多维动态规划是动态规划的一个扩展,它处理的问题通常具有多个维度的状态空间。在标准的一维动态规划中,状态通常依赖于一个变量,比如时间步或者位置。然而,在多维动态规划中,状态可能依赖于两个或更多的变量,这增加了问题的复杂性和求解难度。
在多维动态规划中,关键步骤包括:
1. **状态定义**:
- 定义状态空间,也就是决定你的问题中的哪些变量是重要的。
- 每个状态通常表示为一个元组,例如 `(i, j, k)`,其中 `i`, `j`, `k` 是影响问题解决方案的不同维度的值。2. **状态转移方程**:
- 确定如何从一个状态转移到另一个状态。
- 这通常涉及到一个递推关系,比如 `dp[i][j][k] = min(dp[i-1][j][k], dp[i][j-1][k], dp[i][j][k-1]) + cost(i, j, k)`。3. **初始化**:
- 确定边界条件,即状态空间的起点。
- 这些通常是已知的或者可以通过简单计算得到的初始状态。4. **计算顺序**:
- 决定状态的计算顺序,通常是从低维状态向高维状态计算。
- 这是为了确保在计算一个状态之前,所有依赖它的状态都已经计算完成。5. **记忆化或表格法**:
- 使用一个多维数组来存储已经计算过的结果,避免重复计算。
- 这是动态规划的关键,可以大大减少计算量。6. **最终答案**:
- 最终答案通常是状态空间中某个特定状态的值。多维动态规划常用于各种复杂问题,如库存管理、投资组合优化、路径寻找问题等。例如,在解决三维背包问题时,状态可能包含物品的数量、重量和体积三个维度。
理解多维动态规划的关键在于能够清晰地定义状态空间和状态转移规则。一旦这些被正确建立,问题就可以通过迭代填充多维数组的方式得到解决。由于状态空间的增加,多维动态规划问题可能会遇到“维数灾难”,即状态数量随维度指数级增长,因此选择合适的数据结构和算法优化变得尤为重要。
62. 不同路径
一个机器人位于一个
m x n网格的左上角 (起始点在下图中标记为 “Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
我觉得做题目,要么从前往后推理,要么从后往前推理论。
你看这个题目,试想一下,我们达达某一个位置,那么到当前位置直接关联的上一步是什么呢?
要么从上面过来的,要么从左面过来的:
所以就有:
dp[i][j]: 到第i行第j列的路径总数;
dp[i][j] = dp[i-1][j] + dp[i][j-1];
边界条件:
就是两边dp[i][0] = 1, dp[0][i] = 1
class Solution: def uniquePaths(self, m: int, n: int) -> int: sum = 0 dp = [[0]*n for _ in range(m)] #dp[0][0] = 1 for row in range(m): for col in range(n): if row==0 and col==0: dp[row][col] = 1 continue if row==0: dp[row][col] = dp[row][col-1] continue if col == 0: dp[row][col] = dp[row-1][col] continue dp[row][col] += dp[row-1][col]+dp[row][col-1] return dp[m-1][n-1]

