
文章链接:https://arxiv.org/abs/2407.06842
项目地址:https://sk-fun.fun/CE3D/
代码:https://github.com/Fangkang515/CE3D/tree/main
引言
过去的3D场景编辑方法往往局限于固定的文本输入模式和有限的编辑能力。用户需要学习特定的命令或特定的多模态模型来实现所需的效果。而且,这些方法通常只能进行简单的编辑,难以实现复杂的场景变换。然而实际应用中,用户的语言是及其丰富的,用户的编辑需要也是多种多样的,当前的方法的设计范式均无法满足用户的诉求。
为了突破这些限制,本文提出了一种全新的3D场景编辑新范式—CE3D。该方法基于大规模语言模型,通过解耦2D编辑和3D重建过程,实现了灵活且高效的任意模型的集成,大大丰富了文本对话能力和场景编辑能力。
什么是CE3D?
CE3D,即Chat-Edit-3D,对话式3D场景编辑的突破。它的核心思想是通过大规模语言模型解析用户的任意文本输入,并自主调用相应的视觉模型来完成3D场景的编辑。为了实现任意视觉模型的集成,CE3D设计了名为Hash-Atlas的映射网络,将3D场景的编辑转换为2D图集空间内的操作,从而实现了2D编辑与3D重建过程的完全解耦,从此无需再指定固定的3D表示形式和2D编辑方法。
文章主要贡献如下:
Hash-Atlas映射网络:通过将3D场景的编辑转化为2D图集的操作,避免了传统管道架构中的3D模型和2D模型间复杂耦合的问题。
对话框架:借助大规模语言模型,CE3D能够解析用户文本输入,生成相应的响应,并管理多种视觉模型和场景文件。
实验结果:CE3D展示了强大的扩展性,兼容各种现有的2D和3D视觉模型,支持多轮对话,并在文本解析、编辑能力和交互自然性方面显著优于以往方法 。
方法
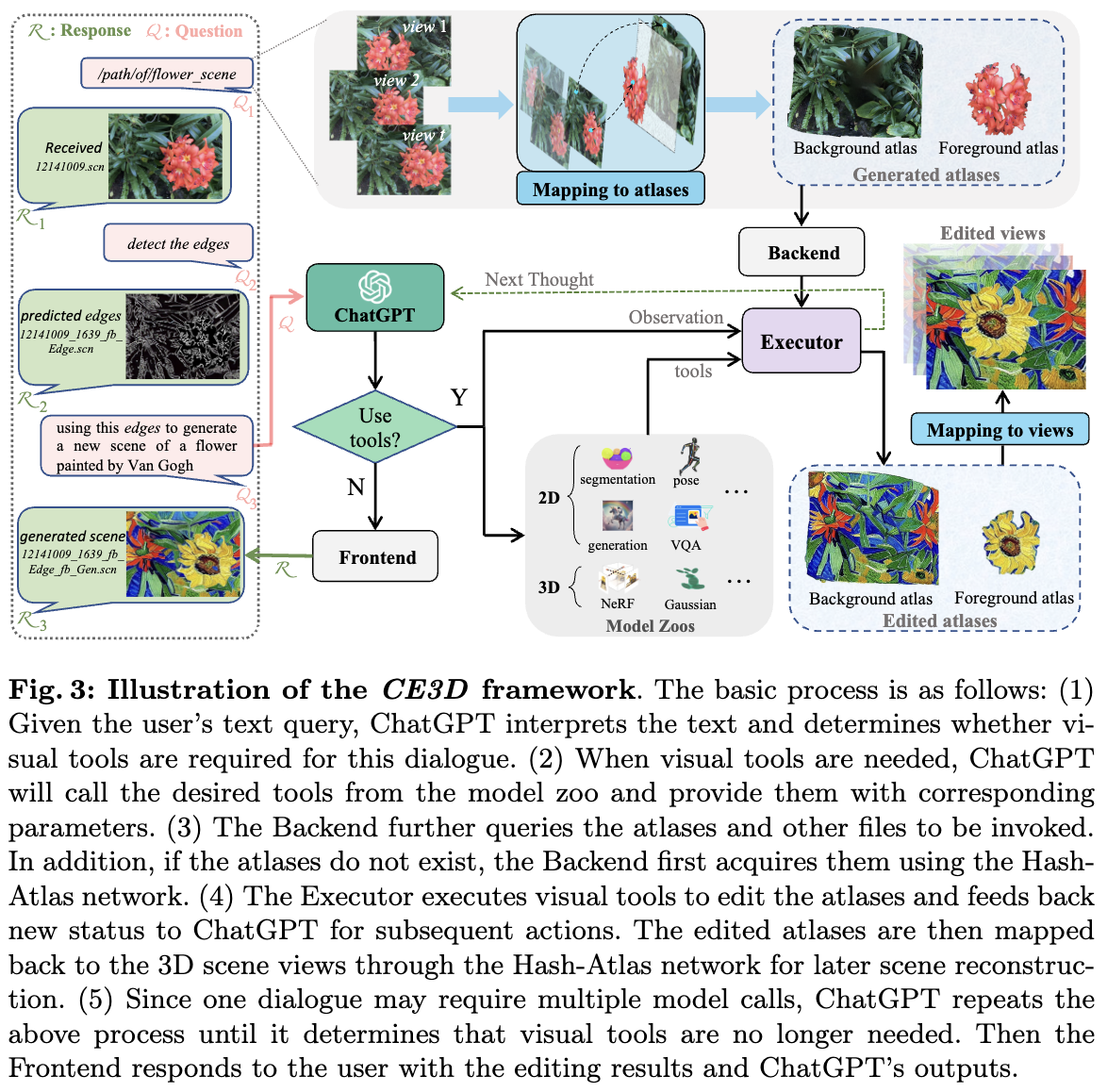
首先说明CE3D 整体pipeline(下图3),然后介绍Hash-Atlas网络的设计、atlas空间中的编辑策略以及CE3D中对话系统的组件。
Hash-Atlas网络
本节介绍了一种简单的方法,将场景的各个视图直接映射到2D图集上,从而将3D场景编辑过程重新定位到2D空间中。类似的技术最初用于将视频帧映射到图集,需要连续帧和平滑的摄像机运动,这与本文中使用的3D场景数据不同。为了实现本文所述的编辑功能,图集应满足以下条件:
防止图集中的过度失真和倾斜,以保持视觉模型的理解。
前景和背景图集应大致对齐,以确保精确编辑。
需要更快且更精确的映射,以促进高效编辑。
Hash-Atlas公式
为了满足上述条件,设计了一个基于哈希结构的网络,如下图4所示。
