🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
近年来,随着互联网的飞速发展和数字技术的不断创新,动漫作为一种独特的文化形式,在全球范围内获得了空前的关注度和影响力。动漫不仅成为了年轻一代娱乐生活的重要组成部分,还逐渐渗透到教育、广告、游戏等多个领域,形成了一个庞大的产业链。
特别是在2024年,随着5G、AI、大数据等新一代信息技术的深入应用,动漫产业的数字化、智能化水平得到了显著提升。动漫作品的创作、传播和消费方式都发生了深刻变化,为动漫产业的进一步发展提供了广阔的空间和可能。
然而,与此同时,动漫市场的竞争也日益激烈,各类动漫作品层出不穷,观众对于动漫作品的需求也日益多样化和个性化。在这样的背景下,如何准确把握动漫市场的脉搏,了解观众的需求和喜好,成为了动漫产业发展的重要课题。
因此,本研究旨在通过对2024年热门动漫数据集的可视化分析,深入探究动漫市场的发展趋势和规律,为动漫产业的决策者提供有价值的参考和启示。
2.数据集介绍
本数据集来源于Kaggle,原始数据集共有1000条,22个变量。该数据集全面概述了 2024 年热门动漫,对于构建推荐系统、可视化动漫流行度和评分趋势、预测评分和流行度等非常有用。
该数据集包含 22 个特征:
Score:分配给每个动漫标题的评级或分数。
Popularity:衡量每部动漫在观众中的受欢迎程度。
Rank:数据集中每个动漫标题的排名。
Members:与每部动漫相关的会员或观众数量。
Description:每部动漫的情节和主题的简要概述或摘要。
Synonyms:每部动漫使用的替代标题或同义词。
Japanese:日语动画的原始标题。
English:动画的英文翻译标题。
