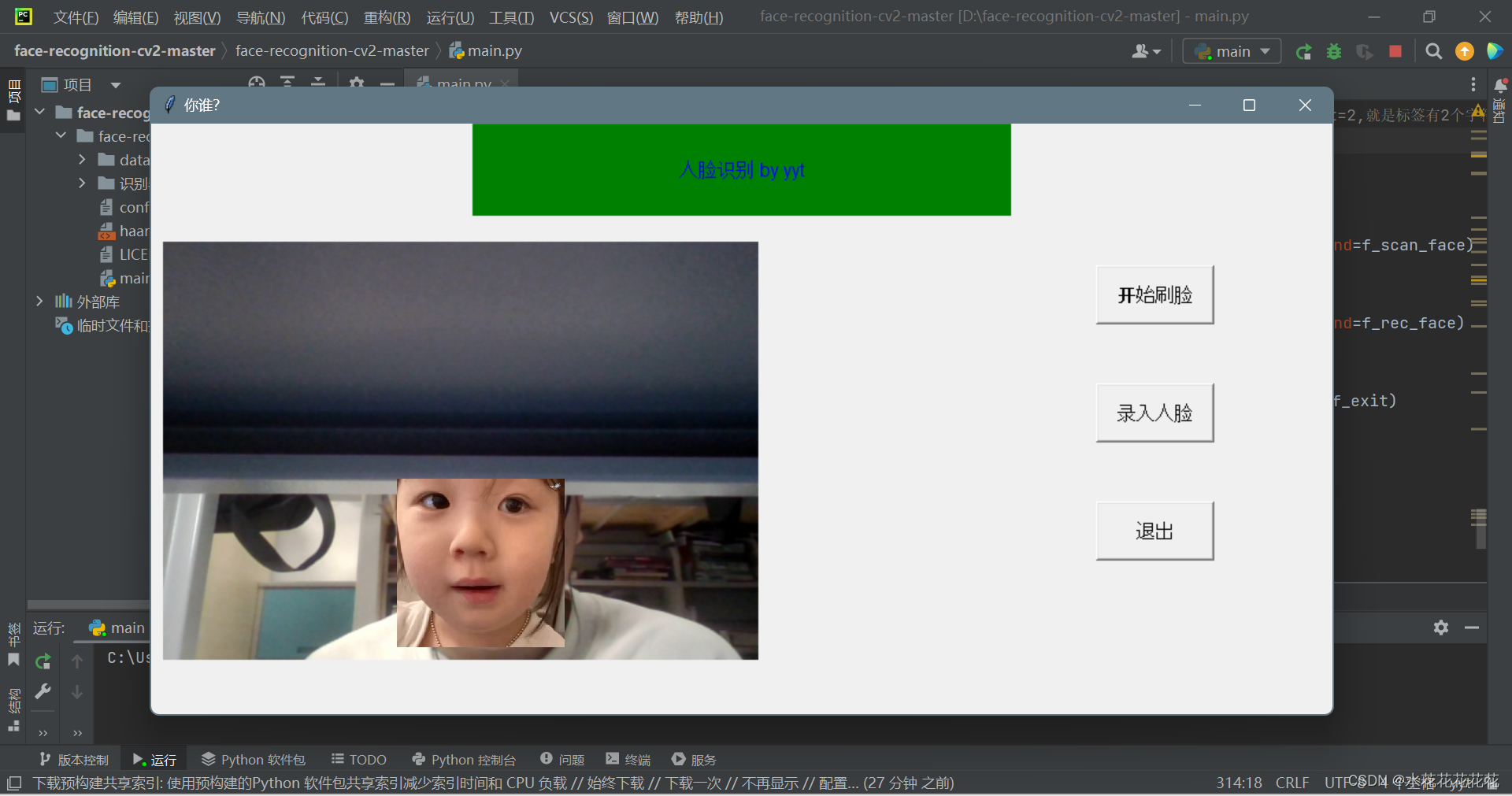
Hive 函数
1. Hive 函数分类
从输入输出的角度,可以将Hive的函数分为3类:标准函数、聚合函数、表生成函数
标准函数:以一行中的一列或多列数据作为输入的参数且返回结果是一个值的函数。
标准函数返回值只有一个,返回值类型为基本数据类型或复杂数据类型,如cast()
聚合函数:以多行的零个或多个列的数据作为输入且返回单一值的函数。
聚合函数常与
group by子句结合使用。例如 sum(), count(), max()等表生成函数:接受零个或多个输入且产生多列或多行输出的函数。
1.1 查看函数命令
show functions命令用于显示当前Hive会话中加载的所有函数,包括 内置函数、自定义函数desc function function_name和desc function extended function_name两个命令可以用于查看指定函数名称的描述,extended 关键字可以显示的更加详细
1.2 调用函数
通过在查询语句中调用函数名,并传入参数来调用函数,函数的调用可以用于 select 与 where 子句中,包括以下3种典型情况:
(1) select concat(cola, colb) as x from table_name;
(2)select concat('abc', 'def');
(3)select * from table_name where length(col)<10;
2. Hive内置函数
数据集:
testData.txt创建数据库:
create database wedw_tmp;创建数据表:
tmp_url_info
create table tmp_url_info(
user_id string comment "用户id",
visit_url string comment "访问url",
visit_cnt int comment "浏览次数/pv",
visit_time timestamp comment "浏览时间",
visit_date string comment "浏览日期"
)
row format delimited
fields terminated by ','
stored as textfile;
2.1 字符相关
字符相关的函数侧重于对字符串进行处理。以下时使用频率高的字符函数。
concat
字符拼接,对多个字符串或二进制字符码按照参数顺序进行拼接。
concat(string|binary A, string|binary B...)