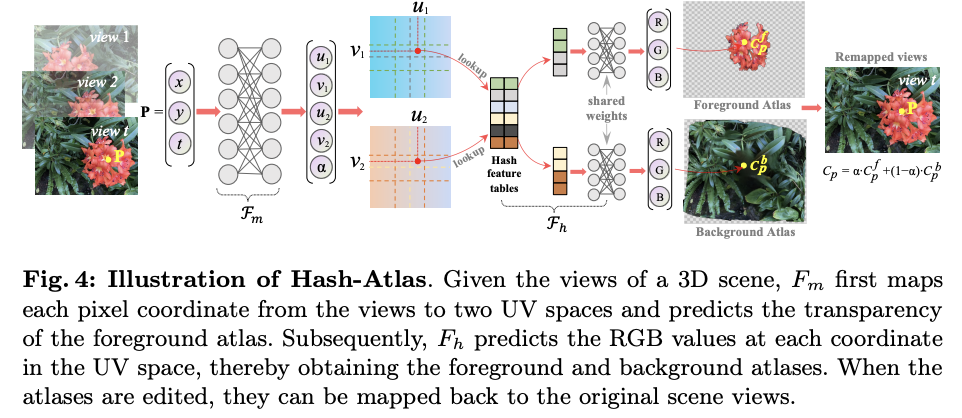
假设场景中有T个视图,则-th视图中的点使用函数映射到两个不同的UV坐标。
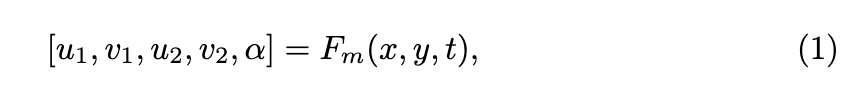
其中 和 代表两个UV空间中的坐标。参数 的范围在 0 到 1 之间,表示前景图集中像素值的权重。然后使用 预测前景和背景图集中在UV坐标下对应的RGB值:
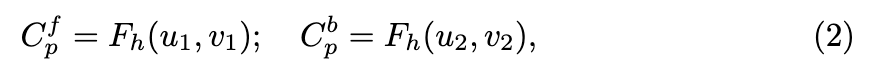
其中, 结合了哈希结构来捕捉图像中的纹理细节,并实现更快的模型训练和推理。此外,为了共享 的权重, 被安排在 [0, 0.5] 区间,而 则在 [0.5, 1] 区间。
在图集中获得像素值 和 后,可以按如下方式重建点 P 在场景视图中的原始像素值:
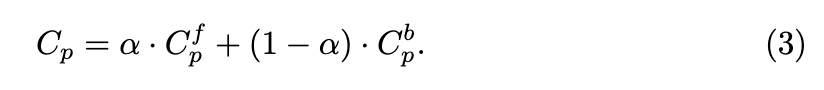
当图集被编辑后,通过方程3可以在不重新训练Hash-Atlas网络的情况下恢复3D场景每个视图的编辑效果。
训练和损失项
为了确保获得的图集看起来更自然,避免物体过度倾斜和变形,在模型训练的早期阶段,研究者们仅使用-th视图中的 。然后,预训练位置损失定义如下:
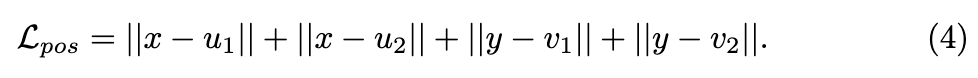
这种损失鼓励在坐标映射后-th视图中场景位置的最小变化。
此外,的预训练涉及通过VQA模型确定场景的前景,并通过分割模型 确定其相应的mask。假设点P的前景mask为,的预训练损失定义如下:
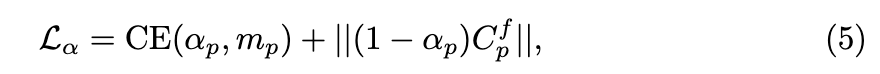
其中,CE表示交叉熵损失。第二项鼓励α和前景图集稀疏,这有助于前景和背景图集内容的明确分离。
完成预训练后,可以通过监督从图集重建视图来训练整个模型。然而,观察到这种训练会导致背景图集中出现明显的区域遗漏,这对后续的编辑任务产生负面影响。为了解决这个问题,引入了修复损失。首先,使用ProPainter模型对被遮挡的背景进行初步修复,生成一组新的修复视图。假设原始视图中的点P对应于修复视图中的,重建损失可以表示如下:
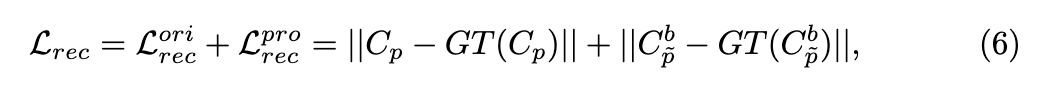
其中,GT(·) 表示从场景的原始或修复视图中获得的真实值。此外,按照 [26] 的方法,在场景中加入刚性和流约束。 的目的是保持不同点之间的相对空间位置不发生剧烈变化。同时, 鼓励将不同视图中的对应点映射到图集中的相同位置。因此,总损失可以表示如下:

在图集空间中编辑
