Redis⑥ —— 缓存设计
- 开发
- 22
-
1. 缓存雪崩
- Redis会设置过期时间来保证缓存中的数据与数据库的数据一致性,当大量缓存数据在同一时间过期或Redis故障宕机,如果此时有大量用户请求都无法在Redis中处理,会直接全部请求访问数据库,导致压力骤增,从而形成一系列连锁反应造成整个系统崩溃
1.1 原因一:大量数据同时过期
- 均匀设置过期时间
- 可以在对缓存数据设置过期时间时,给这些数据的过期时间加上一个随机数,这样就保证数据不会在同一时间过期。
- 互斥锁
- 当业务线程在处理用户请求时,如果发现访问的数据不在 Redis 里,就加个互斥锁,保证同一时间内只有一个请求来构建缓存,当缓存构建完成后,再释放锁。
- 后台更新缓存
- 业务线程不再负责更新缓存,缓存也不设置有效期,而是让缓存“永久有效”,并将更新缓存的工作交由后台线程定时更新。
- 缓存数据不设置有效期,并不是意味着数据一直能在内存里,因为当系统内存紧张的时候,有些缓存数据会被“淘汰”,而在缓存被“淘汰”到下一次后台定时更新缓存的这段时间内,业务线程读取缓存失败就返回空值,业务的视角就以为是数据丢失了。
- 解决方法一:后台线程不仅负责定时更新缓存,而且也负责频繁地检测缓存是否有效
- 解决方法二:在业务线程发现缓存数据失效后(缓存数据被淘汰),通过消息队列发送一条消息通知后台线程更新缓存
- 在业务刚上线的时候,我们最好提前把数据缓起来,而不是等待用户访问才来触发缓存构建,这就是所谓的缓存预热,后台更新缓存的机制刚好也适合干这个事情
1.2 原因二:Redis故障宕机
- 服务熔断或请求限流机制
- 启动服务熔断机制,暂停业务应用对缓存服务的访问,直接返回错误,不用再继续访问数据库,从而降低对数据库的访问压力
- 启用请求限流机制,只将少部分请求发送到数据库进行处理,再多的请求就在入口直接拒绝服务,等到 Redis 恢复正常并把缓存预热完后,再解除请求限流的机制。
- 构建Redis缓存高可靠集群
2. 缓存击穿
- 缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮
- 缓存击穿是缓存雪崩的一个子集
- 解决方法:
- 互斥锁
- 不给热点数据设置过期时间,由后台异步更新缓存 或 在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间
3. 缓存穿透
- 当用户访问的数据,既不在缓存中,也不在数据库中,没办法构建缓存数据,来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增。造成缓存穿透
- 原因:
3.1 非法请求的限制
- 当有大量恶意请求访问不存在的数据的时候,也会发生缓存穿透,因此在 API 入口处我们要判断求请求参数是否合理,请求参数是否含有非法值、请求字段是否存在
3.2 缓存空值或默认值
- 可以针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
3.3 使用布隆过滤器快速判断数据是否存在
- 即使发生了缓存穿透,大量请求只会查询 Redis 和布隆过滤器,而不会查询数据库,保证了数据库能正常运行,Redis 自身也是支持布隆过滤器的。
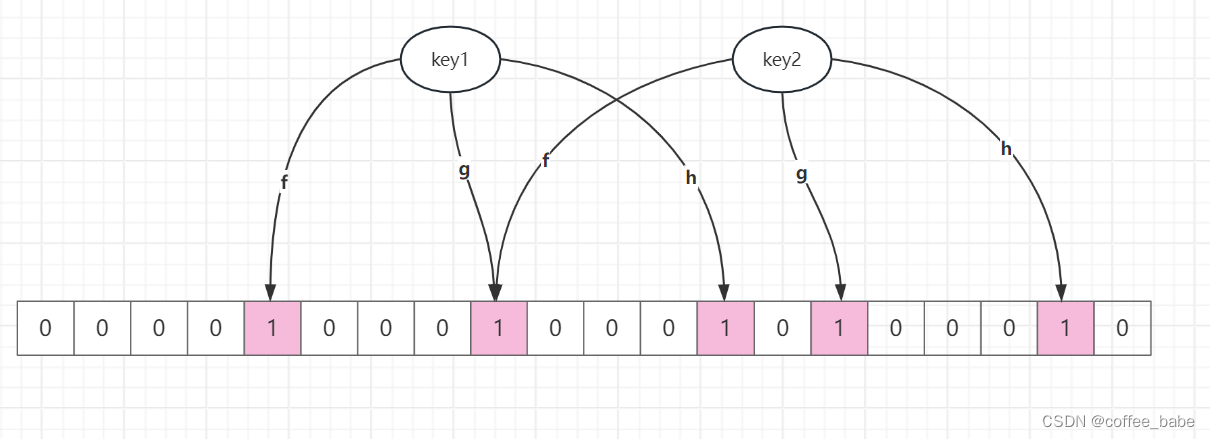
- 布隆过滤器由「初始值都为 0 的位图数组」和「 N 个哈希函数」两部分组成。查询布隆过滤器说数据存在,并不一定证明数据库中存在这个数据,但是查询到数据不存在,数据库中一定就不存在这个数据
4. 动态缓存热点数据的策略
- 通过数据最新访问时间来做排名,并过滤掉不常访问的数据,只留下经常访问的数据。
- 以电商平台场景中的例子,现在要求只缓存用户经常访问的 Top 1000 的商品
- 先通过缓存系统做一个排序队列(比如存放 1000 个商品),系统会根据商品的访问时间,更新队列信息,越是最近访问的商品排名越靠前;
- 同时系统会定期过滤掉队列中排名最后的 200 个商品,然后再从数据库中随机读取出 200 个商品加入队列中;
- 这样当请求每次到达的时候,会先从队列中获取商品 ID,如果命中,就根据 ID 再从另一个缓存数据结构中读取实际的商品信息,并返回。
5. 缓存更新策略
5.1 Cache Aside(旁路缓存)策略
- 写策略:
- 读策略:
- 如果读取的数据命中了缓存,则直接返回数据;
- 如果读取的数据没有命中缓存,则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户
- Cache Aside 策略适合读多写少的场景,不适合写多的场景,因为当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。
5.2 Read/Write Through(读穿 / 写穿)策略
- 应用程序只和缓存交互,不再和数据库交互,而是由缓存和数据库交互,相当于更新数据库的操作由缓存自己代理了
- read through策略:
- 先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库查询数据,并将结果写入到缓存组件,最后缓存组件将数据返回给应用
- write through策略:
- 当有数据更新的时候,先查询要写入的数据在缓存中是否已经存在:
- 如果缓存中数据已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,然后缓存组件告知应用程序更新完成。
- 如果缓存中数据不存在,直接更新数据库,然后返回;
- 特点是由缓存节点而非应用程序来和数据库打交道
5.3 Write Back(写回)策略(Redis不适用,不能异步更新数据库)
- 在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通过批量异步更新的方式进行。
- Write Back 策略特别适合写多的场景,因为发生写操作的时候, 只需要更新缓存,就立马返回了。
- 问题是数据不是强一致性的,而且会有数据丢失的风险
原文地址:https://blog.csdn.net/qq_51148151/article/details/140458237
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1813371042199113728.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!