Type:动漫类型的分类(例如电视剧、电影、OVA 等)。
Episodes:每个动漫系列的总集数。
Status:动画的当前状态(例如,正在进行、已完成等)。
Aired:动画播出的日期范围。
Premiered:动画首次首播的日期。
Broadcast:有关广播平台或频道的信息。
Producers:参与制作动画的公司或工作室。
Licensors:拥有动漫许可权的组织或公司。
Studios:负责制作动画的动画工作室。
Source:动漫的原始来源材料(例如漫画、小说、原创)。
Genres:动漫所属的类别或流派。
Demographic:动漫的目标受众群体。
Duration:每集或电影的持续时间。
Rating:分配给每个动漫的内容评级(例如,G、PG、PG-13、R)。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
首先导入数据可视化的库,并加载数据集
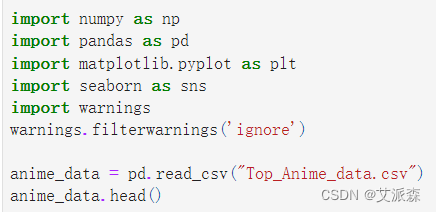
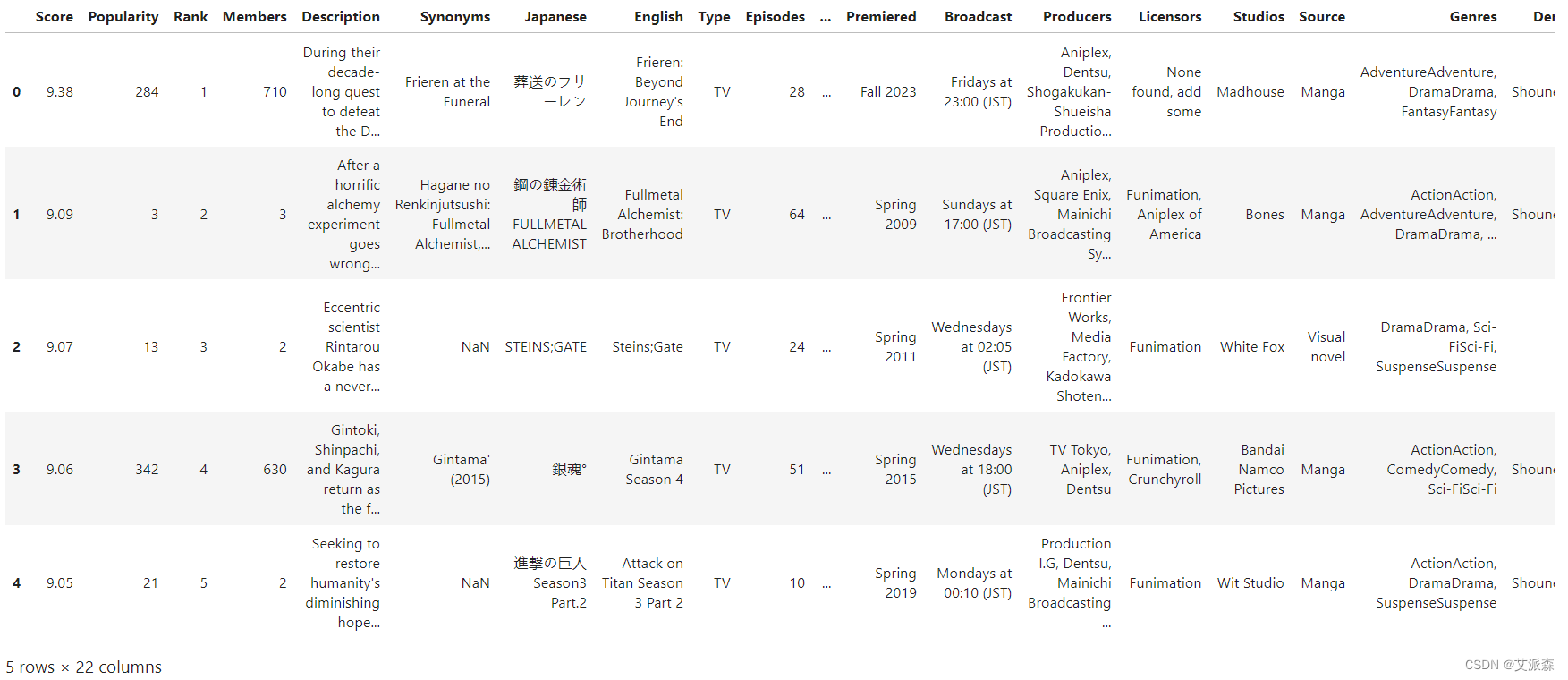
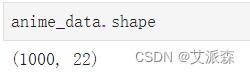
查看数据集大小
查看数据基本信息

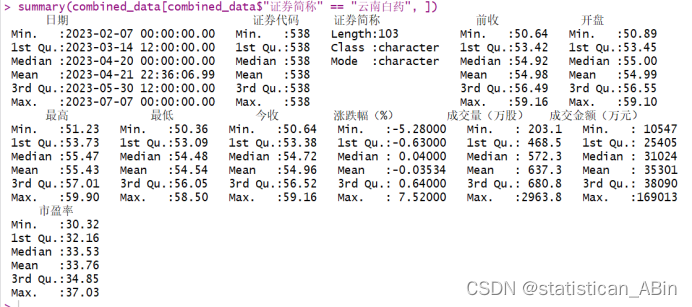
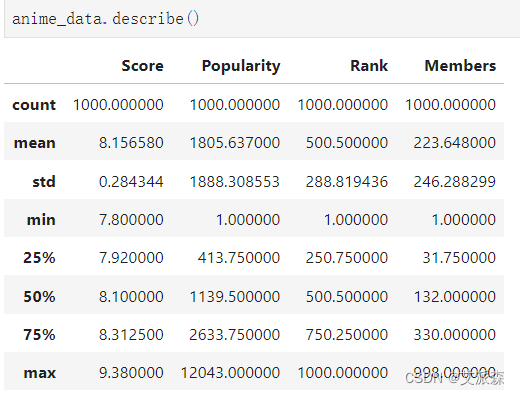
查看数值型变量的描述性统计
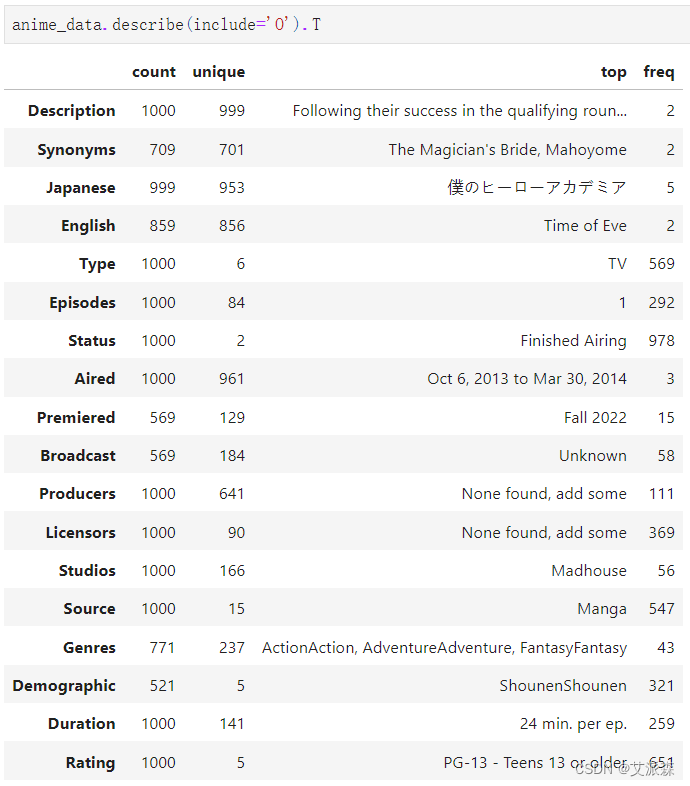
查看非数值型变量的描述性统计
5.数据可视化











