爬虫(Web Crawler 或 Web Spider)是一种自动化脚本或程序,用于浏览万维网(World Wide Web)并抓取网页上的信息。它们按照设定的规则自动地访问互联网上的网页,提取所需的数据,如文本、图片、视频等,并将这些数据保存到本地数据库或文件中,供后续分析、处理或利用。
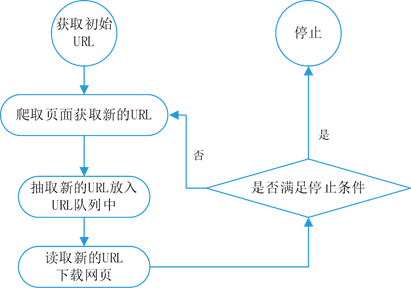
爬虫的工作原理通常包括以下几个步骤:
发送请求:爬虫首先向目标网站发送HTTP请求,模拟浏览器向服务器请求数据。
获取响应:服务器接收到请求后,会返回相应的HTML文档或其他类型的文件(如JSON、XML等),爬虫接收到这些数据。
解析内容:爬虫使用解析器(如正则表达式、XPath、CSS选择器或专门的HTML解析库)解析返回的HTML文档,提取出需要的数据。
存储数据:将提取的数据保存到本地文件、数据库或其他类型的存储系统中,以便后续使用。
循环与调度:根据一定的策略(如深度优先、广度优先等)或用户定义的规则,爬虫会继续访问其他链接,重复上述过程,直到满足停止条件(如达到预设的网页数量、遍历完所有链接等)。
爬虫的应用非常广泛,包括但不限于:
- 搜索引擎:搜索引擎利用爬虫技术抓取互联网上的信息,建立索引数据库,供用户搜索。
- 数据收集:企业、研究机构等利用爬虫收集市场数据、用户反馈、竞争对手信息等。
- 内容聚合:新闻聚合网站、RSS阅读器等通过爬虫抓取多个来源的内容,为用户提供一站式阅读体验。
- 学术研究:在数据挖掘、自然语言处理等领域,爬虫是获取研究数据的重要工具。
然而,需要注意的是,爬虫的使用必须遵守目标网站的robots.txt协议和相关法律法规,不得对网站服务器造成过大负担,也不得侵犯用户的隐私和权益。





































![[线上问题排查]JVM OOM问题如何排查和解决](https://i-blog.csdnimg.cn/direct/f216b5ddf528492fbe292e6855e3b327.gif)






