帮up宣传一下,优质up值得信赖!
文章目录
理论知识
https://huggingface.co/docs/accelerate/usage_guides/deepspeed
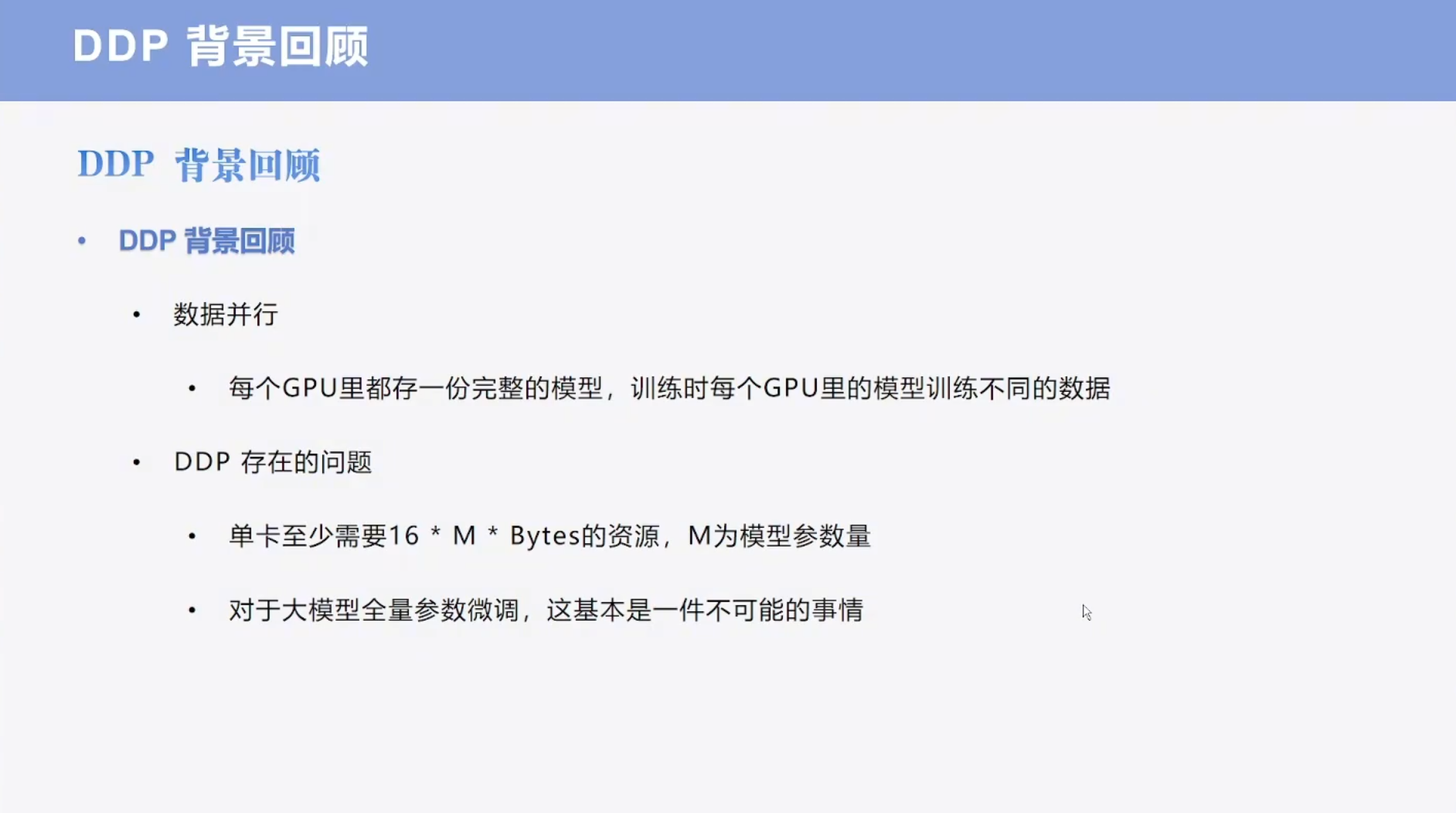
DP&DDP
Deepspeed
介绍