源代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
anime_data = pd.read_csv("Top_Anime_data.csv")
anime_data.head()
anime_data.shape
anime_data.info()
anime_data.describe()
anime_data.describe(include='O').T
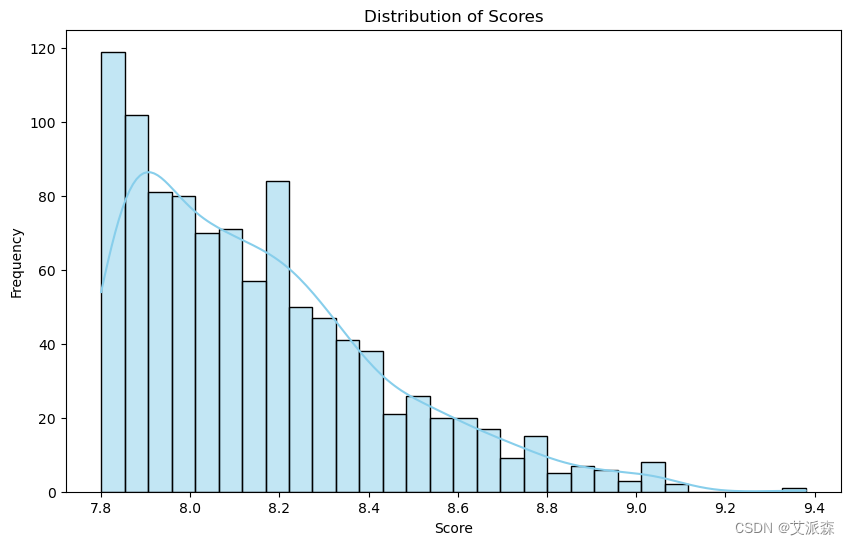
# 分数分布
plt.figure(figsize=(10, 6))
sns.histplot(anime_data['Score'], bins=30, kde=True, color='skyblue')
plt.title('Distribution of Scores')
plt.xlabel('Score')
plt.ylabel('Frequency')
plt.show()
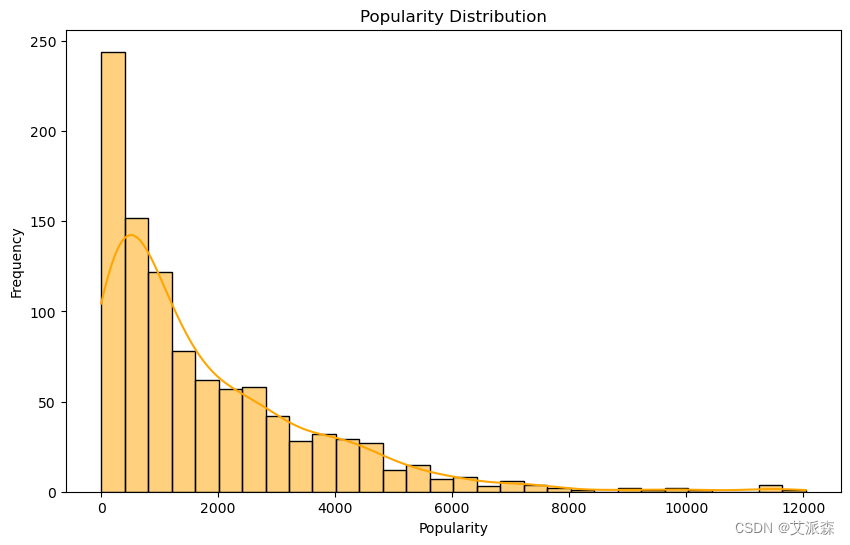
# 受欢迎程度分布
plt.figure(figsize=(10, 6))
sns.histplot(anime_data['Popularity'], bins=30, kde=True, color='orange')
plt.title('Popularity Distribution')
plt.xlabel('Popularity')
plt.ylabel('Frequency')
plt.show()
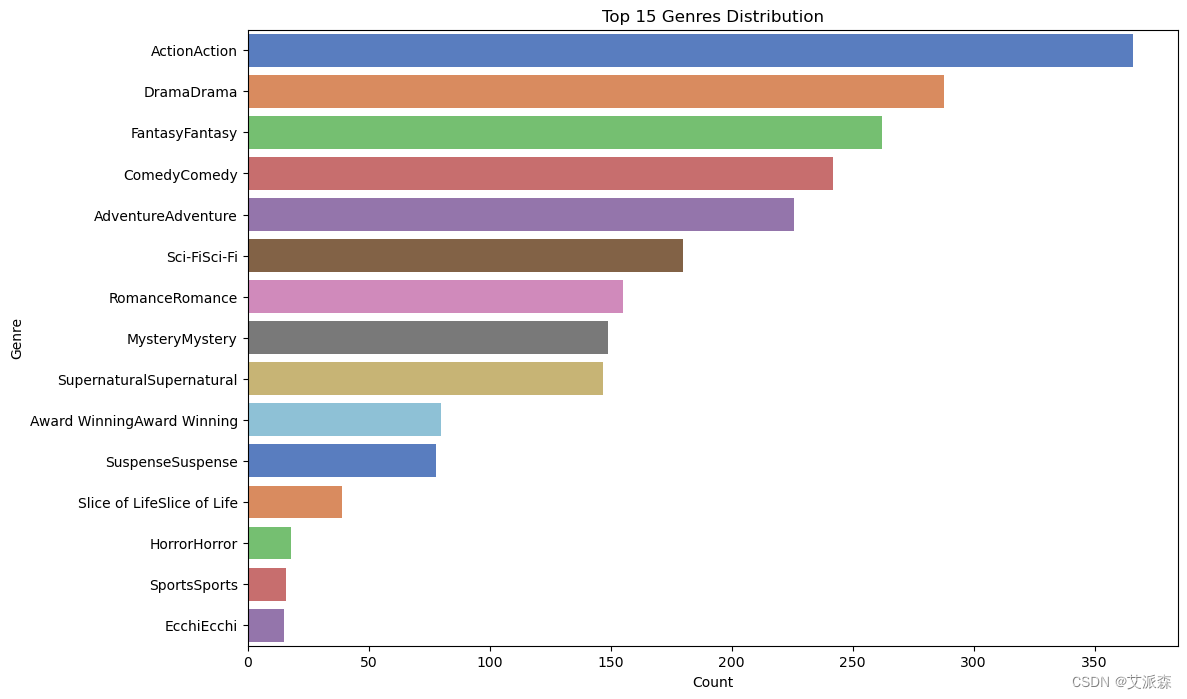
# 类型分布
genres = anime_data['Genres'].str.split(',').explode().str.strip()
