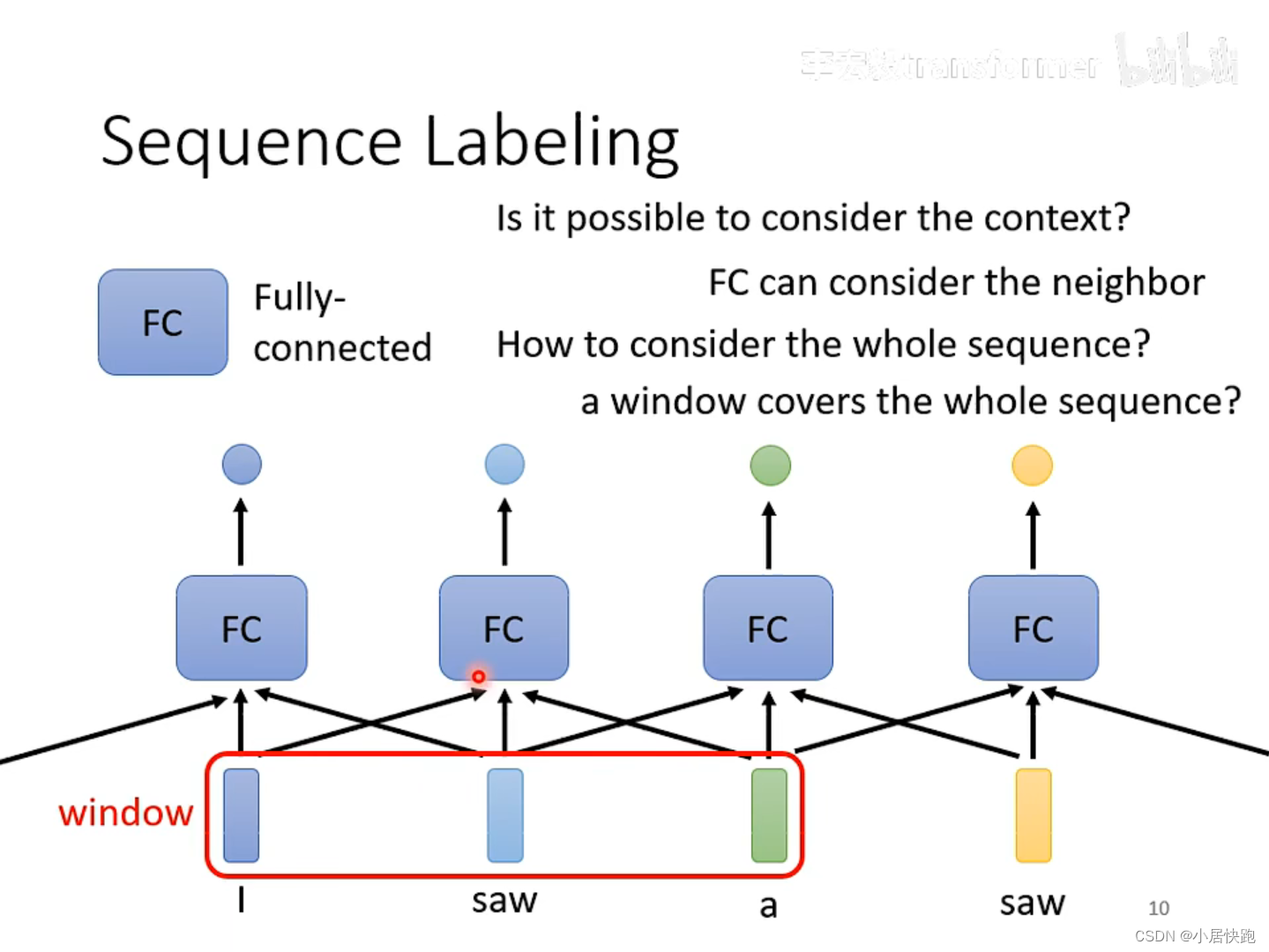
1.1 mask 作用

1.2 scale 作用

# -*- coding: utf-8 -*-
"""
Created on Tue Jul 16 11:21:33 2024
@author: chengxf2
"""
import torch
import math
def attention(query,key ,value, mask=None):
#[batchSize, seq_num, query_dim]
d_k = query.size(-1)
print(d_k)
attentionMatrix = torch.matmul(query, key.transpose(-2,-1))
scores = attentionMatrix/math.sqrt(d_k)
if mask is not None:
scores = scores.mask_fill(mask==0, -1e9)
p_attn = torch.softmax(scores, dim=-1)
out = torch.matmul(p_attn, value)
return out
seq_len = 5
hid_dim = 10
out_len =3
query = torch.rand((seq_len,hid_dim))
key = torch.rand_like(query)
value = torch.rand((seq_len, out_len))
attention(query, key, value)二 Multi-Head Attention
多头注意力机制的理论基础之一是信息多元化处理的思想。通过将输入向量投影到不同的子空间,每个子空间执行自注意力操作,这样模型能够并行地学习不同类型的特征或依赖关系,增强了模型的表达能力。


