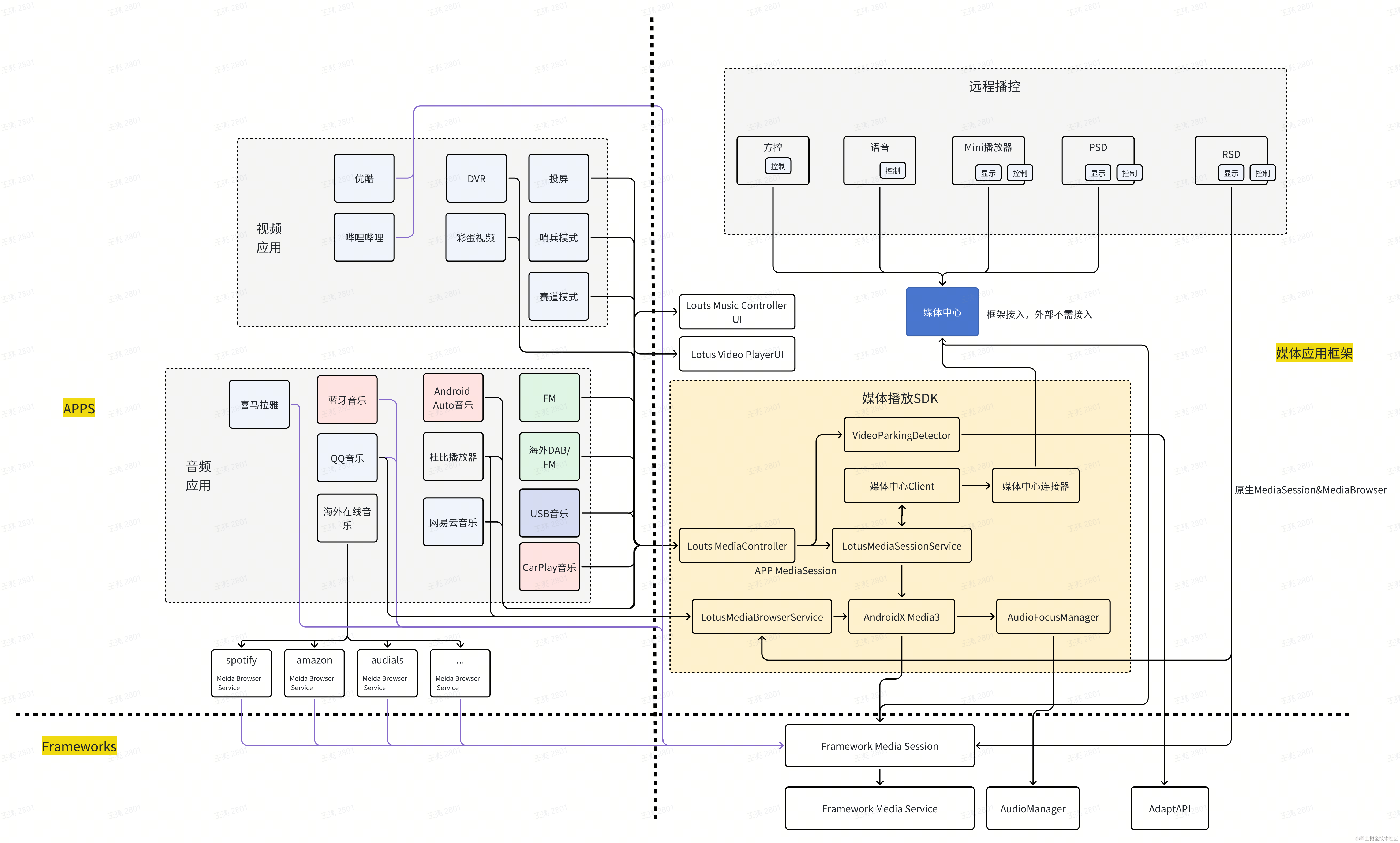
分类
- Hive 的函数分为两大类:内置函数(Built-in-Functions)、用户自定义函数(User-Defined-Functions);
- 内置函数可分为:数值类型函数、日期类型函数、字符串类型函数、集合函数等;
- 用户自定义函数根据输入输出的行数可分为3类:UDF、UDAF、UDTF;
内置函数
- String Function 字符串函数
- Date Function 日期函数
- Mathematical Function 数学函数
- Collection Function 集合函数
- Conditional Function 条件函数
- Type Conversion Function 类型转换函数
- Data Masking Function 数据脱敏函数
- Misc. Function 其他杂项函数
用户自定义函数

