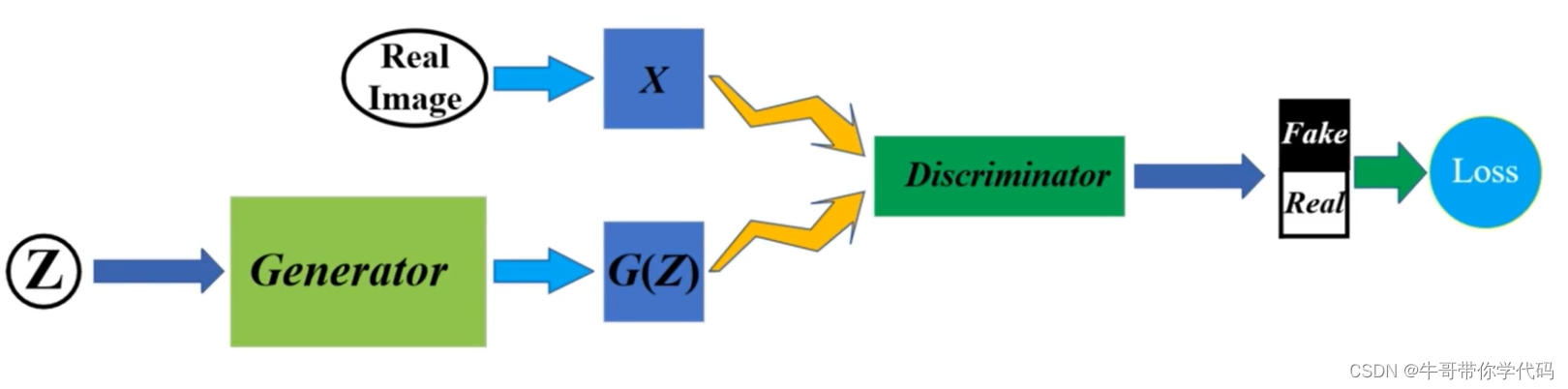
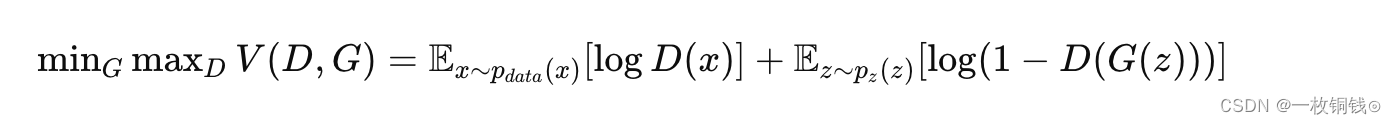拟议的 HiFiGAN 可从中间表征生成原始波形
源码地址:https://github.com/NVIDIA/DeepLearningExamples
论文地址:https://arxiv.org/pdf/2010.05646.pdf
研究要点包括
- **挑战:**基于 GAN 的语音波形生成方法在质量上不及自回归模型和基于流量的模型。
- **解决方法:**提出 HiFi-GAN,以实现高效、高质量的语音合成。
- **要点:**现在,单个 V100 GPU 就能生成 22.05 kHz 的高质量音频。
这意味着高质量的原始语音现在可以通过一种名为 "mel-spectrogram "的语音中间表示有效生成。
神经声码器和语音合成领域的背景
近年来,随着深度学习技术的发展,语音合成技术突飞猛进。
大多数神经语音合成模型采用两阶段管道
- 预测中间表征,如文本中的熔谱图。
- 从中间表征合成原始波形。
本文的重点是模型设计的第二阶段,即**“从熔体频谱图中高效生成高质量语音波形”**。
顺便提一下,这种第二阶段模型通常被称为 “神经译码器”,是许多研究的主题。
| 以前的工作 | 问题 |
|---|---|
| 波网 | 利用卷积神经网络实现高质量语音合成。 |
| 基于流量的模型,如 Parallel WaveNet 和 WaveGlow。 | 并行计算实现更高速度 |
