目录
决策树回归(Decision Tree Regression)
随机森林回归(Random Forest Regression)
引言
决策树回归(Decision Tree Regression)
定义与原理:
- 决策树回归是一种非参数监督学习方法,它使用树形结构来对目标变量进行预测。与线性回归模型不同,决策树回归不需要预先假设数据的分布形式,因此能够很好地处理非线性和高维数据。
- 决策树回归通过递归地将数据集划分为更小的子集,并在每个子集上构建简单的预测模型。树中的每个节点表示一个特征,节点的分裂则是根据该特征的某个阈值将数据集分成两部分。树的叶子节点包含目标变量的预测值。
构建过程:
- 选择最优分裂点:选择一个特征及其相应的分裂点,使得数据集在该特征上的分裂能最大程度地减少目标变量的方差(或均方误差)。
- 递归分裂:在每个分裂的子集上重复上述过程,直到满足停止条件(如达到最大深度或叶节点样本数量小于某个阈值)。
- 生成叶子节点:停止分裂后,叶子节点的值设为该子集上目标变量的均值。
优缺点:
- 优点:
- 简单易理解,可视化效果好。
- 对数据预处理要求较低(无需归一化或标准化)。
- 能处理多种数据类型(数值型、分类型)。
- 适用于处理非线性关系。
- 缺点:
- 容易过拟合,特别是树的深度较大时。
- 对小数据集敏感,容易产生较大波动。
- 在某些情况下,结果不稳定(对噪声数据敏感)。
应用场景:
决策树回归在金融、医疗、零售等领域都有广泛的应用,如预测股票价格、货币汇率、疾病风险、药物反应、销量预测等。
线性回归(Linear Regression)
定义:
- 线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w'x + e,其中e为误差项,服从均值为0的正态分布。
类型:
- 如果回归分析中只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
- 如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
方法:
- 线性回归模型经常用最小二乘逼近来拟合,即找到一条直线,使得所有观测点到这条直线的垂直距离的平方和最小。
优缺点:
- 优点:
- 模型简单,易于理解和解释。
- 计算简便,适合大规模数据处理。
- 适用于线性关系明显的数据。
- 缺点:
- 无法处理非线性关系。
- 对异常值较为敏感。
- 需要预先假设数据的线性关系。
应用场景:
线性回归在金融、经济学、流行病学等领域有广泛应用,如预测消费支出、固定投资支出、股票价格趋势等。
随机森林回归(Random Forest Regression)
定义与原理:
- 随机森林回归是一种集成学习方法,通过构建多个决策树并将它们的预测结果进行平均,来提高模型的稳定性和预测准确性。它通过引入随机性来增强模型的泛化能力,有效减轻了单棵决策树容易过拟合的问题。
构建过程:
- 随机采样:从原始训练数据集中有放回地随机抽样,生成多个子数据集(Bootstrap样本)。
- 决策树构建:对每个子数据集构建一棵决策树。在每个节点分裂时,随机选择特征的一个子集,并在其中选择最佳特征进行分裂。
- 集成预测:对于新的输入数据,通过所有决策树进行预测,然后对结果进行平均(对于回归问题)或投票(对于分类问题)。
优缺点:
- 优点:
- 高精度:通过集成多个决策树,通常能取得比单棵决策树更高的预测精度。
