Python 是进行网络爬虫开发的热门选择,主要是因为其拥有丰富的库和框架,如 Requests、BeautifulSoup、Scrapy 等,这些工具极大地简化了网页数据的抓取和处理过程。以下是一些 Python 爬虫的基础知识和步骤:
1. 理解网络爬虫
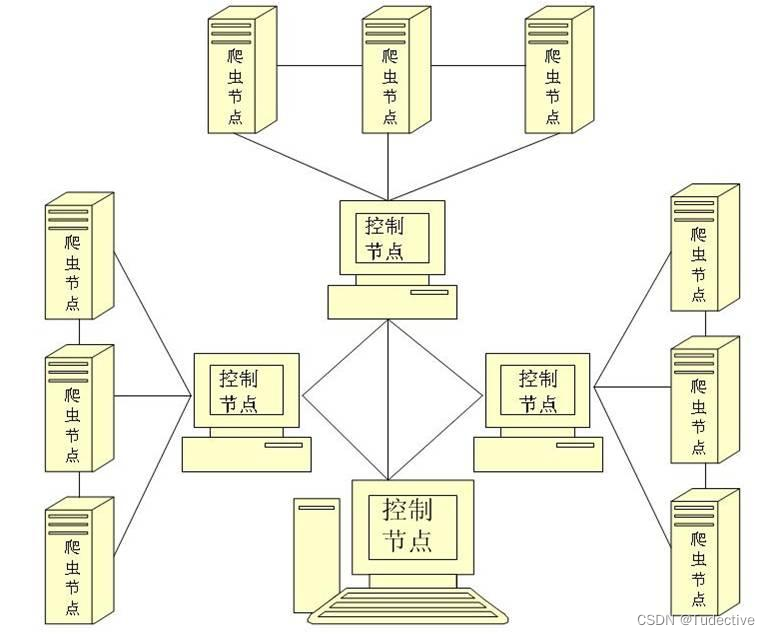
网络爬虫(Web Crawler)或网络蜘蛛(Web Spider)是一种自动化脚本,用于浏览万维网并抓取信息。它们通常从一个或几个初始网页的 URL 开始,读取网页的内容,并在这些网页中找到其他链接的 URL,然后重复此过程,直到达到某个条件为止(如达到一定的深度、爬取到足够的数据或达到指定的时间)。
2. 使用 Requests 发送 HTTP 请求
Requests 是一个简单易用的 HTTP 库,用于发送 HTTP 请求。它支持多种请求方式(如 GET、POST 等),并且能够处理 HTTP 响应。
import requests
url = 'http://example.com'
response = requests.get(url)
# 检查响应状态码
if response.status_code == 200:
# 处理响应内容
print(response.text)
else:
print('请求失败,状态码:', response.status_code)
3. 使用 BeautifulSoup 解析 HTML
BeautifulSoup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库。它创建了一个解析树,用于提取数据,使用方法非常简单。
from bs4 import BeautifulSoup
# 假设 response.text 是从网页获取的 HTML 内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有标题
titles = soup.find_all('h1')
for title in titles:
print(title.text)
4. 处理 JavaScript 渲染的网页
对于使用 JavaScript 动态加载数据的网页,Requests 和 BeautifulSoup 可能无法直接抓取到所需的数据。这时,你可以使用 Selenium,它是一个用于自动化 Web 应用程序测试的工具,但它也可以用来模拟浏览器行为,抓取 JavaScript 渲染后的页面。
from selenium import webdriver
# 设置 Chrome WebDriver 路径
driver = webdriver.Chrome('/path/to/chromedriver')
driver.get('http://example.com')
# 等待页面加载完成(这里需要额外处理,如使用 WebDriverWait)
# 获取页面源代码
html = driver.page_source
# 使用 BeautifulSoup 解析
soup = BeautifulSoup(html, 'html.parser')
# ... 后续处理
driver.quit()
5. 遵守法律和道德准则
在编写爬虫时,务必遵守目标网站的 robots.txt 文件的规定,并尊重网站的版权和使用条款。避免对网站造成不必要的负担,如高频率的请求。
6. 使用 Scrapy 框架
Scrapy 是一个快速的高级 Web 抓取和网页抓取框架,用于爬取网站并从页面中提取结构化的数据。它使用 Python 编写,并且具有强大的功能,如异步请求、自动重试、项目管道等。
# 安装 Scrapy
pip install scrapy
# 创建一个 Scrapy 项目
scrapy startproject myproject
# 编写 Spider
# 在 myproject/myproject/spiders/ 目录下创建一个 Python 文件






















![Bubble Cup 13 - Finals [Online Mirror, unrated, Div. 2] --- G. Years (DSmap)](https://i-blog.csdnimg.cn/direct/2de65b81838d40d3992592678074da0f.png)