| MelGAN 与 GAN | 结构紧凑,合成速度快。 |
顺便提一下,语音合成领域的一个共同问题是,由于语音是由不同周期的正弦信号组成的,因此必须对语音的周期模式进行建模。
拟议方法:HiFi-GAN 概述
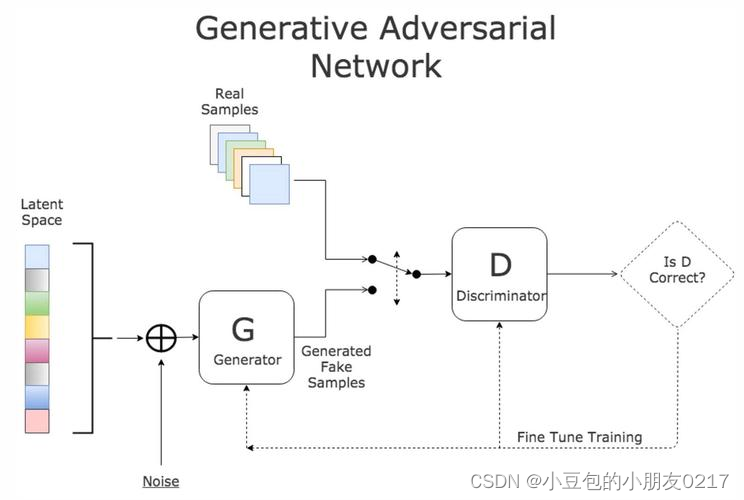
本研究中的 HiFiGAN 是一种基于 GAN 的生成模型,它可以
来源:https://pytorch.org/hub/nvidia_deeplearningexamples_hifigan/
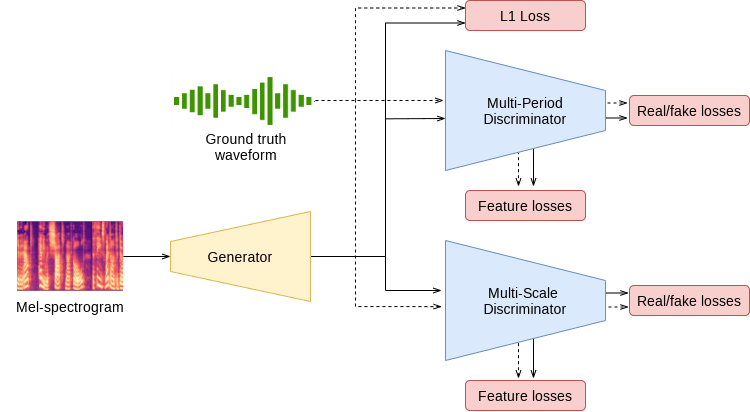
具体来说,它由一个发生器和两个判别器组成:多周期判别器(MPD)和多尺度判别器(MSD)。
发电机
HiFi-GAN 生成器由一个全卷积神经网络组成。

将mel 频谱图作为输入,通过转置卷积重复进行升采样,并进行扩展,直到输出序列的长度与原始语音波形的时间分辨率相匹配。
每个转置卷积后还会有一个多感受场融合(MRF)模块。
多感知场融合(MRF)
MRF 模块旨在并行捕捉不同长度的模式。具体来说,MRF 模块返回多个残差块的输出总和。
每个残差块都有不同的内核大小和扩张率,以形成各种感受野模式。
鉴别器
HiFi-GAN 使用以下两个标识符。
- 多周期判别器(MPD)
- 多尺度判别器 (MSD)
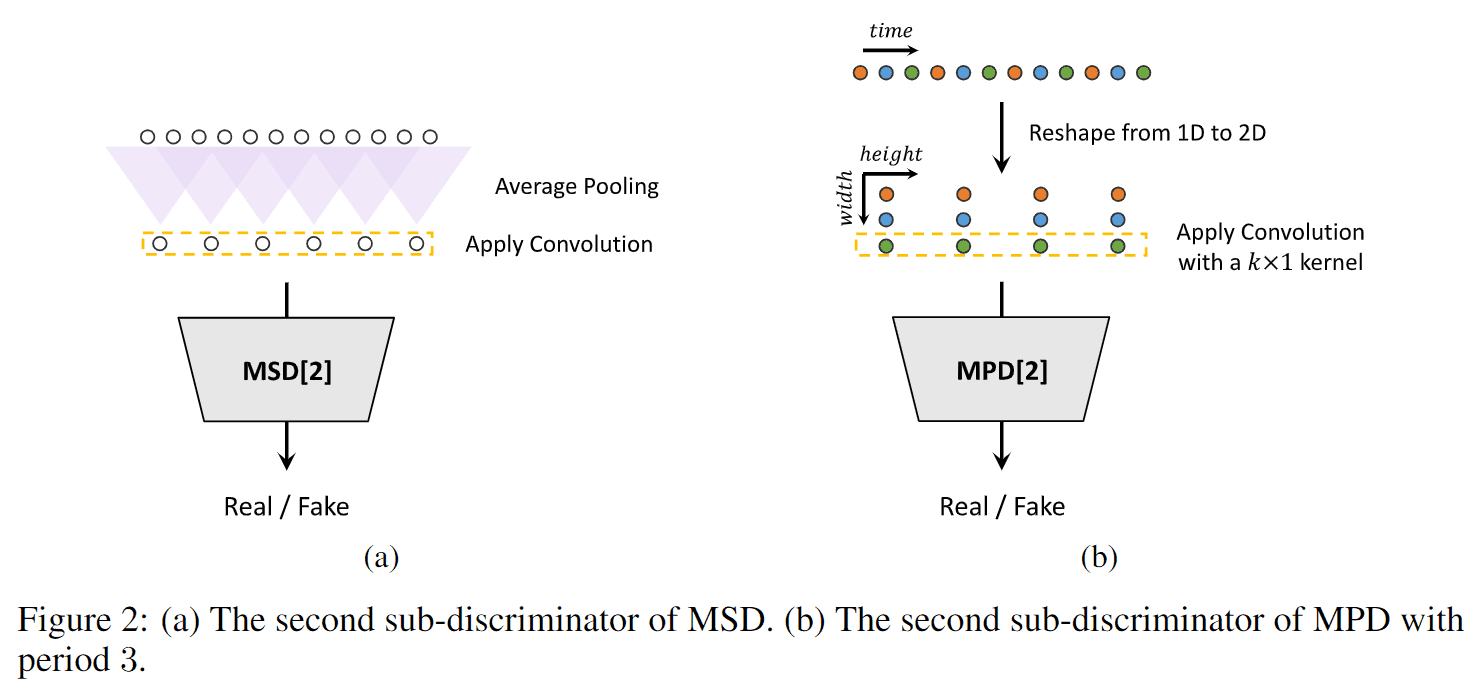
