并发版爬虫
在上一篇中,简单版的百度贴吧爬虫,我们只能单个进行爬,速度缓慢,利用Go语言的并发特性,我们可以单开辟一个协程进行处理。
package main
import (
"fmt"
"net/http"
"os"
"strconv"
)
func HttpGet(ur1 string) (result string, err error) {
resp, err1 := http.Get(ur1)
if err1 != nil {
err = err1
return
}
defer resp.Body.Close()
//读取网页内容
buf := make([]byte, 1024*4)
for {
n, err := resp.Body.Read(buf)
if n == 0 { //读取结束或者出问题了
fmt.Println("resp.Body.Read.err=", err)
break
}
result += string(buf[:n])
}
return
}
// 爬取一个网页
func SqiderPage(i int, page chan<- int) {
//明确要在那一个范围进行搜索
ur1 := "https://tieba.baidu.com/f?ie=utf-8&kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&pn=" +
strconv.Itoa((i-1)*50)
fmt.Printf("正在爬%d页网页:%s\n", i, ur1)
//爬
result, err := HttpGet(ur1)
if err != nil {
fmt.Println("HttpGet.err=", err)
return
}
//把内容写入文件
fileName := strconv.Itoa(i) + ".html"
f, err1 := os.Create(fileName)
if err1 != nil {
fmt.Println("os.Create.err1=", err1)
return
}
f.WriteString(result) //写
f.Close()
page <- i
}
func DoWork(start, end int) {
fmt.Printf("正在爬取%d到%d的页面\n", start, end)
page := make(chan int)
for i := start; i <= end; i++ {
go SqiderPage(i, page)
}
for i := start; i <= end; i++ {
//阻塞等待看,避免还没有爬玩就DoWork退出
fmt.Printf("第%d个页面爬取完成\n", <-page)
}
}
func main() {
var start, end int
fmt.Printf("请输入起始页(>=1):")
fmt.Scan(&start)
fmt.Printf("请输入终止页(>=起始页):")
fmt.Scan(&end)
DoWork(start, end)
}
- 与之前不同的是,我们在DoWork中开辟了新的子协程去处理爬虫
go SqiderPage(i, page) - 为了避免for循环在爬虫没有结束的时候,就退出而导致爬虫失败,我们采用了channel来阻塞等待爬虫成功。
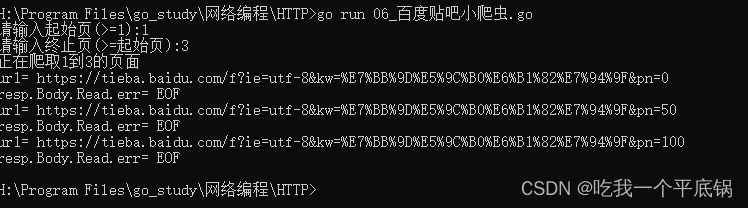
- 经过测试,并发版的爬虫效率要高很多。