需要注意的是
1. docker
run之后进入docker
sudo docker run --gpus=all -p 10098:10095 -it --privileged=true \
-v $PWD/funasr-runtime-resources/models:/workspace/models \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-gpu-0.1.1会进入虚拟机的root账户,不要退出,在其中启动服务即可
cd FunASR/runtime
nohup bash run_server.sh \
--download-model-dir /workspace/models \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch \
--punc-dir damo/punc_ct-transformer_cn-en-common-vocab471067-large-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
--hotword /workspace/models/hotwords.txt > log.txt 2>&1 &
***服务首次启动时会导出torchscript模型,耗时较长,请耐心等待***
# 如果您想关闭ssl,增加参数:--certfile 0
# 默认加载时间戳模型,如果您想使用nn热词模型进行部署,请设置--model-dir为对应模型:
# damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch(时间戳)
# damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404(nn热词)
# 如果您想在服务端加载热词,请在宿主机文件./funasr-runtime-resources/models/hotwords.txt配置热词(docker映射地址为/workspace/models/hotwords.txt):
# 每行一个热词,格式(热词 权重):阿里巴巴 20(注:热词理论上无限制,但为了兼顾性能和效果,建议热词长度不超过10,个数不超过1k,权重1~100)2. 端口
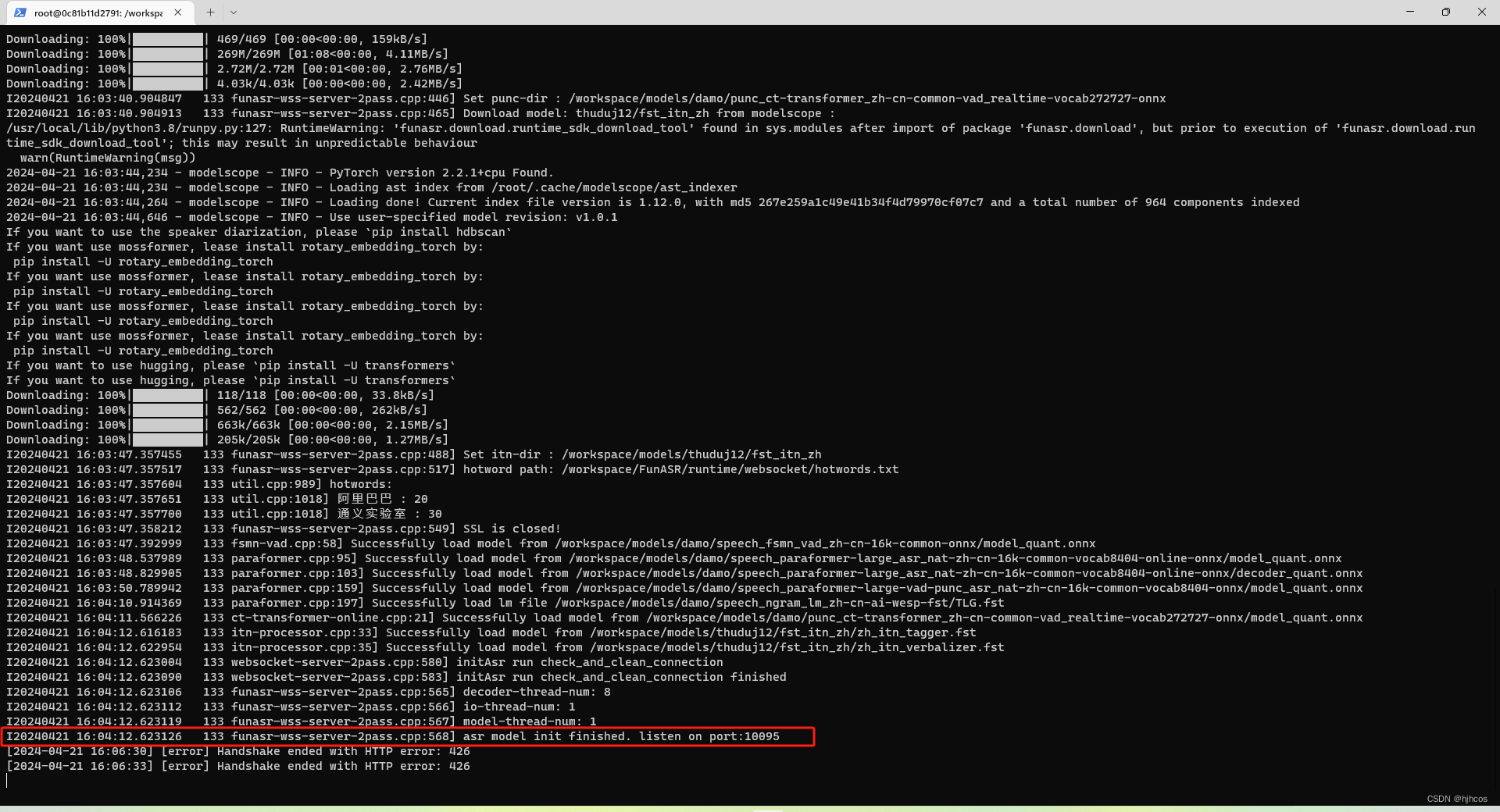
重新开一个窗口,不在虚拟机里了
python3 funasr_wss_client.py --host "127.0.0.1" --port 10095 --mode offline --audio_in "../audio/asr_example.wav"可能报端口错误
ps aux|grep 10095可以看到其实映射的是10098端口,所有测试端口改为该端口即可
3. html
在本地浏览器中输入
file:///home/yuan/zhao/FunASR/samples/html/static/index.html#会进入,asr地址填写刚才的端口
wss://localhost:10098可以选择文件为mp4的,也可以选择wav的,中间可能有授权的东西,多试试
参考
FunASR/runtime/docs/SDK_advanced_guide_offline_gpu_zh.md at main · modelscope/FunASR · GitHub



![[开源]<span style='color:red;'>GPT</span> Boss – 用图形化<span style='color:red;'>的</span>方式<span style='color:red;'>部署</span>您<span style='color:red;'>的</span>私人<span style='color:red;'>GPT</span>镜像网站](https://img-blog.csdnimg.cn/direct/b37ea7bc78a447fbb13f3fd305ac5509.png#pic_center)