MPD 由多个子识别器组成,每个子识别器只接收来自输入语音的等间距采样信号。这使得每个子识别器都能关注输入语音中的不同周期模式,从而捕捉语音中固有的各种周期结构。
MSD 还能通过连续评估不同尺度的输入语音,捕捉连续模式和长期依赖关系。具体地说,它由三个子鉴别器组成,有三种输入语音类型:原始语音、1/2 降低采样率的语音和 1/4降低采样率的语音。
因此,通过结合 MPD 和 MSD,HiFi-GAN 被认为能够从生成语音的详细周期特征和全局连续特征等多个角度进行评估
损失函数
HiFi-GAN 研究使用了四种损失函数
- GAN 损失(对抗损失)
- 梅尔谱仪损失
- 特征匹配损失
- 最终损失函数(最终损失)
GAN 损失(对抗损失)
在GAN Loss(对抗损失)中,MPD 和 MSD 被视为一个判别器,并使用 LSGAN 目标函数。鉴别器学会将真实语音分类为 1,将生成语音分类为 0,而生成器学会欺骗鉴别器。
梅尔谱仪损失
梅尔谱图损失(Mel-Spectrogram Loss)在GAN 损失的基础上引入了梅尔谱图损失,以提高生成器的训练效率和生成语音的质量。
具体来说,它的定义是发生器合成的波形与真实波形的熔谱图之间的 L1 距离。
这种损耗使发生器能够合成与输入条件相对应的自然波形,并从对抗学习的早期阶段开始稳定学习。
特征匹配损失
指真实样本和生成样本中鉴别器特征的相似度。
具体来说,提取判别器的中间特征,并计算每个特征空间中真实样本和条件生成样本之间的 L1 距离。
最终损失函数
最终的 HiFi-GAN 损失函数。
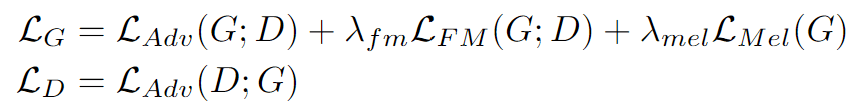