plt.figure(figsize=(12, 8))
sns.countplot(y=genres, order=genres.value_counts().index[:15], palette='muted')
plt.title('Top 15 Genres Distribution')
plt.xlabel('Count')
plt.ylabel('Genre')
plt.show()
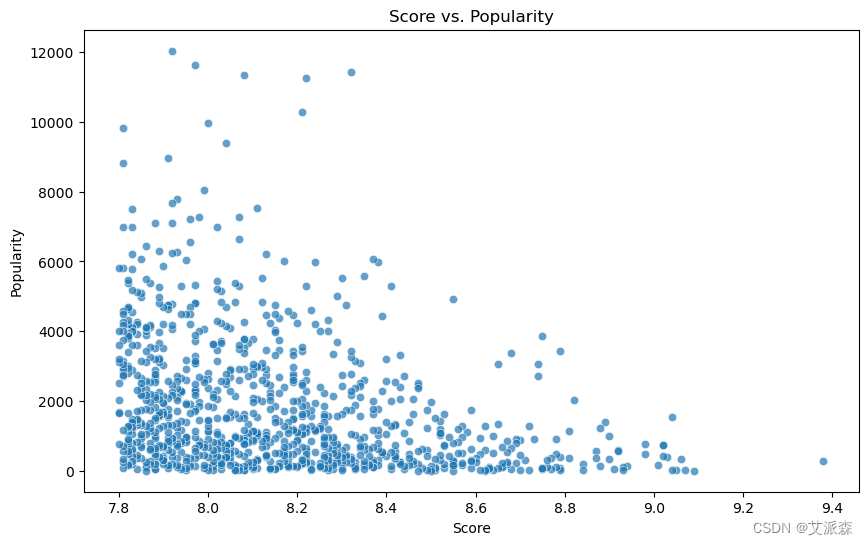
# 分数与人气的散点图
plt.figure(figsize=(10, 6))
sns.scatterplot(x='Score', y='Popularity', data=anime_data, alpha=0.7)
plt.title('Score vs. Popularity')
plt.xlabel('Score')
plt.ylabel('Popularity')
plt.show()
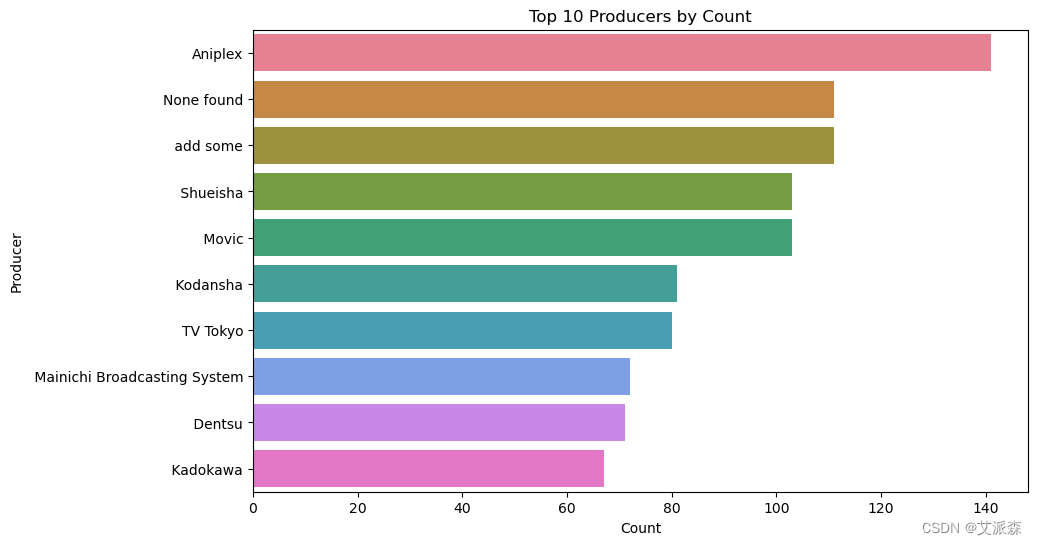
# 排名前十的生产商
top_producers = anime_data['Producers'].str.split(',').explode().value_counts().head(10)
plt.figure(figsize=(10, 6))
sns.barplot(x=top_producers.values, y=top_producers.index, palette='husl')
plt.title('Top 10 Producers by Count')