select concat('a','b','c');
abc
concat_ws
按照指定分隔符将字符或者数组进行拼接;第一个参数是分隔符。
concat_ws(string SEP, array)/concat_ws(string SEP, string A, string B...)
select concat_ws('','a','b','c')
a b c
#将数组列表元素按照指定分隔符拼接,类似于python中的join方法
select concat_ws('',array('a','b','c'))
a b c
select concat_ws(",",array('a','b','c'));
a,b,c
instr
查找字符串str中子字符串substr出现的位置,如果查找失败将返回0,如果任一参数为Null将返回null,注意位置为从1开始的,如果查找失败返回0
select
user_id,
visit_time,
visit_date,
visit_cnt
from wedw_tmp.tmp_url_info
where instr(visit_time,'10')>0;
hive> select instr('abcd','a'); OK 1
length
统计字符串的长度 length(string a)
select length('abc');
3
trim
将字符串前后的空格去掉,和java中的trim方法一样,
#最后会得到sfssf sdf sdfds
select trim(' sfssf sdf sdfds ');
upper
字符串中所有的字母转为大写 upper(string a)
select upper(concat_ws('', customer_fname, customer_lname)) as fullname from customers limit 10;
lower
字符串中所有的字母转为小写 lower(string a)
substr
截取字符串中从指定位置开始,指定长度的子字符串并返回,其中长度可选,默认截取到末尾。
substr(string a, int start, [int length ])
2.2 类型转换函数
cast(字段名 as 转换的类型), 将 expr 的数据类型转换为 type 类型,如果转换失败,返回null
CHAR[(N)] 字符型
DATE 日期型
DATETIME 日期和时间型
DECIMAL float型
SIGNED int
TIME 时间型
hive> select cast(round(9/3) as int);
OK
3
2.3 聚合函数
聚合函数是在一组多行数据中进行计算并返回单一值的函数。常用的聚合函数如下:
count() sum() max() min() avg()
2.4 数学函数
round
round(double a) 返回对a四舍五入的BIGINT值
round(double a, int d) 返回对a四舍五入,保留d位小数的值
select round(4/3),round(4/3,2);
ceil
求不小于给定实数的最小整数;向上取整
ceil(double a), ceiling(double a)
select ceil(4/3),ceiling(4/3);
2
floor
对给定的实数向下取整
floor(double a)
select floor(4/3);
示例:对订单总金额进行四舍五入,要求精度位小数点后两位。
select order_id, round(sum(cast(order_items.order_ite_subtotal as float)),2)
from orders join order_items on orders_id = order_items.order_item_order_id
group by order_id limit 10;
2.5 日期函数
from_unxitime
from_unixtime(bigint unixtime[, string format])
将时间的秒值转换成format格式(format可为“yyyy-MM-dd hh:mm:ss”,“yyyy-MM-dd hh”,“yyyy-MM-dd hh:mm”等等)
select from_unixtime(1599898989,'yyyy-MM-dd') as current_time
unix_timestamp
unix_timestamp():获取当前时间戳
unix_timestamp(string date):获取指定时间对应的时间戳
通过该函数结合from_unixtime使用,或者可计算两个时间差等
select
unix_timestamp() as current_timestamp,--获取当前时间戳
unix_timestamp('2020-09-01 12:03:22') as speical_timestamp,--指定时间对于的时间戳
from_unixtime(unix_timestamp(),'yyyy-MM-dd') as current_date --获取当前日期
to_date
to_date(string timestamp)
返回时间字符串的日期部分
--最后得到2020-09-10
select to_date('2020-09-10 10:31:31')
year
year(string date)
返回时间字符串的年份部分
--最后得到2020
select year('2020-09-02')
month
month(string date)
返回时间字符串的月份部分
--最后得到09
select month('2020-09-10')
day
day(string date)
返回时间字符串的天
--最后得到10
select day('2002-09-10')
date_add
date_add(string startdate, int days)
从开始时间startdate加上days
--获取当前时间下未来一周的时间
select date_add(now(),7)
--获取上周的时间
select date_add(now(),-7)
date_sub
date_sub(string startdate, int days)
从开始时间startdate减去days
--获取当前时间下未来一周的时间
select date_sub(now(),-7)
--获取上周的时间
select date_sub(now(),7)
示例:统计月度订单数量
select from_unxitime(unix_timestamp(order_date), "yyyy-MM") as year_month,
count(order_id) from orders
group by from_unxitime(unix_timestamp(order_date), "yyyy-MM")
2.6 条件函数
if
if(boolean testCondition, T valueTrue, T valueFalseOrNull):判断函数,很简单
如果testCondition 为true就返回valueTrue,否则返回valueFalseOrNull
--判断是否为user1用户
