前言
本文的目的是关注大语言模型 (LLM)所面临的挑战以及便利性和隐私性之间的权衡,以帮助您决定哪种途径最适合您。
在处理传统软件时,隐私问题通常围绕数据存储、传输和访问控制。我们实施加密、设置安全数据库并谨慎管理用户权限。然而,当您想要获得最佳结果而又无法在本地自行完成时,LLM 的世界会为隐私考虑带来新的复杂性。
顺便说一句,我们说的不是 ChatGPT。ChatGPT 是一个功能强大的界面,而不仅仅是 LLM。它不用于构建产品或工具。这里,我们谈论的是通过 API 用来构建用户想要的强大产品和聊天机器人的 LLM。
让我们来看看可以考虑的五个选项:
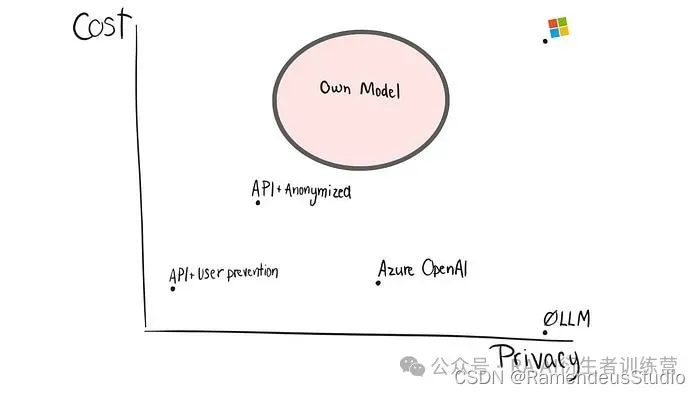
- 最佳 LLM 的私有端点(例如 Azure OpenAI 服务)
- 使用简单的用户预防 API
- 使用包含匿名数据的 API
- 拥有自己的模型
- 重新考虑 + 替代方案
- 奖金…
以下是我们将要讨论的内容的简要介绍……
API(第三方 LLM 服务)
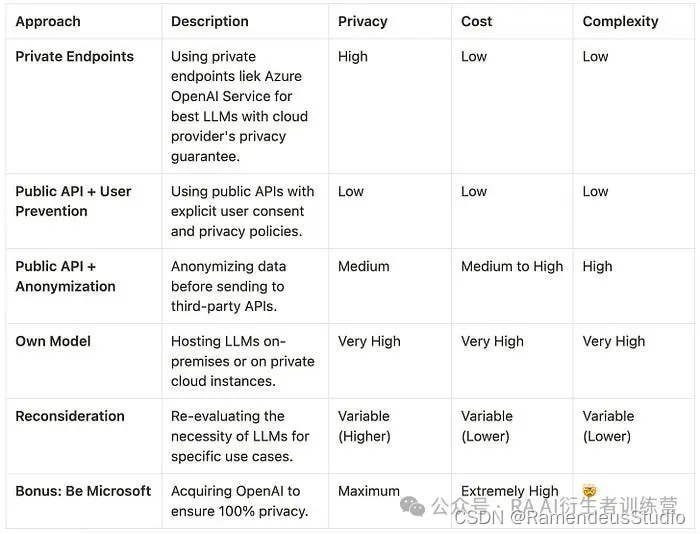
1 - 使用私有端点获取最佳大语言模型
对于那些想要使用最好的 LLM 但又想要主要云提供商的隐私保证和功能的人来说,这是理想的选择。例如,微软通过Azure OpenAI 服务为 OpenAI 模型提供专用的私有端点,专为企业客户和合作伙伴量身定制。
如果您的组织已经使用 Azure,那么这是一个不错的选择。您可以设置 Azure 虚拟网络 (VNet),以使您的数据与公共 Internet 隔离。如果您需要满足数据隐私的监管和合规性要求,此设置是理想的选择。
每个输入/输出令牌的费用与OpenAI 的标准费率相同。要使用此服务,您需要提交表格并等待批准。请注意,一些用户报告说需要等待几周才能获得批准。
2 — 第一种情况:公共 API + 用户预防
通过第三方 API(如 OpenAI 的 GPT 模型或 Anthrpic 的 Claude)使用 LLM 既方便又划算。这些服务无需大量基础设施或专业知识即可提供最先进的性能 。然而,这种便利性可能会带来隐私成本。
主要担心的是,这些公司可能会使用发送到其 API 的数据来进一步训练和改进他们的模型。或者,存在数据泄露的问题。数据泄露的方式有很多种,而大型科技公司是这些安全风险的首选目标。以下是2023 年 3 月OpenAI 中断的一个例子:由于库中的错误,用户可以看到其他活跃用户的聊天标题。虽然大多数提供商都有针对这种情况的政策,但这种可能性仍然存在,这是注重隐私的组织需要仔细考虑的风险。
例如,如果您使用第三方 LLM 来处理客户支持查询,那么您实际上是在与 API 提供商共享客户的顾虑和潜在的敏感信息。同样,提供商可以将这些数据用于各种目的。
考虑到所涉及的复杂性和权衡,许多组织可以选择一种务实的方法:明确告知用户使用 LLM 功能对隐私的影响。这也是因为它是最简单的“隐私预防”形式。
这可能涉及:
- 使用 LLM 功能之前的明确同意机制。
- 明确的隐私政策,解释如何处理数据以及存在哪些风险。
- 为不愿意让 LLM 提供商处理其数据的用户提供替代方案。
显然,这是最经济实惠、最简单的选择,但可能不是用户的首选方式。如果您拥有法律规定不能与其他公司共享的数据,那么这可能也不是一个可行的选择。
3 — 第二种情况:公共 API + 匿名化
使用第三方 API 时,降低隐私风险的一种方法是在将数据发送到 LLM 之前对其进行匿名化和去身份化。这涉及从文本中删除或隐藏任何个人身份信息 (PII)。例如,您可以删除任何与用户相关的个人信息、修改信息(输入通用电话号码)或将数据更改为更通用的年龄(而不是 29 岁,输入 25 到 30 岁之间的范围)。