UDF(User-Defined-Function) 普通函数,一进一出;
例如:round 这样的函数;

UDAF(User-Defined Aggregation Function)聚合函数,多进一出;
例如:count、sum 这样的函数;

UDTF(User-Defined Table-Generating Function)表生成函数,一进多出;
例如:explode 函数

UDF实现步骤
0、添加 pom 依赖;

1、写一个 Java 类,集成 UDF ,并重载 evaluate 方法,方法中实现函数的业务逻辑;
2、重载意味着可以在一个 Java 类中实现多个函数功能;
3、程序打成 jar 包,上传到 HS2 服务器或者 HDFS;
4、客户端命令行中添加 jar 包到 Hive 的 classpath :add JAR /xxx/udf.jar;
5、注册称为临时函数(给 UDF 命名):create temporary function 函数名 as ‘UDF 类全路径’;
6、HQL 中使用函数;
Hive 常用高阶函数
UDTF explode 函数
- explode 接收 map、array 类型的数据作为输入,然后把输入数据中的每个元素拆开变成一行数据,一个元素一行;
- explode(array) 将 array 里的每个元素生成一行;
- explode(map) 将 map 里的每一对元素作为一行,其中 key 为一列,value 为一列;
- explode 执行的结果可以理解为一张虚拟的表,其数据来源于源表;
UDTF 语法限制
- 在 select 中只查询源表数据没有问题,只查询 explode 生成的虚拟表数据也没问题,但是不能在只查询源表的时候,既想返回源表字段,又想返回 explode 生成的虚拟表字段;简而言之,有两张表,不能只查询一张表但是又想返回分别属于两张表的字段;

UDTF 语法限制解决
- SQL 层面上的解决方案是:对两张表进行 join 关联查询;
- Hive 专门提供了语法 lateral View 侧视图,专门用于搭配 explode 这样的 UDTF 函数;
select a.team_name, b.year from the_nba_championship a lateral view explode(champion_year) b as year;
Lateral View 侧视图
- Lateral View 是一种特殊的语法,主要是搭配 UDTF 类型函数一起使用,用于解决 UDTF 函数的一些查询限制的问题;
- 一般只要使用 UDTF,就会固定搭配 lateral view 使用;
原理
- 将 UDTF 的结果构建成一个类似于视图的表,然后将原表中的每一行和 UDTF 函数输出的每一行进行连接,生成新的虚拟表。这样就避免了 UDTF 的使用限制问题;
- 使用 lateral view 时也可以对 UDTF 产生的记录设置字段名称,产生的字段可以用于 group by、order by limit 等语句中,不需要再单独嵌套一层子查询;