plt.xlabel('Count')
plt.ylabel('Producer')
plt.show()
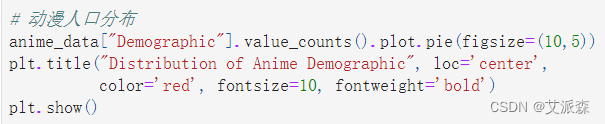
# 动漫人口分布
anime_data["Demographic"].value_counts().plot.pie(figsize=(10,5))
plt.title("Distribution of Anime Demographic", loc='center',
color='red', fontsize=10, fontweight='bold')
plt.show()
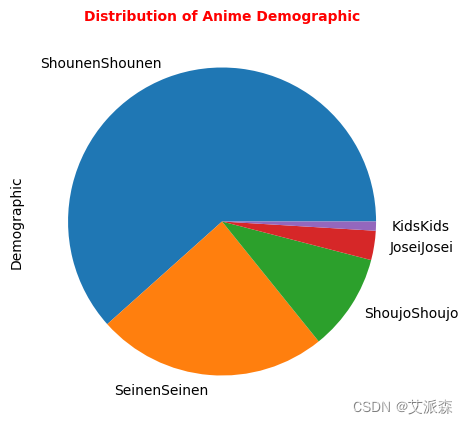
labels=['Teens 13 or older', 'violence & profanity', 'Mild Nudity', 'All Ages', 'Children']
colors=['Pink','Yellow','Orange','Blue','Red']
plt.pie(anime_data["Rating"].value_counts(), labels=labels, colors=colors)
plt.axis('equal')
plt.title("Rating", loc='center', color='Blue', fontsize='15')
plt.gca().add_artist(plt.Circle(xy=(0,0),radius=0.75, facecolor='white'))
plt.show()
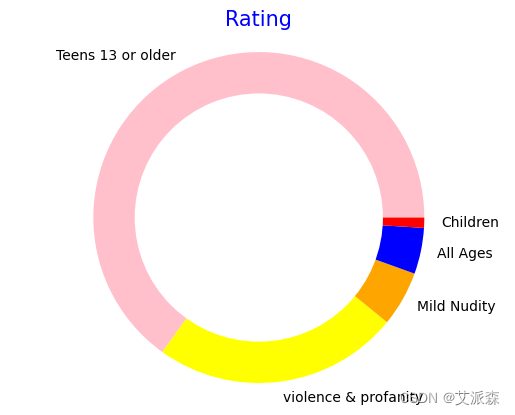