本文发现,直接编辑两个图集然后将它们映射回场景视图通常不会产生令人满意的编辑结果。这主要是因为单个图集包含的场景信息不完整,特别是在稀疏的前景图集中。这种限制使得编辑模型无法获取完整的场景语义,从而始终无法实现可靠的编辑。因此,设计了一种用于编辑图集的合并-拆分策略。在此过程中,利用ChatGPT的解析能力和VQA模型来识别编辑区域。如果这些区域涉及前景内容,我们将前景图集覆盖在背景图集上,并将其作为实际的编辑图集。随后,使用原始前景mask和新对象mask来分离编辑后的图集。用“执行器”来表示实际的编辑过程,如前面图3所示。
对话系统
对场景名称的敏感度
作为一种语言模型,ChatGPT无法直接访问文本以外的信息。然而,考虑到编辑过程中涉及的大量文件,将所有这些文件作为文本输入到ChatGPT中是不现实的。因此,用格式为‘xxx.scn’的单个字符串来表示所涉及的文件。这个字符串是唯一且无意义的,以防止ChatGPT捏造场景名称。尽管这个场景名称并不是一个真正可读的文件,但通过前端和后端的进一步处理,CE3D可以有效地处理真实文件。前端将编辑结果和ChatGPT的输出组织成用户回复,而后端则分发编辑过程中涉及的真实场景文件,并管理新场景的名称和文件。
用户查询的推理
在面对用户输入时,ChatGPT模拟一个思考过程:“我需要使用视觉工具吗?”→“我需要哪些工具?”→“这些工具的具体输入应该是什么?”。因此,预先向ChatGPT注入每个视觉专家的信息以完成这个推理过程是至关重要的。类似于[62, 66],将每个视觉工具标注为四个类别:工具名称、在什么情况下使用、所需参数和具体输入示例。
编辑能力展示
在多轮对话编辑案例中,CE3D能够处理各种类型的编辑请求,例如精准对象移除或替换、基于文本或图像的风格迁移、深度图预测、基于文本和深度图条件的场景再生、人体Pose预测、场景超分、场景分割等。此外,它还可以完成与场景相关的视觉问答任务和基本的文本对话。总之,因为能任意扩展视觉模型,因此编辑能力无上限!

未来展望
虽然CE3D在3D场景编辑方面取得了显著进展,但研究人员表示,这项技术仍有改进空间。例如,在处理360度全景场景时可能会遇到一些挑战,还有进一步研究的空间。

参考文献
[1]Chat-Edit-3D: Interactive 3D Scene Editing via Text Prompts







































![[ACTF2020 新生赛]Include1](https://i-blog.csdnimg.cn/direct/56f4e863e6934d9db7803ea0798e7a15.png)