- 抗过拟合:由于多个决策树的结果是平均的,可以有效减轻过拟合现象。
- 鲁棒性:对数据中的噪声和缺失值具有较强的鲁棒性。
- 处理高维数据:能够处理大量特征,并能评估特征的重要性。
- 缺点:
- 计算开销大:构建多个决策树的计算开销较大。
- 模型解释性差:由于结果是多个决策树的平均,难以解释具体的决策路径。
应用场景:
随机森林回归在金融、医疗、生物信息学等领域有广泛应用,如预测股票价格、疾病风险、基因表达等。
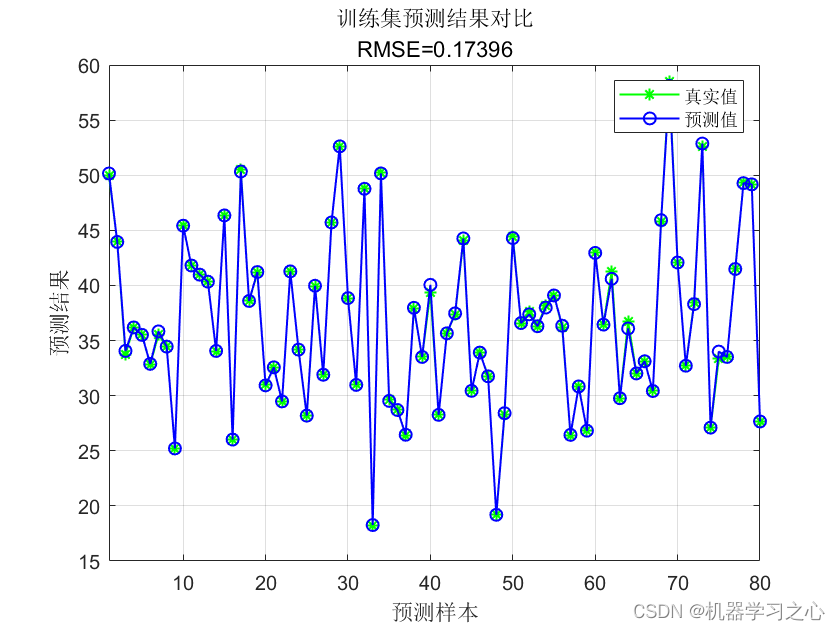
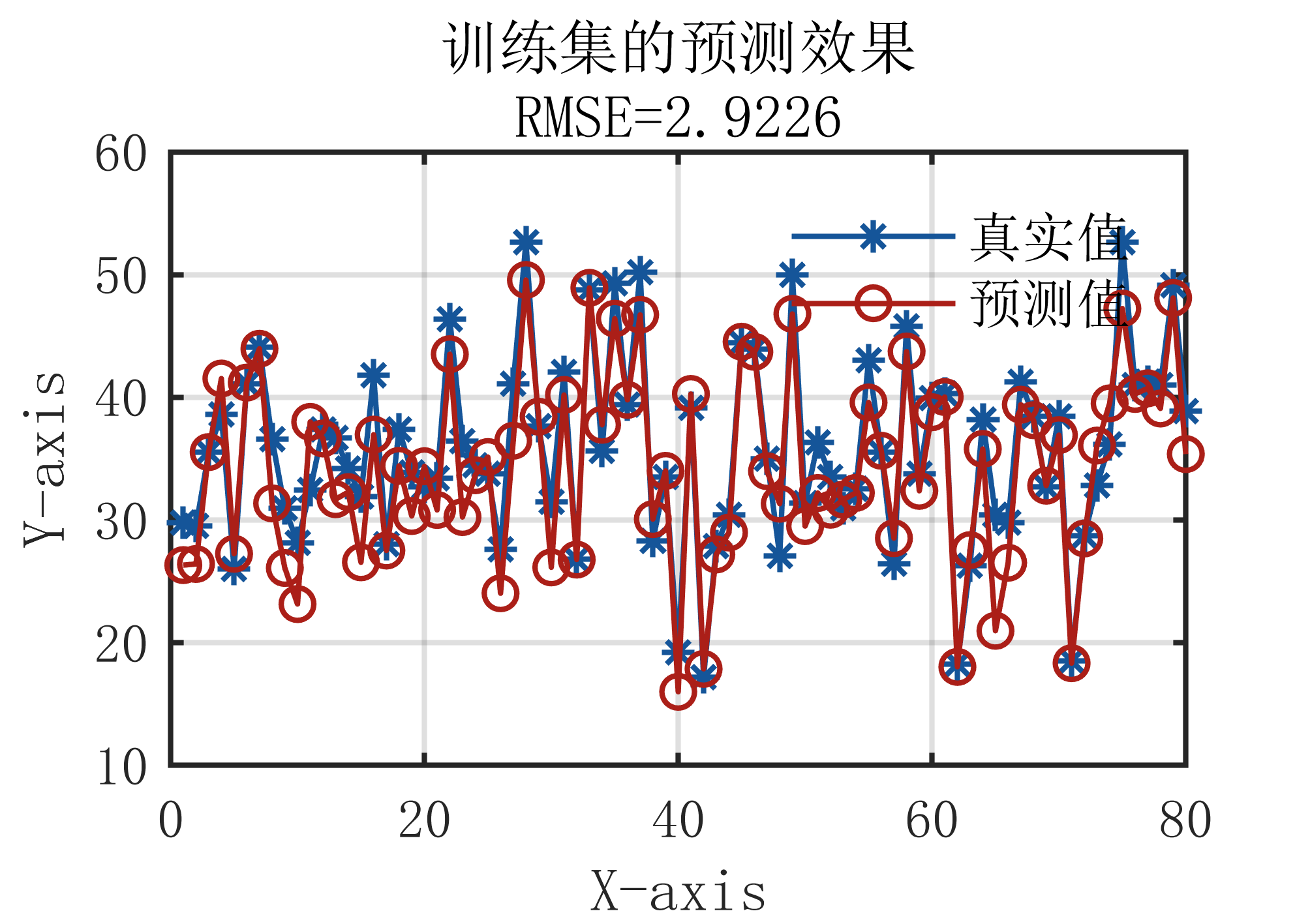
气温预测对比实例
数据集

预测值与实际值对比图

模型评价指标
- MSE(均方误差):衡量模型预测值与真实值之间差异的平方的平均值。MSE越小,表示模型预测越准确。
- MAE(平均绝对误差):衡量模型预测值与真实值之间差异的平均值的绝对值。MAE同样越小越好。
- R²分数(R² score):表示模型对数据的拟合程度。R²分数的值范围从负无穷大到1,其中1表示完美预测,0表示模型的表现与简单预测(如平均值)相同,而负值则表示模型表现比简单预测还差。

代码实现
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import numpy as np
# 加载数据集
data = pd.read_csv("气温.csv")
# 数据预处理
data['date'] = pd.to_datetime(data[['year', 'month', 'day']])
# 根据日期划分数据集
train_mask = (data['date'] >= '2020-01-01') & (data['date'] <= '2022-11-30')
val_mask = (data['date'] >= '2022-12-01') & (data['date'] <= '2022-12-31')
test_mask = (data['date'] >= '2023-01-01') & (data['date'] <= '2023-12-31')
train_data = data[train_mask] # 训练集
val_data = data[val_mask] # 验证集
test_data = data[test_mask] # 测试集
# 特征工程:将年份、月份、日期作为特征,实际气温为目标变量
X_train = train_data[['year', 'month', 'day']]
y_train = train_data['average']
X_val = val_data[['year', 'month', 'day']]
y_val = val_data['average']
X_test = test_data[['year', 'month', 'day']]
y_test = test_data['average']
#决策树回归
dtr = DecisionTreeRegressor(random_state=42)
dtr.fit(X_train, y_train)
y_pred_dtr = dtr.predict(X_test)
# 线性回归
lr = LinearRegression()
lr.fit(X_train, y_train)