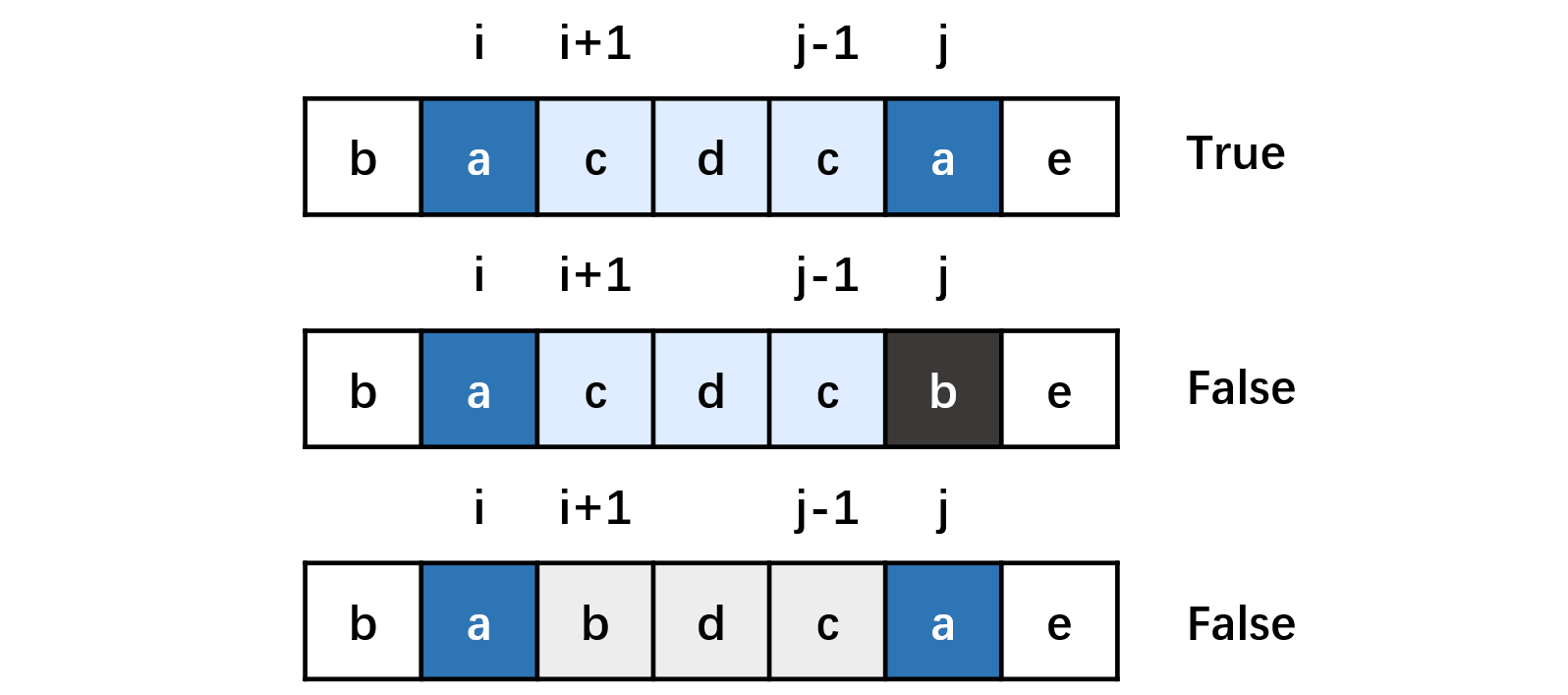
5. 最长回文子串
给你一个字符串 s,找到 s 中最长的 回文子串。

思考:
怎么才能算回文:s = s[::-1]
长度大于2的,用 P(i,j) 表示字符串 s 的第 i 到 j 个字母组成的串(下文表示成 s[i:j])是否为回文串:
这里的「其它情况」包含两种可能性:
s[i,j] 本身不是一个回文串;
i>j,此时 s[i,j] 本身不合法。
那么我们就可以写出动态规划的状态转移方程:
P(i,j)=P(i+1,j−1)∧(Si==Sj)
特别的长度等于2的:
注意:在状态转移方程中,我们是从长度较短的字符串向长度较长的字符串进行转移的,因此一定要注意动态规划的循环顺序。
class Solution: def longestPalindrome(self, s: str) -> str: length = len(s) if length<=0: return s dp = [[False] * length for _ in range(length)] for i in range(length): dp[i][i] = True max_len = 1 result = s[0] # 序列可能长度的遍历 for L in range(2, length+1): for i in range(length): j = i+L-1 # 出界了 if j>=length: break if s[i]!=s[j]: dp[i][j] = False else: # 长度小于3的 if L<=3: dp[i][j]=True else: dp[i][j] = dp[i+1][j-1] if dp[i][j] and max_len< L: max_len = L result = s[i:j+1] return result


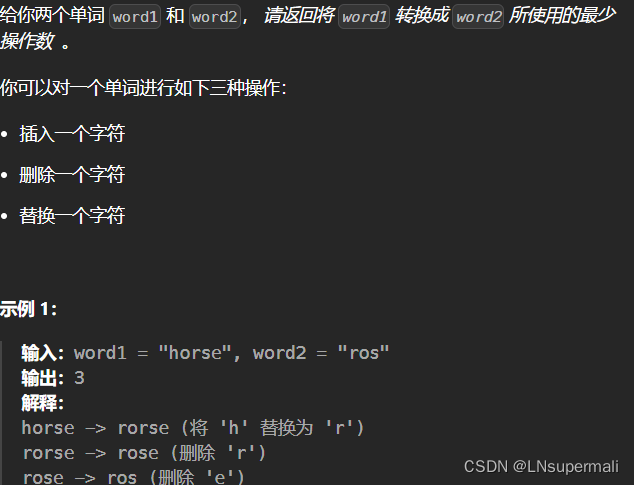
1143. 最长公共子序列
给定两个字符串
text1和text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回0。一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
- 例如,
"ace"是"abcde"的子序列,但"aec"不是"abcde"的子序列。两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
示例 1:
输入:text1 = "abcde", text2 = "ace" 输出:3 解释:最长公共子序列是 "ace" ,它的长度为 3 。示例 2:
