前言:
attention 在自然语言处理,声音处理里面是一个很重要的技巧.
attention 要解决的是输入的向量长度不定.

根据输入输出的不同,分为三种场景:
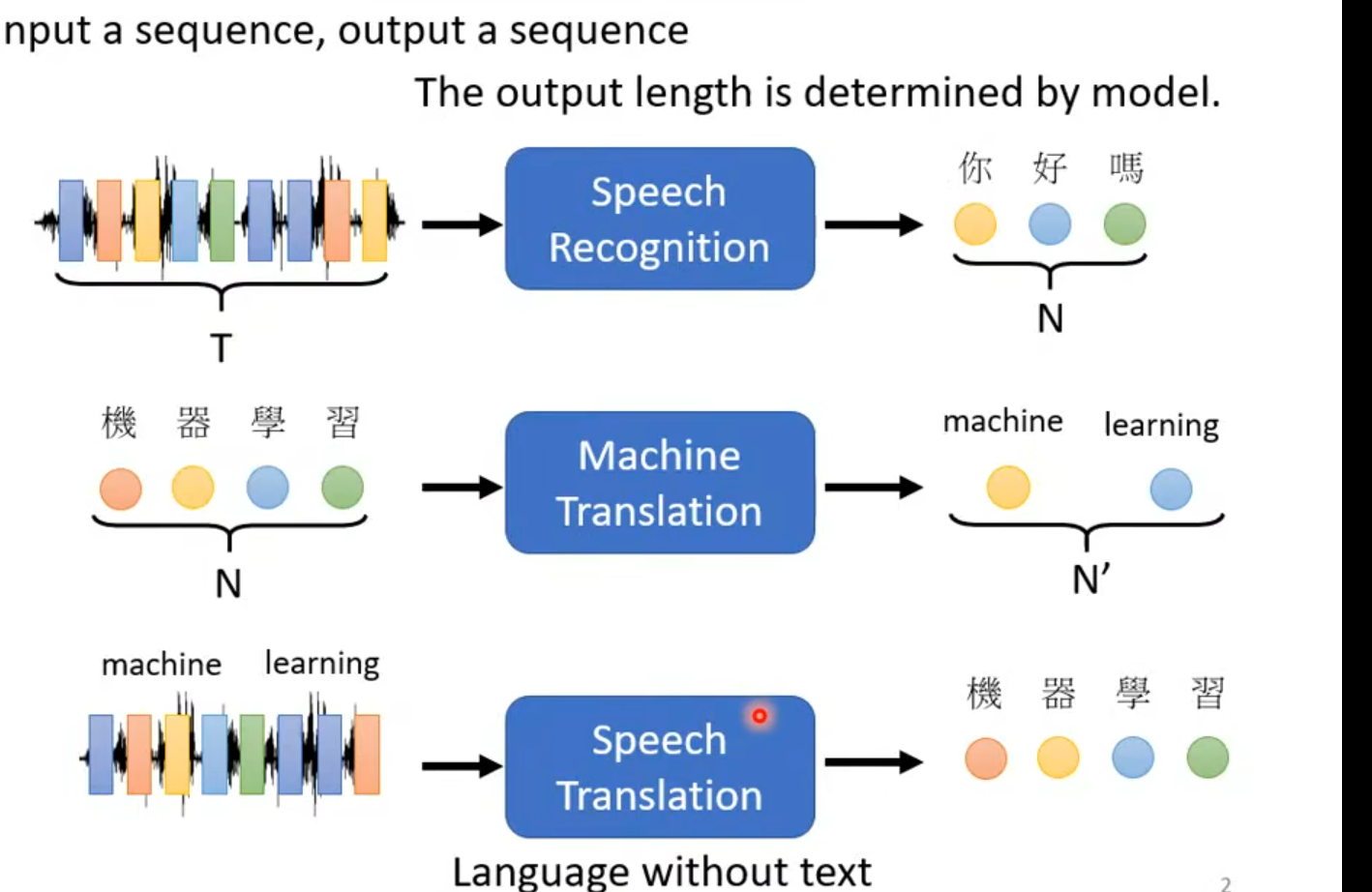
输入N个向量,输出N个向量,这是本章的重点
输入N个向量,输出向量不定
输入N个向量, 输出M个向量

