什么是分布式锁
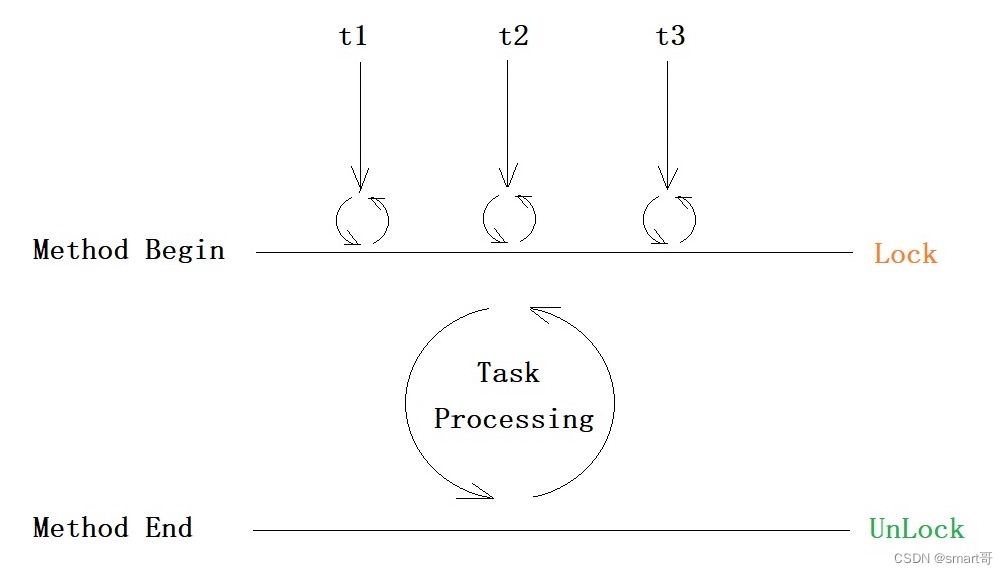
在一个分布式系统中,也会涉及到多个节点访问同一个公共资源的情况。此时就需要通过锁来做互斥控制,避免出现类似于“线程安全”的问题。
而 Java 中的 synchronized 或者 C++ 中的 std::mutex,这样的锁都只能在当前进程中生效,在分布式的这种多个进程多个主机的场景下就无能为力了。此时就需要使用分布式锁。
分布式锁本质就是使用一个公共的服务器,来记录加锁状态。
这个公共的服务器可以是 Redis,也可以是其他组件(比如 MySQL 或者 ZooKeeper 等),还可以是自己写的一个服务器。
基本原理
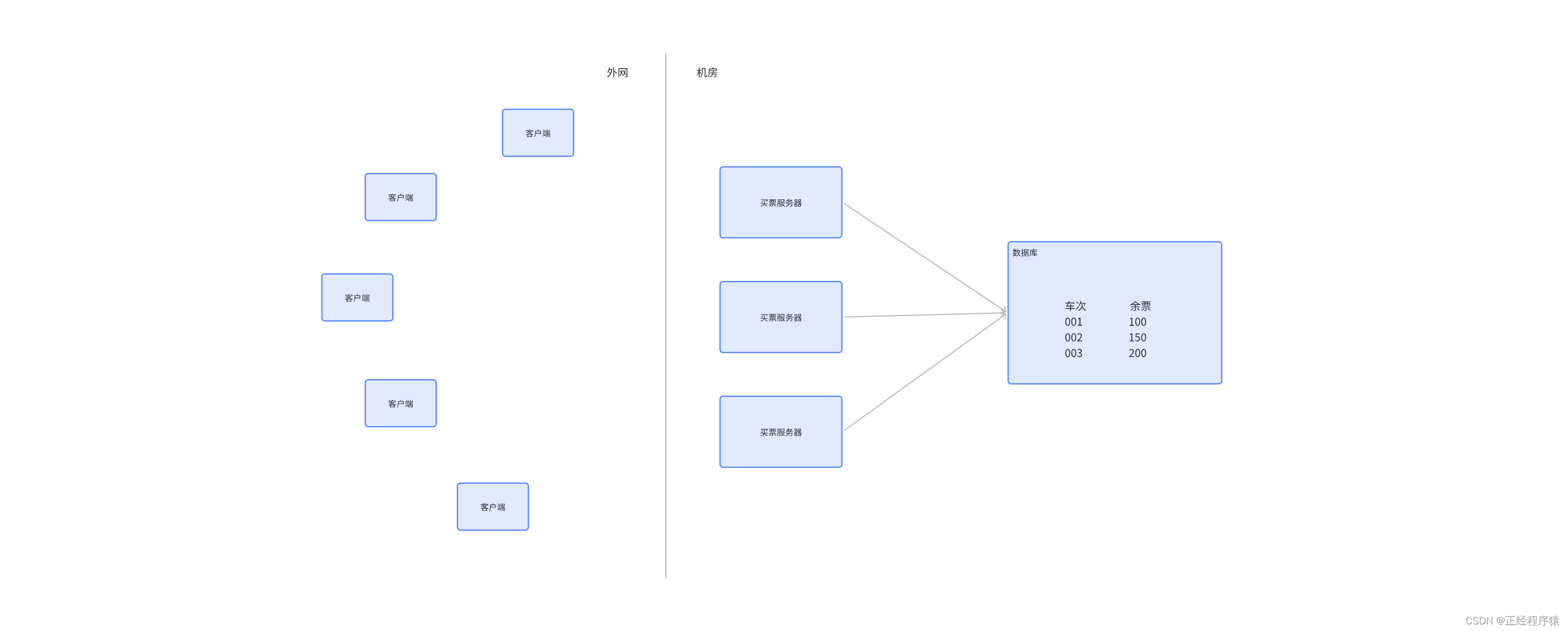
经久不衰的买票案例:

引入一个 Redis,作为分布式锁的管理器。
此时,如果服务器 1 尝试买票,就需要先访问 Redis,在 Redis 上设置一个键值对。
如果这个操作设置成功,就视为当前没有节点对该车次加锁,就可以进行数据库的读写操作。操作完之后,再把 Redis 上刚才的键值对删除。
如果在服务器 1 操作数据库的过程中,服务器 2 也来买票,也会尝试给 Redis 上写一个键值对,key 是同样的车次。但是此时设置的时候发现该车次的 key 已经存在了,则认为已经有其他服务器正在持有锁,此时服务器 2 就需要等待或者暂时放弃。
Redis 中提供了 setnx 操作,正好适用于这个场景。即 key 不存在就设置,存在则直接失败。
但是这个方式可以用来“加锁”,解锁可以通过 del 来删除键值对。但是可能在程序没有执行到“解锁”的时候,服务器就挂了。
引入过期时间
可以使用 set ex nx 的方式,在设置锁的同时把过期时间设置进去。
注意,这里的过期时间只能使用一个命令来设置。因为 Redis 中多个命令是不保证原子性的,或者说 Redis 的原子性就算执行失败也不会回滚。所以拆分成多个命令可能会出现一半成功,一半失败的情况,仍无法正确释放锁。
引入校验id
对于 Redis 中写入的加锁键值对,其他的节点也是可以删除的。为了解决这个问题,可以引入一个校验id。
比如可以把设置的键值对的值,不再是简单地设为一个 1,而是设置成服务器的编号,比如“001”:“服务器 1”。这样就可以在删除 key 的时候,先校验当前删除 key 的服务器是否是当初加锁的服务器,如果是才能真正删除,否则不能删除。
引入lua
为了使解锁操作原子,可以使用 Redis 的 Lua 脚本功能。
Lua的语法类似于JS,是⼀个动态弱类型的语⾔.Lua的解释器⼀般使⽤C语⾔实现.Lua语法简单精炼,执⾏速度快,解释器也⽐较轻量(Lua解释器的可执⾏程序体积只有200KB左右).
因此Lua经常作为其他程序内部嵌⼊的脚本语⾔.Redis本⾝就⽀持Lua作为内嵌脚本.