然而,匿名化绝非易事。这是一个耗时的过程,需要仔细考虑在特定情况下什么构成 PII。此外,LLM 通常在特定情况下表现更好,因此激进的匿名化可能会影响您收到的结果的质量。
考虑这个简单的例子:# 匿名化之前
original_text = “来自纽约的 John Doe 打来电话询问他的帐户 #12345。”
# 匿名化之后
anonymized_text = “来自 [CITY] 的 "[NAME] 打来电话询问他们的帐户 #[REDACTED]。”
现在,想象一下,文本、数据、图像、扫描和其他格式中有大量需要匿名化的变体。我们过去的一位客户必须使用开源 OCR(光学字符识别)+ LLM 组合算法来检查数千张账单照片,以发现数据并将其匿名化和模糊化,当然,这一切都必须手动进行。
虽然这种匿名化保护了个人隐私,但它也删除了可能对 LLM 提供准确和有用的答复至关重要的背景信息。此外,几乎不可能毫无差错地完成这一过程。
4 — 拥有自己的模型:最大程度的隐私,最大程度的努力
对于隐私要求严格的组织,在本地或私有云实例(如 AWS 或 GCP)上托管 LLM 可提供最高的数据控制和安全级别。这种方法可确保所有数据处理都在您的受控环境中进行,但有一个重要的警告:它的设置和管理也是最复杂的。
如果您决定走这条路,请务必考虑以下关键点:
- 资源强度(计算): LLM 需要大量的计算资源,包括训练和推理,因为您的实例需要 GPU。
- 性能限制:您的模型将仅限于最佳开源方法(可能根据您的数据进行微调)或您可以内部执行的操作。此解决方案胜过当前 SOTA LLM + RAG 的可能性很小。
- 数据:准备所选模型进行训练(或微调)将需要大量数据和预处理时间。
- 所需专业知识:大多数公司都负担得起计算费用,以微调最新的开源 LLM,例如 Llama-3 70b。但通过微调获得良好结果很难。它需要专业知识和大量时间进行实验。您可能需要一名数据科学家来准备数据集,一名 ML 工程师来训练模型,以及一名 DevOps 工程师来管理云服务上的部署。
- 成本:基础设施和持续维护成本昂贵,特别是对于较小的组织而言。
- 数据匿名化:您将有与第 3 部分(公共 API + 匿名化)相同的关注点和预处理工作。
5 — 你真的需要大语言模型吗?
在与多家企业合作后,我们发现很多案例都提出 LLM 可以用于实际上并不需要 AI 的任务。
考虑:
- 这个任务是否真的复杂到需要获得大语言模型?
- 更简单、更保护隐私的解决方案就足够了吗?
- 是否存在现有的非人工智能工具可以有效地处理这项任务?
- 你能承担LLM带来的幻觉风险吗?
- 这个功能对于你的产品的改进是否至关重要?
在进入 LLM 之前,请先分析您的具体用例。有时,传统算法、基于规则的系统,甚至精心设计的数据库都可以提供有效的解决方案,而无需担心与 LLM 相关的隐私问题。
(奖励)6 — 成为微软
如果您负担得起,这是迄今为止最简单的方法。在这里,您可以直接购买 Open AI。它很简单,而且 100% 私密。
结论
在本文中,我们探讨了与大型语言模型 (LLM) 相关的多方面隐私问题以及应对这些挑战的各种策略,希望这对决定选择哪条路径有所帮助。从使用主要云提供商的私有端点并在将数据发送到第三方 API 之前对其进行匿名化,到从头开始构建自己的系统,每种选择都提供不同级别的隐私、成本和便利性。托管自己的模型可以提供最大程度的数据控制,但需要大量资源和专业知识。这绝对不是初创公司的选择。
在实施 LLM 之前,请确保正确评估其是否真正适合您的特定用例。传统解决方案可能更有效且更保护隐私。
欢迎你分享你的作品到我们的平台上:www.shxcj.com 或者 www.2img.ai 让更多的人看到你的才华。
创作不易,觉得不错的话,点个赞吧!!!