增强聚合函数
- 增强聚合包括 grouping sets 、cube、rollup 这几个函数。主要适用于 OLAP 多维数据分析模式中。多维分析中的多维指的分析问题时看待问题的维度、角度;
grouping_sets:
一种将多个 group by 逻辑写在一个 SQL 语句中的便利写法。等价于将不同维度的 group by 进行 union all。GROUPING_ID 表示结果属于哪一个分组集合;
例子:
SELECT month, day, COUNT(DISTINCT cookieid) AS nums, GROUPING__ID
FROM cookie_info
GROUP BY month, day GROUPING SETS (month, day)
ORDER BY GROUPING__ID;
--grouping_id 表示这一组结果属于哪个分组集合
--根据grouping sets中的分组条件month,day,1代表month,2代表day
等价于
SELECT month, NULL, COUNT(DISTINCT cookieid) AS nums, 1 AS GROUPING__ID
FROM cookie_info
GROUP BY month
UNION ALL
SELECT NULL as month, day, COUNT(DISTINCT cookieid) AS nums, 2 AS GROUPING__ID
FROM cookie_info
GROUP BY day;
cube:
cube 表示根据 group by 的维度的所有组合进行聚合,如果有n个维度,则所有组合的总个数是2^n。比如cube有a,b,c 3个维度,则所有组合情况是: (a,b,c),(a,b),(b,c),(a,c),(a),(b),©,()
SELECT month, day, COUNT(DISTINCT cookieid) AS nums, GROUPING__ID
FROM cookie_info
GROUP BY month, day
WITH CUBE
ORDER BY GROUPING__ID;
等价于
SELECT NULL, NULL, COUNT(DISTINCT cookieid) AS nums, 0 AS GROUPING__ID
FROM cookie_info
UNION ALL
SELECT month, NULL, COUNT(DISTINCT cookieid) AS nums, 1 AS GROUPING__ID
FROM cookie_info
GROUP BY month
UNION ALL
SELECT NULL, day, COUNT(DISTINCT cookieid) AS nums, 2 AS GROUPING__ID
FROM cookie_info
GROUP BY day
UNION ALL
SELECT month, day, COUNT(DISTINCT cookieid) AS nums, 3 AS GROUPING__ID
FROM cookie_info
GROUP BY month, day;
rollup
rollup 是 cube 的子集,以最左侧的维度为主,从该维度进行层级聚合。比如ROLLUP有a,b,c3个维度,则所有组合情况是:(a,b,c),(a,b),(a),();
-- --比如,以month维度进行层级聚合:
SELECT month, day, COUNT(DISTINCT cookieid) AS nums, GROUPING__ID
FROM cookie_info
GROUP BY month, day
WITH ROLLUP
ORDER BY GROUPING__ID;
--把month和day调换顺序,则以day维度进行层级聚合:
SELECT day, month, COUNT(DISTINCT cookieid) AS uv, GROUPING__ID
FROM cookie_info
GROUP BY day, month
WITH ROLLUP
ORDER BY GROUPING__ID;
Window Function 窗口函数
- 窗口函数也叫开窗函数,OLAP 函数,其最大的特点是:输入值是从 select 语句的结果集中一行或多行的“窗口”中获取的;
- 如果函数具有 over 子句,则它是窗口函数;
- 窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过 group by 子句组合的常规聚合会隐藏正在聚合的各个行,最终输出一行,窗口函数聚合后还可以访问当中的各个行,并且可以将这些行中的某些属性添加到结果集中;

例子:通过sum聚合函数进行普通常规聚合和窗口聚合,来直观感受窗口函数的特点;
----sum+group by普通常规聚合操作------------
select sum(salary) as total
from employee
group by dept;

----sum+窗口函数聚合操作------------
select id, name, deg, salary, dept, sum(salary) over (partition by dept) as total
from employee;

窗口聚合函数
- 所谓窗口聚合函数指的是 sum、max、min、avg 这样的聚合函数在窗口中的使用;
以 sum 为例:
--1、求出每个用户总pv数 sum+group by普通常规聚合操作
select cookieid,sum(pv) as total_pv from website_pv_info group by cookieid;
--2、sum+窗口函数 总共有四种用法 注意是整体聚合 还是累积聚合
-- --sum(...) over( )对表所有行求和
-- --sum(...) over( order by ... ) 连续累积求和
-- --sum(...) over( partition by... ) 同组内所行求和
-- --sum(...) over( partition by... order by ... ) 在每个分组内,连续累积求和


窗口表达式
- 在 sum(…) over(partition by … order by …)语法完整的情况下,进行累积聚合操作,默认累积聚合行为是从第一行聚合到当前行;
- 窗口表达式给我们提供了一种控制执行范围的能力,比如向前2行,向后3行;

--第一行到当前行
select cookieid,
createtime,
pv,
sum(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from website_pv_info;
--向前3行至当前行
select cookieid,
createtime,
pv,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4
from website_pv_info;
--向前3行 向后1行
select cookieid,
createtime,
pv,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5
from website_pv_info;
--当前行至最后一行
select cookieid,
createtime,
pv,
sum(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from website_pv_info;
--第一行到最后一行 也就是分组内的所有行
select cookieid,
createtime,
pv,
sum(pv)
over (partition by cookieid order by createtime rows between unbounded preceding and unbounded following) as pv6
from website_pv_info;
窗口排序函数
- 用于给每个分组内的数据打上排序的标号,注意窗口排序函数不支持窗口表达式;
- 适合用于 Top N 业务分析;
row_number:在每个分组中,为每行分配一个从1开始的序列号,递增,不考虑重复;
rank:在每个分组中,为每行分配一个从1开始的序列号,考虑重复,挤占后续位置;
dense_rank:在每个分组中,为每行分配一个从1开始的序列号,考虑重复,不挤占后续位置;
SELECT cookieid,
createtime,
pv,
RANK() OVER (PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER (PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER (PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM website_pv_info
WHERE cookieid = 'cookie1';

