from torch.utils.data import DataLoader,Dataset
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from tqdm import tqdm
device = "cuda" if torch.cuda.is_available() else "cpu"
class CustomDataset(Dataset):
def __init__(self, seq_len=50, future=5,max_len=1000) -> None:
super().__init__()
self.datalist = np.arange(0,max_len)
self.data, self.targets = self.timeseries(self.datalist, seq_len, future)
def __len__(self):
return len(self.data)
def __getitem__(self,index):
x = torch.tensor(self.data[index]).type(torch.Tensor)
y = torch.tensor(self.targets[index]).type(torch.Tensor)
return x, y
def timeseries(self, data, window, future):
temp = []
targs = []
for i in range(len(data) - window - future):
temp.append(data[i:i+window])
targs.append(data[i+window:i+window+future])
return temp, targs
class RNN(nn.Module):
def __init__(self,input_size, hidden_size, nums_layers,future) -> None:
super().__init__()
self.future = future
self.lstm = nn.LSTM(input_size, hidden_size, nums_layers, batch_first =True)
# 它这里是一个非常讨巧的写法,因为output就是一个特征,输出的特征多了怎么办? @todo
self.linear = nn.Linear(hidden_size,future)
def forward(self, x):
out,(hn,cn) = self.lstm(x)
# 这里要对out进行改造,一步的时候是-1,feature步的时候,就是-feature了,他是让最后一层的最后feature个神经元来匹配feature
out = out[:,-self.future,:]
out = self.linear(out)
return out
def get_model_and_optimizer():
learning_rate = 1e-3
model = RNN(input_size=1,hidden_size=256,nums_layers=2,future=5)
optimizer = optim.Adam(model.parameters(),lr=learning_rate)
return model, optimizer
model,optimizer = get_model_and_optimizer()
d = 45
t = torch.tensor(np.arange(d,d+10)).type(torch.Tensor).view(1,-1,1)
print(t)
"""
真正需要的格式
tensor([[[45.],
[46.],
[47.],
[48.],
[49.],
[50.],
[51.],
[52.],
[53.],
[54.]]])
"""
# exit("--=-=-=-=-=")
# 只要保证最后一个维度为1即可,不用关注其中间那个10, 这个10 代表持续10天的数据
res = model(t)
print(res)
loss_fn = nn.MSELoss()
dataset = CustomDataset()
dataloader = DataLoader(dataset,batch_size=8,shuffle=True,num_workers=4)
model = model.to(device)
for x,y in dataset:
print(x,y)
"""
tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13.,
14., 15., 16., 17., 18., 19., 20., 21., 22., 23., 24., 25., 26., 27.,
28., 29., 30., 31., 32., 33., 34., 35., 36., 37., 38., 39., 40., 41.,
42., 43., 44., 45., 46., 47., 48., 49.])
tensor([50., 51., 52., 53., 54.])
"""
break
for x,y in dataloader:
print(x.shape, y.shape)
print(x.view(8,-1,1).shape)
break
def train():
for e in tqdm(range(50)):
e_loss = 0
for x,y in dataloader:
optimizer.zero_grad()
# x = x.view(8,-1,1).to(device)
# RuntimeError: shape '[8, -1, 1]' is invalid for input of size 50
x = x.unsqueeze(0).permute(1,2,0).to(device)
predictions = model(x)
loss = loss_fn(predictions,y.to(device))
loss.backward()
e_loss += loss.cpu().detach().numpy()
optimizer.step()
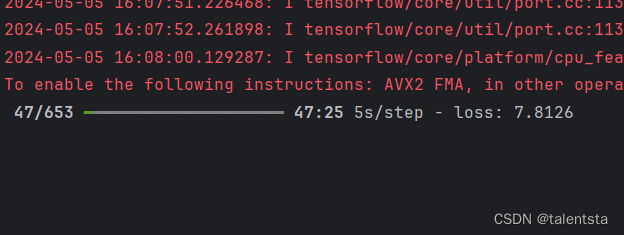
if e%5==0:
print("e, loss=",e_loss)
if __name__ == "__main__":
train()
两种写法的区别是啥,在比较多的情况下没区别,但到最末了,可能不够8个了,强行搞成8个是不对的。
torch.Size([8, 50])
torch.Size([8, 50])
torch.Size([8, 50])
torch.Size([8, 50])
torch.Size([8, 50])
torch.Size([8, 50])
torch.Size([8, 50])
torch.Size([1, 50])
x = x.view(8,-1,1).to(device)
# RuntimeError: shape '[8, -1, 1]' is invalid for input of size 50
x = x.unsqueeze(0).permute(1,2,0).to(device)
就是这个1,50 造成的错误。
这里的
out = out[:,-self.future,:]
是用了一个非常讨巧的方式。
只要了最后的5个神经单元的输出,每个有8个输出。

另外,这份代码中,缺少了overlap的考虑,只考虑了时间窗口,lookback和lookforward的,而没有考虑overlap,但考虑overlap的数据构造器还没想明白【待续】
验证代码:
def show():
model = RNN(input_size=1,hidden_size=256,nums_layers=2,future=5)
model.load_state_dict(torch.load('model_weights.pth'))
d = random.randint(0,1000)
t = torch.tensor(np.arange(d,d+50)).type(torch.Tensor).view(1,-1,1)
r = model(t).view(-1)
fig = plt.figure(figsize=(16,4))
plt_x = np.arange(0,t.shape[1]+len(r))
plt_y = np.arange(d,d+50+len(r))
plt_xp = np.arange(t.shape[1], t.shape[1]+len(r))
plt_yp = r.cpu().detach().numpy()
for i in range(len(r)):
plt.scatter(plt_x, plt_y)
plt.scatter(plt_xp, plt_yp)
plt.savefig("1.jpg")