在这里,发生器的损失函数表示为上述三个损失函数的加权和。
效果
实验细节
为评估 HiFi-GAN 的语音合成质量和合成速度,我们进行了以下四项实验
- 主观评估以及与其他先进模型(WaveNet、WaveGlow、MelGAN)的速度比较
- 调查 HiFi-GAN 的每个组成部分(MPD、MRF、mel spectrogram loss)对质量的影响。
- 研究语音合成中的泛化性能
- 端到端语音合成实验
主观评价以及与其他现代模型的速度比较
我们从 LJSpeech 中随机抽取了 50 个语句来测量主观评价(平均意见分值,MOS)和合成速度。
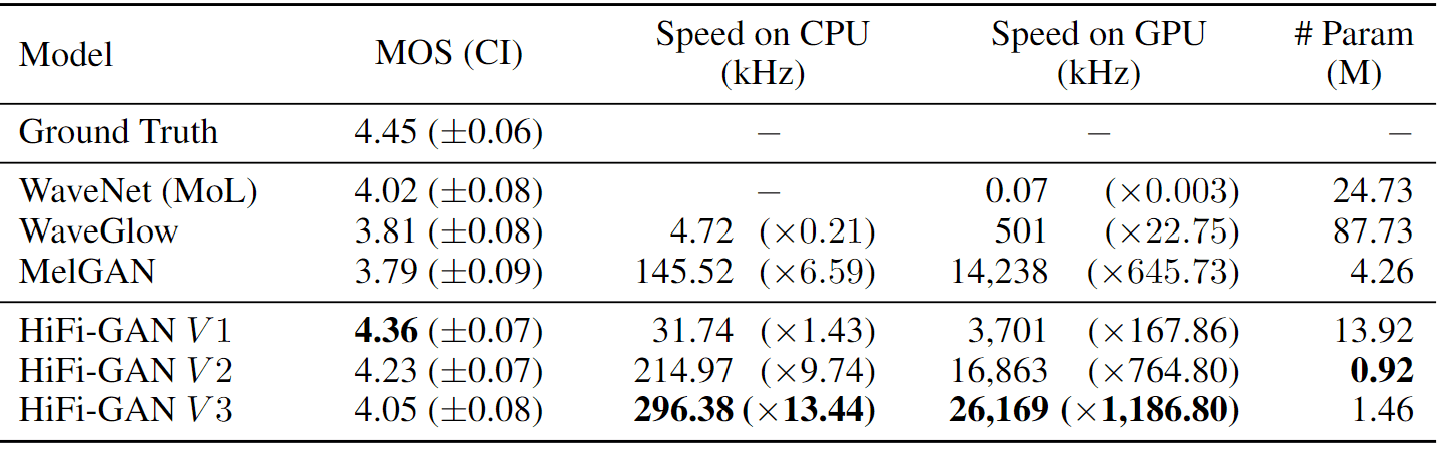
结果表明,与 WaveNet、WaveGlow 和 MelGAN 等其他模型相比,HiFi-GAN 实现了更高的 MOS。至于 HiFiGAN 的 V3,其速度也比 CPU 上的实时合成快 13.44 倍。
-研究 HiFi-GAN 对单个组件质量的影响
为了研究每个分量(MPD、MRF、MelSpectrogram loss)对 HiFiGAN 中语音质量的影响,他们根据 V3 删除了每个分量,并比较了 MOS。他们还研究了在 MelGAN 中引入 MPD 的效果。
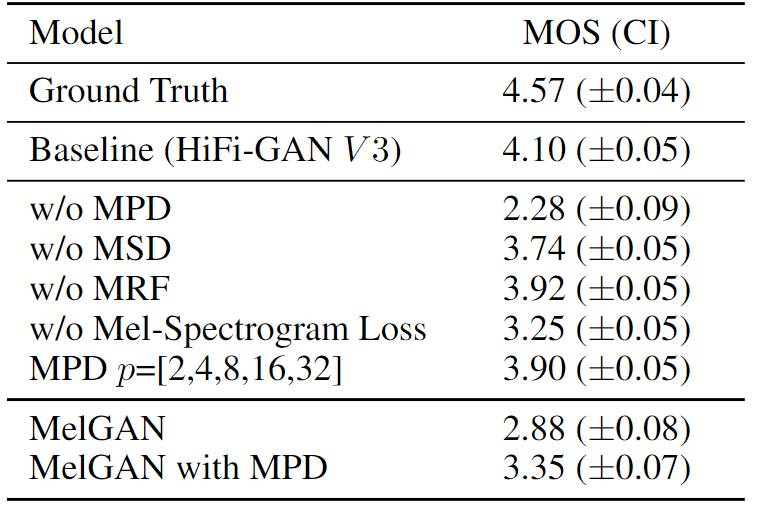
结果表明,MPD、MRF 和 mel spectrogram loss 都有助于提高性能。特别是当 MPD 被移除时,质量大大降低。