ntile:将每个分组内的数据分为指定的若干个桶里,并且为每一个桶分配一个桶编号。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1;
--把每个分组内的数据分为3桶
SELECT cookieid, createtime, pv,
NTILE(3) OVER (PARTITION BY cookieid ORDER BY createtime) AS rn2
FROM website_pv_info
ORDER BY cookieid, createtime;

窗口分析函数
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时,取默认值,如不指定,则为NULL);LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认1),第三个参数为默认值(当往下第n行为NULL时,取默认值,如不指定,则为NULL);FIRST_VALUE 取分组内排序后,截至到当前行,第一个值;
LAST_VALUE 取分组内排序后,截至到当前行,最后一个值;
--LAG
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER (PARTITION BY cookieid ORDER BY createtime) AS rn,
LAG(createtime, 1, '1970-01-01 00:00:00')
OVER (PARTITION BY cookieid ORDER BY createtime) AS last_1_time, LAG(createtime, 2) OVER (PARTITION BY cookieid ORDER BY createtime) AS last_2_time
FROM website_url_info;
--LEAD
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER (PARTITION BY cookieid ORDER BY createtime) AS rn, LEAD(createtime, 1, '1970-01-01 00:00:00') OVER (PARTITION BY cookieid ORDER BY createtime) AS next_1_time, LEAD(createtime, 2) OVER (PARTITION BY cookieid ORDER BY createtime) AS next_2_time
FROM website_url_info;
--FIRST_VALUE
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER (PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(url) OVER (PARTITION BY cookieid ORDER BY createtime) AS first1
FROM website_url_info;
--LAST_VALUE
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER (PARTITION BY cookieid ORDER BY createtime) AS rn, LAST_VALUE(url) OVER (PARTITION BY cookieid ORDER BY createtime) AS last1
FROM website_url_info;
sampling 抽样函数
- 在 HQL 中,可以通过三种方式采样数据:随机采样,存储桶表采样和块采样;
Random 随机采样
- 使用 rand() 函数来确保随机获取数据,LIMIT 来限制抽取个数;
- 优点是随机,缺点是速度不快,尤其是表数据多的时候;
- 推荐 distribute + sort ,可以确保数据也随机分布在 mapper 和 reducer 之间,使得底层执行有效率;
--需求:随机抽取2个学生的情况进行查看
SELECT *
FROM student DISTRIBUTE BY rand() SORT BY rand() LIMIT 2;

Block 基于数据块抽样
- Block 块采样允许随机获取n行数据、百分比数据或指定大小的数据;
- 采样的粒度是 HDFS 块大小;
- 优点是速度快,缺点是不随机;
--block抽样
--根据行数抽样
SELECT * FROM student TABLESAMPLE (1 ROWS);
--根据数据大小百分比抽样
SELECT * FROM student TABLESAMPLE (50 PERCENT);
--根据数据大小抽样
--支持数据单位 b/B, k/K, m/M, g/G
SELECT * FROM student TABLESAMPLE (1k);
Bucket table 基于分桶表抽样
- 这是一种特殊的采样方法,针对分桶表进行了优化;
- 优点是即随机,速度又很快;
---bucket table抽样
--根据整行数据进行抽样
SELECT * FROM t_usa_covid19_bucket TABLESAMPLE(BUCKET 1 OUT OF 2 ON rand());
--根据分桶字段进行抽样 效率更高
SELECT * FROM t_usa_covid19_bucket TABLESAMPLE(BUCKET 1 OUT OF 2 ON state);






























![[网鼎杯 2018]Fakebook](https://i-blog.csdnimg.cn/direct/4aebbb96661f419ca2090007e1af5cf2.png)