目录:
- 相关方案
- self-attention
- code实现
一 相关方案
1.1 全连接网络
输入: N个向量
模型: N个全连接网络,每个FC模型对应一个向量
输出: N个向量
缺点:
是当前向量无法获得其他向量的信息

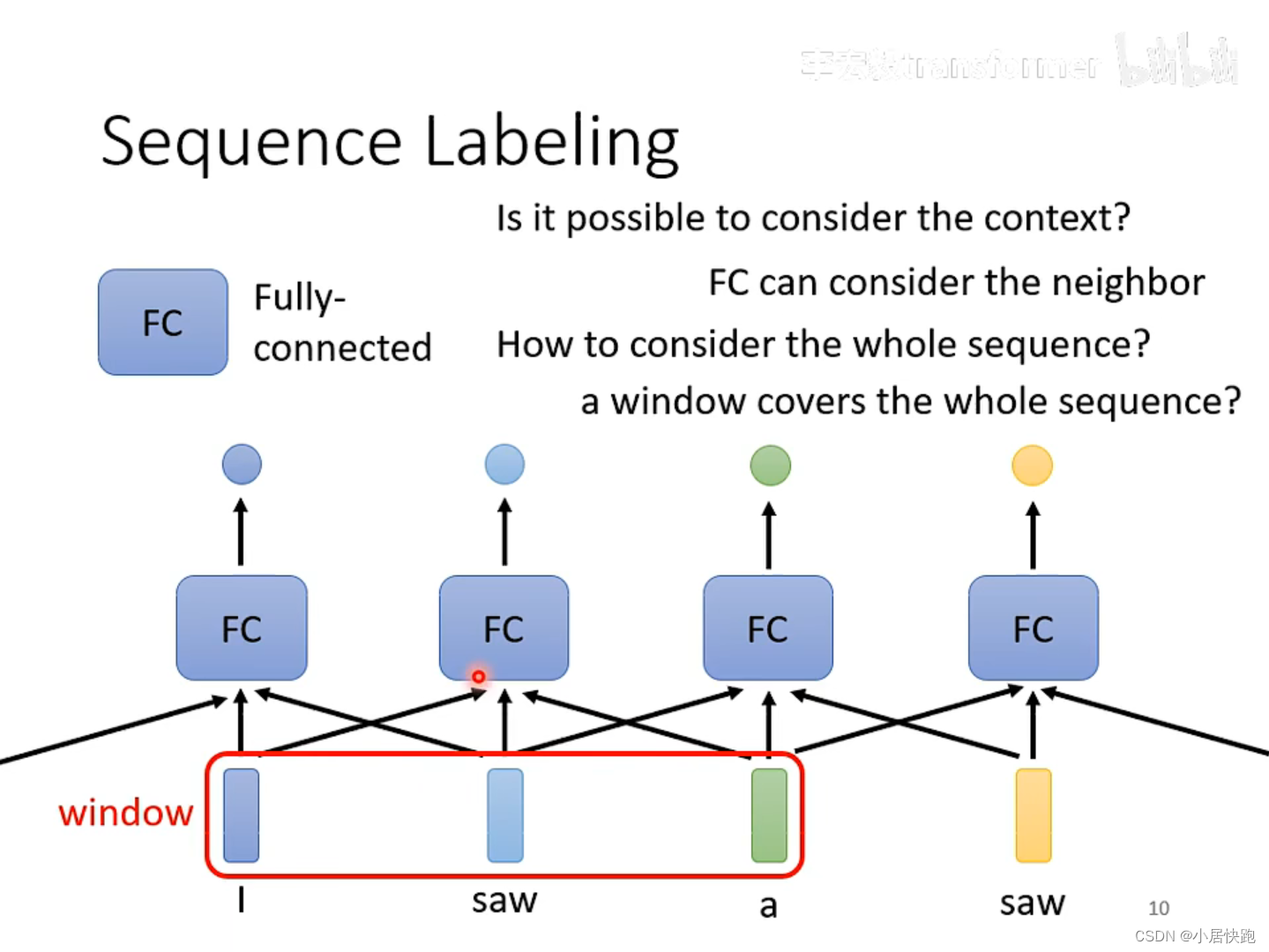
1.2 问题
输入: N个向量
模型: N个全连接网络,每个全连接网络,输入N个向量.
输出: N个向量
缺点:
向量的个数定义Windows窗口.如果窗口特别大,计算量特别大。
如果windows 窗口特别小,无法采集到整个Input sequence Labeling