y_pred_lr = lr.predict(X_test)
# 随机森林回归
rfr = RandomForestRegressor(n_estimators=100, random_state=42)
rfr.fit(X_train, y_train)
y_pred_rfr = rfr.predict(X_test)
# 为可视化创建一个画布和三个子图
fig, axs = plt.subplots(3, 1, figsize=(10, 15))
# 决策树回归的预测结果与实际值对比
axs[0].scatter(y_test, y_pred_dtr, color='blue', alpha=0.5)
axs[0].set_title('Decision Tree Regression Predictions vs Actual')
axs[0].set_xlabel('Actual Values')
axs[0].set_ylabel('Predicted Values')
axs[0].plot([np.min((y_test.min(), y_pred_dtr.min())), np.max((y_test.max(), y_pred_dtr.max()))],
[np.min((y_test.min(), y_pred_dtr.min())), np.max((y_test.max(), y_pred_dtr.max()))], 'r--')
# 线性回归的预测结果与实际值对比
axs[1].scatter(y_test, y_pred_lr, color='green', alpha=0.5)
axs[1].set_title('Linear Regression Predictions vs Actual')
axs[1].set_xlabel('Actual Values')
axs[1].set_ylabel('Predicted Values')
axs[1].plot([np.min((y_test.min(), y_pred_lr.min())), np.max((y_test.max(), y_pred_lr.max()))],
[np.min((y_test.min(), y_pred_lr.min())), np.max((y_test.max(), y_pred_lr.max()))], 'r--')
# 随机森林回归的预测结果与实际值对比
axs[2].scatter(y_test, y_pred_rfr, color='red', alpha=0.5)
axs[2].set_title('Random Forest Regression Predictions vs Actual')
axs[2].set_xlabel('Actual Values')
axs[2].set_ylabel('Predicted Values')
axs[2].plot([np.min((y_test.min(), y_pred_rfr.min())), np.max((y_test.max(), y_pred_rfr.max()))],
[np.min((y_test.min(), y_pred_rfr.min())), np.max((y_test.max(), y_pred_rfr.max()))], 'r--')
# 显示整个画布上的图形
plt.tight_layout()
plt.show()