# 分数类别与来源的标准化交叉拟合
bins = [7.8, 7.9, 8.1, 8.3,9.4]
labels = ['7.8 to 7.9', '7.9 to 8.1','8.1 to 8.3','8.3 to 9.4']
anime_data['Score_Category'] = pd.cut(anime_data['Score'], bins=bins, labels=labels, right=False)
normalised_df = (pd.crosstab(anime_data["Score_Category"],anime_data["Source"],normalize="index")*100).round(2)
normalised_df.plot(kind="bar",stacked=True)
plt.xlabel('Score Category')
plt.ylabel('Percentage')
plt.title('Normalized Crosstabulation of Score Category and Source')
plt.legend(title='Source', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()
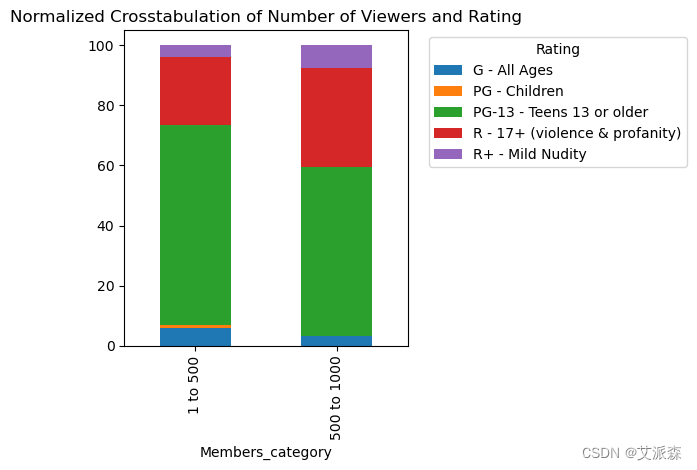
# 收视人数与收视率的标准化交叉校正
bins = [1.0, 500.0, 1000.0]
labels = ['1 to 500', '500 to 1000']
anime_data['Members_category'] = pd.cut(anime_data['Members'], bins=bins, labels=labels, right=False)