需要开的窗口特别大
二 self-attention
3.1 模型架构

输入 N个向量
输出: N 个向量
模型: Self-attention
3.2 主要流程

1.1 计算相关系数
两个向量的相似度有很多表达方式,例如余弦

attention 是通过self-attention 来计算,比如要计算之间的相似度

其中:
是代表query,key 矩阵通过训练出来的
Query:查询向量,表示要关注或检索的目标
Key: 键向量,表示要与查询向量进行匹配或比较的源

还有种Additive 结构
2.2 通过相关系数 ,计算attention-score
同理依次算出来跟其它向量之间的相似度

对相似度矩阵,通过softmax 归一化后,得到attention-score.

attention-score,本质上是代表权重系数
2.3 根据attention-score , 重新计算向量
Value:值向量,表示要根据查询向量和键向量的匹配程度来加权求和的信息
通过attention-score 加权求和得到

三 代码
- Query:查询向量,表示要关注或检索的目标
- Key:键向量,表示要与查询向量进行匹配或比较的源
- Value:值向量,表示要根据查询向量和键向量的匹配程度来加权求和的信息
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 9 21:15:05 2024
@author: cxf
"""
# -*- coding: utf-8 -*-
"""
Created on Thu Jul 4 10:37:27 2024
@author: chengxf2
"""
import torch
import torch.nn.functional as F
import torch.nn as nn
class Attention(nn.Module):
def __init__(self, in_features,query_features,out_features):
super(Attention, self).__init__()
self.QUERY = nn.Linear(in_features, query_features)
self.KEY = nn.Linear(in_features, query_features)
self.VALUE = nn.Linear(in_features, out_features)
def forward(self,inputs):
Q = self.QUERY(inputs)
K = self.KEY(inputs)
V = self.VALUE(inputs)
#计算attention
d_k= Q.shape[-1]
alpha = torch.matmul(Q, K.T)/d_k**0.5
attention_score =F.softmax(alpha,dim=1)
print("\n attention_score:",attention_score)
out = torch.matmul(attention_score, V)
row_index =1
row_sum = torch.sum(attention_score[row_index,:])
print("\n row_sum ",row_sum)
return out
seq_len =5
in_features = 7
query_features =4
out_features = 3
X = torch.randn((seq_len, in_features))
net =Attention(in_features, query_features, out_features)
out = net(X)
参考:
Transformer终于有拿得出手得教程了! 台大李宏毅自注意力机制和Transformer详解!通俗易懂,草履虫都学的会!_哔哩哔哩_bilibili
![【PyTorch][chapter <span style='color:red;'>26</span>][<span style='color:red;'>李</span><span style='color:red;'>宏</span><span style='color:red;'>毅</span><span style='color:red;'>深度</span><span style='color:red;'>学习</span>][<span style='color:red;'>attention</span>-2]](https://i-blog.csdnimg.cn/direct/c1e7851b100f432586fd0e1c0768860a.png)
![【PyTorch][chapter <span style='color:red;'>25</span>][<span style='color:red;'>李</span><span style='color:red;'>宏</span><span style='color:red;'>毅</span><span style='color:red;'>深度</span><span style='color:red;'>学习</span>][Transfer Learning-<span style='color:red;'>1</span>]](https://img-blog.csdnimg.cn/direct/42b8d4d6a2ff4135b9155df74ff3485d.png)
![【PyTorch][chapter <span style='color:red;'>25</span>][<span style='color:red;'>李</span><span style='color:red;'>宏</span><span style='color:red;'>毅</span><span style='color:red;'>深度</span><span style='color:red;'>学习</span>][ CycleGAN]【实战】](https://img-blog.csdnimg.cn/direct/98090648d63f41e8ba7ccf51065d78f6.png)