个人理解,爬虫有两种方式,一种是自动测试化,一种是通过找请求,那么这里就用发请求的方式爬取网页信息,仅供技术参考。
网页信息:

python代码:
# -*- coding: utf-8 -*-
import requests as rq
from bs4 import BeautifulSoup
#伪装请求头
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67"
}
#这只是一页:需要循环获取
for i in range(0,250,25):
#携带设置的请求头 格式化每次访问的链接
context=rq.get(f"https://movie.douban.com/top250?start={i}&filter=", headers=headers).text
#拿到当前页的信息
soup=BeautifulSoup(context,"html.parser")
#获取所有class叫title且标签是span的
title_All=soup.findAll("span",attrs={"class","title"})
#循环输出
for ti in title_All:
#把英文版本的去掉
if "/" not in ti.string:
print(ti.string)
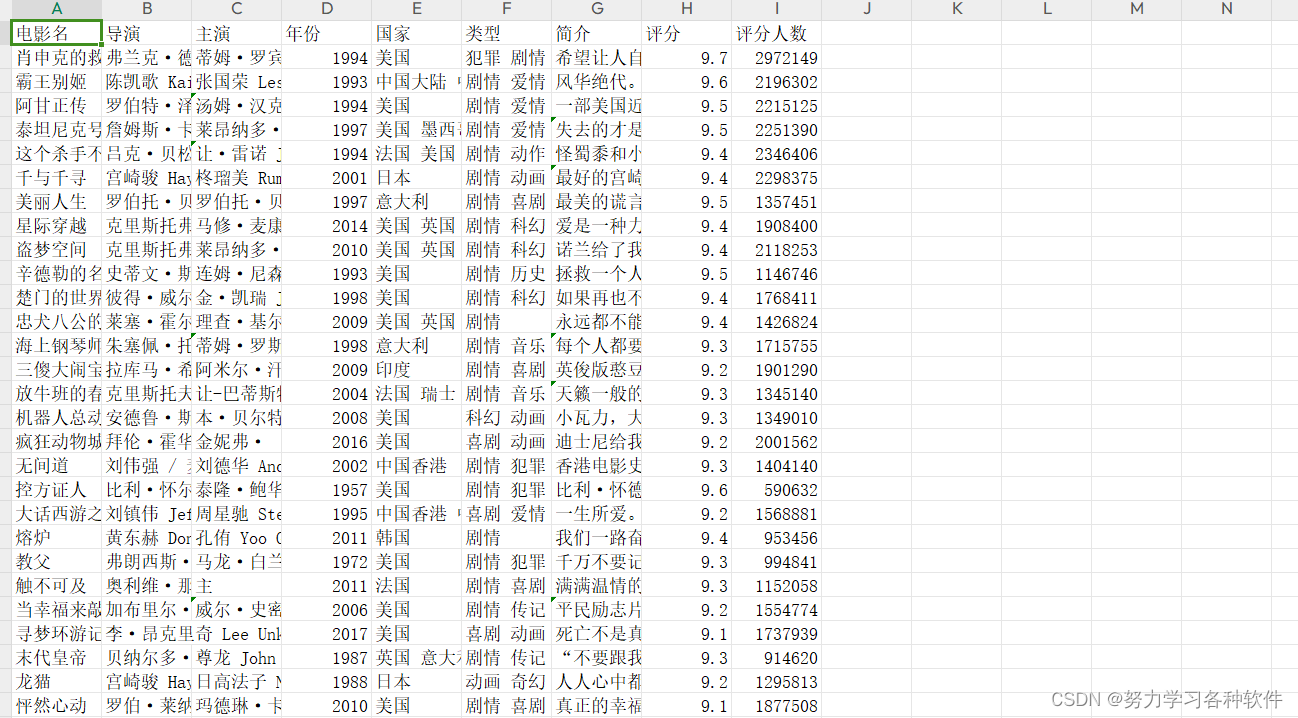
效果:




































![[计算机基础]一、计算机组成原理](https://i-blog.csdnimg.cn/direct/1e4ce5597a354181923d464321cb7d2f.png)