(pd.crosstab(anime_data["Members_category"],anime_data["Rating"],normalize="index")*100).round(2).plot(kind="bar",stacked=True)
plt.title('Normalized Crosstabulation of Number of Viewers and Rating')
plt.legend(title='Rating', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()
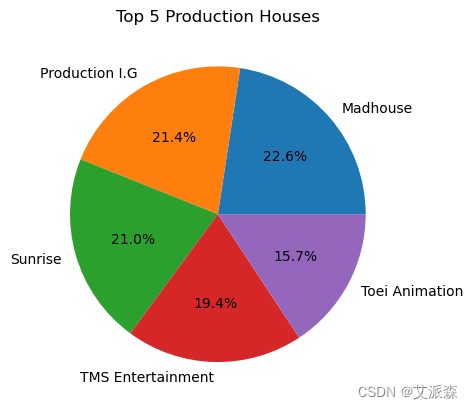
# 5大制作公司
anime_data["Studios"].value_counts().head(5).plot(kind="pie",autopct='%1.1f%%')
plt.title("Top 5 Production Houses")
plt.ylabel('')
plt.show()
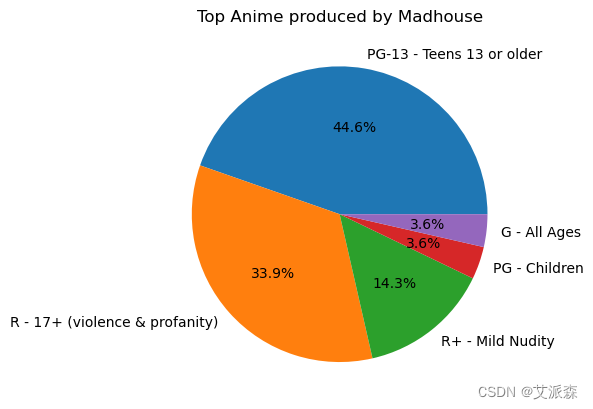
# 疯人院制作的顶级动画
anime_data[anime_data["Studios"] == "Madhouse"]["Rating"].value_counts().plot(kind="pie",autopct='%1.1f%%')
plt.title("Top Anime produced by Madhouse")
plt.show()
资料获取,更多粉丝福利,关注下方公众号获取