select
distinct user_id,
if(user_id='user1',true,false) as flag
from wedw_tmp.tmp_url_info
case when
CASE a WHEN b THEN c [WHEN d THEN e] [ELSE f] END
如果a=b就返回c,a=d就返回e,否则返回f 如CASE 4 WHEN 5 THEN 5 WHEN 4 THEN 4 ELSE 3 END 将返回4
相比if,个人更倾向于使用case when
--仍然以if上面的列子
select
distinct user_id,
case when user_id='user1' then 'true'
when user_id='user2' then 'test'
else 'false' end as flag
from wedw_tmp.tmp_url_info
coalesce
COALESCE(T v1, T v2, …)
返回第一非null的值,如果全部都为NULL就返回NULL
--该函数结合lead或者lag更容易贴近实际业务需求,这里使用lead,并取后3行的值作为当前行值
select
user_id,
visit_time,
rank,
lead_time,
coalesce(visit_time,lead_time) as has_time
from
(
select
user_id,
visit_time,
visit_cnt,
row_number() over(partition by user_id order by visit_date desc) as rank,
lead(visit_time,3) over(partition by user_id order by visit_date desc) as lead_time
from wedw_tmp.tmp_url_info
order by user_id
)t;
hive> select coalesce(null,'aa');
OK
aa
示例:根据商品价格将商品分为3个级别:0~100, 100~200及200以上,并分别统计各档商品个数
select level, count(*) from (select *, case when product_price<100 then 1
when product_price between 100 and 200 then 2
else 3 end as level
from products) as a
group by level;
2.7 集合函数
collect_set
将分组内的数据放入到一个集合中,具有去重的功能;
create table collect_set (name string, area string, course string, score int); insert into table collect_set values('zhang3','bj','math',88); insert into table collect_set values('li4','bj','math',99); insert into table collect_set values('wang5','sh','chinese',92); insert into table collect_set values('zhao6','sh','chinese',54); insert into table collect_set values('tian7','bj','chinese',91); --把同一分组的不同行的数据聚合成一个集合 select course,collect_set(area),avg(score)from collect_set group by course; OK chinese ["sh","bj"] 79.0 math ["bj"] 93.5 --用下标可以取某一个 select course,collect_set(area)[1],avg(score)from collect_set group by course; OK chinese sh 79.0 math bj 93.5
--统计每个用户具体哪些天访问过
select
user_id,
collect_set(visit_date) over(partition by user_id) as visit_date_set
from wedw_tmp.tmp_url_info
collect_list
和collect_set一样,但是没有去重功能
select
user_id,
collect_set(visit_date) over(partition by user_id) as visit_date_set
from wedw_tmp.tmp_url_info
sort_array
数组内排序;通常结合collect_set或者collect_list使用;
如collect_list为例子,可以发现日期并不是按照顺序组合的,这里有需求需要按照时间升序的方式来组合
--按照时间升序来组合
select
user_id,
sort_array(collect_list(visit_date) over(partition by user_id)) as visit_date_set
from wedw_tmp.tmp_url_info;
--按照时间降序排序
select
user_id,
collect_list(visit_date) over(partition by user_id order by visit_date desc) as visit_date_set
from wedw_tmp.tmp_url_info;
size
是用来统计数组或者map的元素,通常笔者用该函数用来统计去重数(一般都是通过distinct,然后count统计,但是这种方式效率较慢)
--使用size
select
distinct size(collect_set(user_id) over(partition by year(visit_date)))
from wedw_tmp.tmp_url_info;
--使用通过distinct,然后count统计的方式
select
count(1)
from
(
select
distinct user_id
from wedw_tmp.tmp_url_info
)t;
explode
列转行,通常是将一个数组内的元素打开,拆成多行
--简单例子
select explode(array(1,2,3,4,5))
--结合lateral view 使用
select
get_json_object(user,'$.user_id')
from
(
select
distinct collect_set(concat('{"user_id":"',user_id,'"}')) over(partition by year(visit_date)) as user_list
from wedw_tmp.tmp_url_info
)t
lateral view explode(user_list) user_list as user