此外,当将 MPD 引入 MelGAN 模型时,也观察到了显著的改进。
研究语音合成中的泛化性能
数据集中剔除了九位发言者的语音数据,并通过对发言者的语音进行梅尔频谱图转换→使用 HiFiGAN 进行语音合成来测量 MOS。
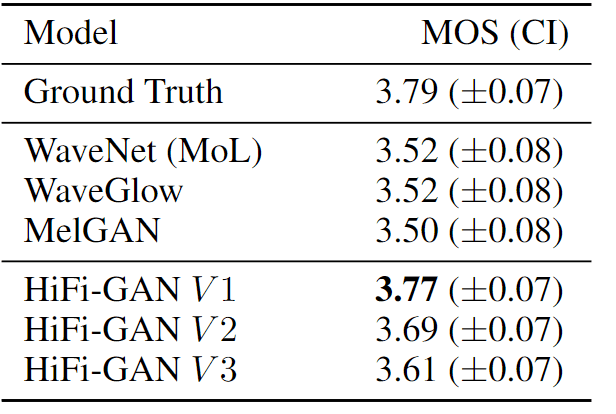
结果表明,在所有三个变体中,HiFi-GAN 的性能均优于自回归模型和基于流量的模型。
结果表明,语音合成的泛化能力很强。
端到端语音合成实验
HiFi-GAN 与文本到谱模型 "Tacotron2 "相结合,用于评估端到端语音合成的性能。
具体来说,将 Tacotron2 生成的熔谱图输入 HiFi-GAN,并对 MOS 进行测量。此外,还验证了微调的效果。
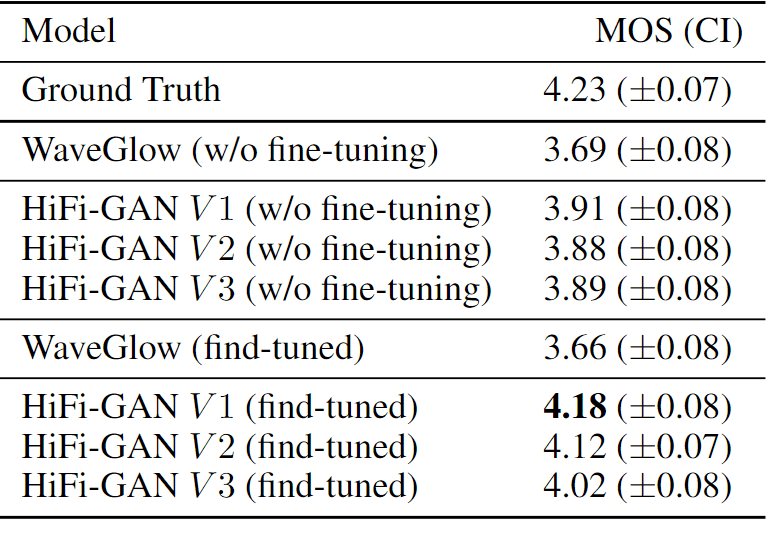
结果表明,结合Tacotron2 和HiFi-GAN 的语音合成模型优于 WaveGlow。微调结果还显示,V1 的 MOS 达到了 4.18,几乎与人声质量相当。
总结
本文介绍了有关 HiFiGAN 的研究,这是一种用于高效、高质量语音合成的 GAN 模型。
本研究有三个局限性
- 是否适用于更多的说话者和语言还不得而知。
- 嗓音的情感和节奏表现力尚未得到充分测试。
- 尚未对有限计算资源环境下的语音合成性能进行评估。
因此,在未来的研究中,他们计划开发一个 HiFi-GAN 的扩展模型来解决上述问题,并通过在小数据集上学习来缩小规模和提高效率。