可以将解锁的指令编写成 Lua 脚本代码,有 redis-cli 或者 redis-plus-plus 或者 jedis 等客户端加载,并发送给 Redis 服务器,由 Redis 服务器来执行这段逻辑。一个 lua 脚本会被 Redis 服务器以原子的方式来执行。
引入 watch dog(看门狗)
在设置了 key 的过期时间之后,仍然存在一定的可能性,当任务还没执行完,key 就先过期了,就导致锁提前失效。而如果设置的时间太长,万一对应的服务器挂了,此时其他服务器也不能及时获取到锁。
所以相比于设置一个固定的长时间,不如动态地调整时间更合适。
所谓的 watch dog,本质上是加锁的服务器上的一个单独的线程,通过这个线程来对锁过期时间进行“续约”。注意,这个线程是业务服务器上的,不是 Redis 服务器的。
举个例子:
初始情况下设置的过期时间为 10s,同时设定看门狗线程每隔 3s 检测一次。
则当 3s 时间到的时候,看门狗就会判定当前任务是否完成。
如果任务已经完成,则直接通过 lua 脚本的方式释放锁
如果任务未完成,则把过期时间重新设置为 10s
这样就不用担心锁提前失效的问题了,而且如果服务器挂了,看门狗线程也就挂了,此时无人续约,这个 key 自然就可以迅速过期,让其他服务器能够获取到锁了。
引入 Redlock 算法
实践中的 Redis 一般是以集群的方式部署的(至少是主从的形式,而不是单机)。那么就可能出现以下比较极端的情况。
服务器1向master节点进⾏加锁操作.这个写⼊key的过程刚刚完成,master挂了;slave节点升级成了新的master节点.但是由于刚才写⼊的这个key尚未来得及同步给slave呢,此时就相当于服务器1的加锁操作形同虚设了,服务器2仍然可以进⾏加锁(即给新的master写⼊key.因为新的master不包含刚才的key).
为了解决这个问题,Redis 的作者提出了 Redlock 算法。
引入一组Redis节点.其中每⼀组Redis节点都包含⼀个主节点和若干从节点.并且组和组之间存储的数据都是⼀致的,相互之间是"备份"关系(而并非是数据集合的⼀部分,这点有别于Rediscluster).
加锁的时候,按照⼀定的顺序,写多个master节点.在写锁的时候需要设定操作的"超时时间".比如50ms.即如果setnx操作超过了50ms还没有成功,就视为加锁失败.
如果给某个节点加锁失败,就⽴即再尝试下⼀个节点.
当加锁成功的节点数超过总节点数的⼀半,才视为加锁成功.
这样的话,即使有某些节点挂了,也不影响锁的正确性。虽然还是有可能出现大多数节点都挂了的情况,但比较概率太小,忽略不计。
同理,释放锁的时候,也需要把所有节点都进行解锁操作。(即使是之前超时的节点,也要尝试解锁,尽量保证逻辑严密)。
简而言之,Redlock 算法的核心就是,加锁操作不能只写给一个 Redis 节点,而要写多个。
分布式中任何一个节点都是不可靠的,最终的加锁成功结论是“少数服从多数”。
由于一个分布式系统不至于大部分节点都同时出现故障,因此这样的可靠性要比单个节点来说靠谱不少。