输入:text1 = "abc", text2 = "abc" 输出:3 解释:最长公共子序列是 "abc" ,它的长度为 3 。比如对于本题而言,可以定义 dp[i][j] 表示 text1[0:i-1] 和 text2[0:j-1] 的最长公共子序列。 (注:text1[0:i-1] 表示的是 text1 的 第 0 个元素到第 i - 1 个元素,两端都包含)
之所以 dp[i][j] 的定义不是 text1[0:i] 和 text2[0:j] ,是为了方便当 i = 0 或者 j = 0 的时候,dp[i][j]表示的为空字符串和另外一个字符串的匹配,这样 dp[i][j] 可以初始化为 0.
- 当 text1[i - 1] == text2[j - 1] 时,说明两个子字符串的最后一位相等,所以最长公共子序列又增加了 1,所以 dp[i][j] = dp[i - 1][j - 1] + 1;举个例子,比如对于 ac 和 bc 而言,他们的最长公共子序列的长度等于 a 和 b 的最长公共子序列长度 0 + 1 = 1。
- 当 text1[i - 1] != text2[j - 1] 时,说明两个子字符串的最后一位不相等,那么此时的状态 dp[i][j] 应该是 dp[i - 1][j] 和 dp[i][j - 1] 的最大值。举个例子,比如对于 ace 和 bc 而言,他们的最长公共子序列的长度等于 ① ace 和 b 的最长公共子序列长度0 与 ② ac 和 bc 的最长公共子序列长度1 的最大值,即 1。
总结:
如果当前连个对比的字符串相等:i,j, 肯定是之前的字序列最大长度 + 1
s1[i] == s2[j] : dp[i][j] = dp[i-1][j-1] + 1
如果不相同,也取之前子问题序列最大值:
dp[i][j] = max(dp[i][j-1],dp[i-1][j])
class Solution: def longestCommonSubsequence(self, text1: str, text2: str) -> int: leg1 = len(text1) leg2 = len(text2) # dp[i][j]: 序列s1[:i+1], s2[:j+1],最长公共子序列 max_len = 0 dp = [[0]*(leg2+1) for _ in range(leg1+1)] for i in range(1,leg1+1): for j in range(1,leg2+1): if text1[i-1]!=text2[j-1]: dp[i][j] = max(dp[i-1][j], dp[i][j-1]) else: dp[i][j] = dp[i-1][j-1] + 1 return dp[leg1][leg2]































![[Linux] yum和vim](https://i-blog.csdnimg.cn/direct/b5bf20571908412ab4c592e5876164fc.png)

