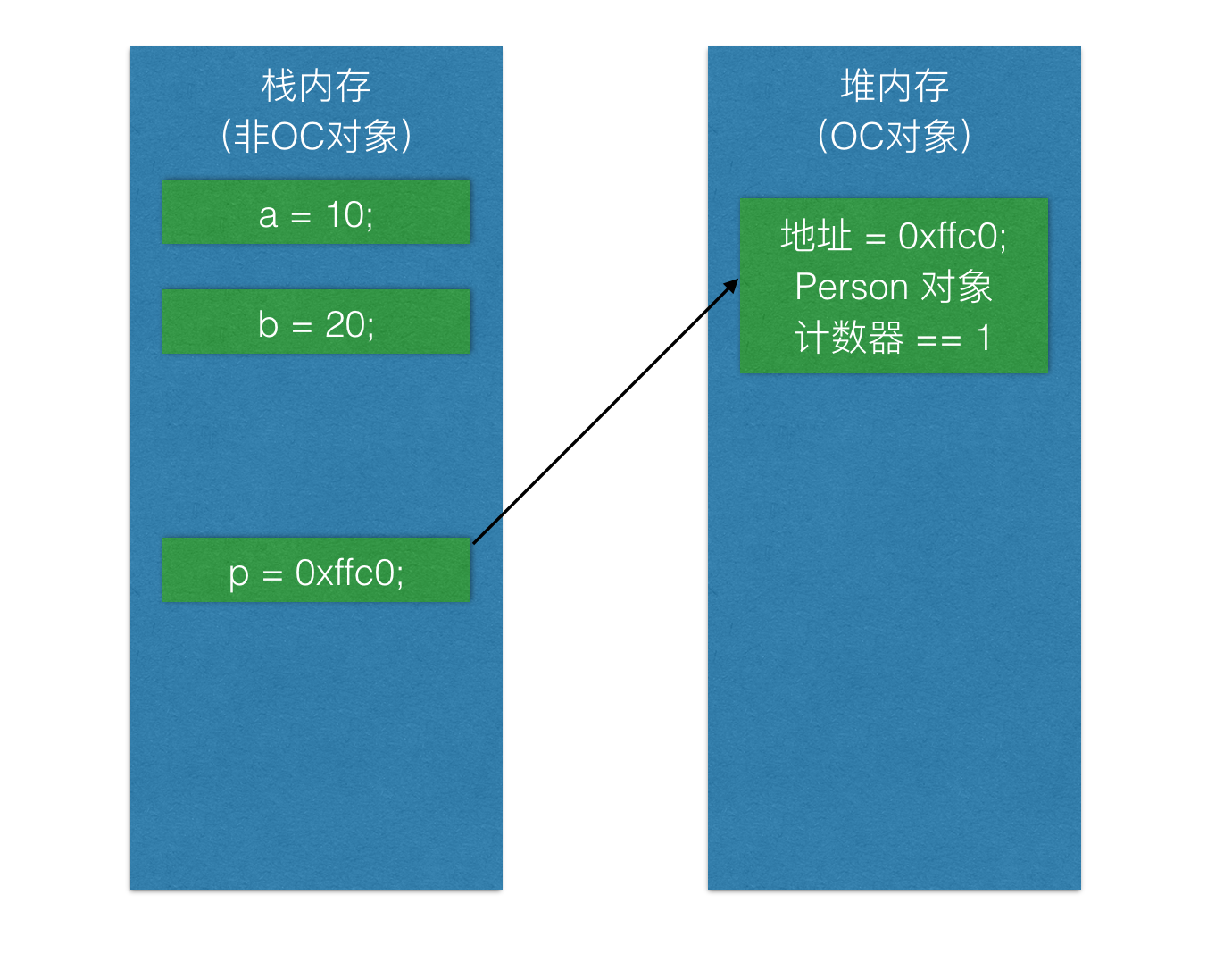
损失
回归问题
L1损失
L1 损失是最小化模型参数的绝对值之和。
倾向于使模型参数接近零,导致模型变得更加稀疏。这意味着一些特征的权重可能变为零,从而被模型忽略。
对异常值非常敏感。异常值会导致参数权重绝对值增大,从而影响模型的整体结构。
求解 L1 损失的问题通常比求解 L2 损失的问题更难。L1 损失的优化问题是一个非凸问题,而 L2 损失的优化问题是一个凸问题。这使得 L1 损失的优化算法(如坐标下降法)可能需要更多的迭代来收敛。
当模型的稀疏性非常重要时,例如在文本分析或生物信息学中,L1 损失是一个很好的选择。
L2损失
L2 损失是最小化模型参数的平方和。
倾向于使模型参数的值变小,但不会导致参数变为零。这有助于防止模型过拟合,同时保持参数的非零值。
对异常值的影响较小。虽然异常值会导致参数权重增大,但其平方值会变大,从而在总和中的贡献相对较小。
由于其凸性,L2 损失的优化问题(如最小二乘法)通常更容易解决,并且有多种有效的算法(如梯度下降、牛顿法等)。
当模型的参数需要保留非零值,并且对异常值不太敏感时,L2 损失是一个更常用的选择。
分类问题
交叉熵损失
指标
混淆矩阵

精确度(precision)/查准率:TP/(TP+FP)=TP/P 预测为真中,实际为正样本的概率
召回率(recall)/查全率:TP/(TP+FN) 正样本中,被识别为真的概率
假阳率(False positive rate):FPR = FP/(FP+TN) 负样本中,被识别为真的概率
真阳率(True positive rate):TPR = TP/(TP+FN) 正样本中,能被识别为真的概率
准确率(accuracy):ACC =(TP+TN)/(P+N) 所有样本中,能被正确识别的概率
AUC
ROC曲线面积,纵坐标TPR,横坐标FPR
GAUC
带权重的auc




















![[算法] 优先算法(六):二分查找算法(下)](https://i-blog.csdnimg.cn/direct/f0c5b1e3dbe044769fc9fc5c38accbae.jpeg#pic_center)