2,1 第一步:查询Q、键K 和值V 矩阵的 生成
输入:
张量A
shape: [batch, seq_len, input_dim]
输出:
Q,K,V
shape:[batch,seq_len, query_dim]
(下面以输入seq_len=2 ,为例)

其中下面三个矩阵是需要学习的矩阵:
的shape 为【input_dim, query_dim]
2.2 第二步:子空间投影
Q,K V 乘以对应的Head 矩阵,得到对应的mulite-head Q,K,V

以 Query张量为例: 实现的时候先乘以Head 矩阵 ,然后再通过View 功能
分割成子空间。

第三步: 对不同Head 的Q,K,V
做self-attention,得到不同Head 的
第四步: concate

import torch
from torch import nn
# 假设我们有一些查询、键和值的张量
query = torch.rand(10, 8, 64) # (batch_size, n_query, d_model)
key = value = query # 为了示例,我们使用相同的张量作为键和值
# 实例化多头注意力层
multihead_attn = nn.MultiheadAttention(embed_dim=64, num_heads=4)
# 执行多头注意力操作
output, attention_weights = multihead_attn(query, key, value)
print(output.shape) # 输出: torch.Size([10, 8, 64])
print(attention_weights.shape) # 输出: torch.Size([10, 4, 8, 8])
# -*- coding: utf-8 -*-
"""
Created on Wed Jul 17 09:46:40 2024
@author: chengxf2
"""
import torch
import torch.nn as nn
import copy
import math
from torchsummary import summary
import netron
def clones(module, N):
"生成N 个 相同的层"
layers = nn.ModuleList(
[copy.deepcopy(module) for _ in range(N)]
)
return layers
def attention(query, key ,value):
#输出[batch, head_num, seq_len,query_dim ]
seq_num = query.size(-1)
scores = torch.matmul(query, key.transpose(-2,-1))
scores = scores/math.sqrt(seq_num)
p_attn = torch.softmax(scores, dim=-1)
out = torch.matmul(p_attn, value)
print("\n out.shape",out.shape)
return out, p_attn
class MultiHeadedAttention(nn.Module):
def __init__(self, head_num, query_dim):
super(MultiHeadedAttention, self).__init__()
self.head_num = head_num
self.sub_query_dim = query_dim//head_num
self.linears = clones(nn.Linear(query_dim,query_dim), 4)
self.attn = None
def forward(self, query, key, value):
#query.shape [batch, seq_num,query_dim]
batchSz = query.size(0)
#[batchsz, seq_num, head_num, query_dim]
query, key, value = \
[net(x).view(batchSz, -1, self.head_num, self.sub_query_dim).transpose(1, 2)
for net, x in zip(self.linears, (query, key, value))]
#输出[batch, head_num, seq_len,sub_query_dim ]
x, self.attn = attention(query, key, value)
print("\n attn ",self.attn)
x = x.transpose(1,2).contiguous().view(batchSz,-1,self.head_num*self.sub_query_dim)
out = self.linears[-1](x)
print(out.shape)
return out
if __name__ == "__main__":
batchSz=1
seq_num =2
out_dim=query_dim =9
head_num =3
#下面这三个矩阵是需要学习的矩阵
query = torch.randn((batchSz, seq_num, query_dim))
key = torch.rand_like(query)
value =torch.randn((batchSz, seq_num, out_dim))
model = MultiHeadedAttention(head_num,query_dim)
model(query,key,value)
print("\n 模型参数 \n ")
input_size = (seq_num, query_dim)
summary(model,[input_size,input_size,input_size])
# 创建一个输入样本
input_dict = {"x1": query, "x2": key, "x3":value}
# 导出模型为ONNX格式
torch.onnx.export(model, # 模型实例
(query,key,value), # 模型输入
"model.onnx")
netron.start('model.onnx')
![【PyTorch][chapter <span style='color:red;'>26</span>][<span style='color:red;'>李</span><span style='color:red;'>宏</span><span style='color:red;'>毅</span><span style='color:red;'>深度</span><span style='color:red;'>学习</span>][<span style='color:red;'>attention</span>-1]](https://i-blog.csdnimg.cn/direct/8c2d16dcea8b43fc9fa948993e2651db.png)
![【PyTorch][chapter <span style='color:red;'>25</span>][<span style='color:red;'>李</span><span style='color:red;'>宏</span><span style='color:red;'>毅</span><span style='color:red;'>深度</span><span style='color:red;'>学习</span>][ CycleGAN]【实战】](https://img-blog.csdnimg.cn/direct/98090648d63f41e8ba7ccf51065d78f6.png)
![[PyTorch][chapter <span style='color:red;'>2</span>][<span style='color:red;'>李</span><span style='color:red;'>宏</span><span style='color:red;'>毅</span><span style='color:red;'>深度</span><span style='color:red;'>学习</span>-Regression]](https://img-blog.csdnimg.cn/8fb0d0058b864981becfb8399072d552.png)



























![GIT--git clone fatal [文件过大或网络不稳定] [大型仓库]](https://i-blog.csdnimg.cn/direct/5a3c6e43b8ce40b38944398064fa08b4.png)