注意事项

多机多卡

实战
ddp_accelerate.py
- ddp_accelerate.py
import time
import math
import torch
import pandas as pd
from torch.optim import Adam
from accelerate import Accelerator
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.utils.data import random_split
from peft import LoraConfig, get_peft_model
from transformers import BertTokenizer, BertForSequenceClassification
class MyDataset(Dataset):
def __init__(self) -> None:
super().__init__()
self.data = pd.read_csv("./ChnSentiCorp_htl_all.csv")
self.data = self.data.dropna()
def __getitem__(self, index):
return self.data.iloc[index]["review"], self.data.iloc[index]["label"]
def __len__(self):
return len(self.data)
def prepare_dataloader():
dataset = MyDataset()
trainset, validset = random_split(dataset, lengths=[0.9, 0.1], generator=torch.Generator().manual_seed(42))
tokenizer = BertTokenizer.from_pretrained("rbt3")
def collate_func(batch):
texts, labels = [], []
for item in batch:
texts.append(item[0])
labels.append(item[1])
inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")
inputs["labels"] = torch.tensor(labels)
return inputs
trainloader = DataLoader(trainset, batch_size=32, collate_fn=collate_func, shuffle=True)
validloader = DataLoader(validset, batch_size=64, collate_fn=collate_func, shuffle=False)
return trainloader, validloader
def prepare_model_and_optimizer():
model = BertForSequenceClassification.from_pretrained("rbt3")
lora_config = LoraConfig(target_modules=["query", "key", "value"])
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
optimizer = Adam(model.parameters(), lr=2e-5, weight_decay=0.001)
return model, optimizer
def evaluate(model, validloader, accelerator: Accelerator):
model.eval()
acc_num = 0
with torch.no_grad():
for batch in validloader:
output = model(**batch)
pred = torch.argmax(output.logits, dim=-1)
pred, refs = accelerator.gather_for_metrics((pred, batch["labels"]))
acc_num += (pred.long() == refs.long()).float().sum()
return acc_num / len(validloader.dataset)
def train(model, optimizer, trainloader, validloader, accelerator: Accelerator, resume, epoch=3, log_step=10):
global_step = 0
start_time = time.time()
resume_step = 0
resume_epoch = 0
if resume is not None:
accelerator.load_state(resume)
steps_per_epoch = math.ceil(len(trainloader) / accelerator.gradient_accumulation_steps)
resume_step = global_step = int(resume.split("step_")[-1])
resume_epoch = resume_step // steps_per_epoch
resume_step -= resume_epoch * steps_per_epoch
accelerator.print(f"resume from checkpoint -> {resume}")
for ep in range(resume_epoch, epoch):
model.train()
if resume and ep == resume_epoch and resume_step != 0:
active_dataloader = accelerator.skip_first_batches(trainloader, resume_step * accelerator.gradient_accumulation_steps)
else:
active_dataloader = trainloader
for batch in active_dataloader:
with accelerator.accumulate(model):
optimizer.zero_grad()
output = model(**batch)
loss = output.loss
accelerator.backward(loss)
optimizer.step()
if accelerator.sync_gradients:
global_step += 1
if global_step % log_step == 0:
loss = accelerator.reduce(loss, "mean")
accelerator.print(f"ep: {ep}, global_step: {global_step}, loss: {loss.item()}")
accelerator.log({"loss": loss.item()}, global_step)
if global_step % 50 == 0 and global_step != 0:
accelerator.print(f"save checkpoint -> step_{global_step}")
accelerator.save_state(accelerator.project_dir + f"/step_{global_step}")
accelerator.unwrap_model(model).save_pretrained(
save_directory=accelerator.project_dir + f"/step_{global_step}/model",
is_main_process=accelerator.is_main_process,
state_dict=accelerator.get_state_dict(model),
save_func=accelerator.save
)
acc = evaluate(model, validloader, accelerator)
accelerator.print(f"ep: {ep}, acc: {acc}, time: {time.time() - start_time}")
accelerator.log({"acc": acc}, global_step)
accelerator.end_training()
def main():
accelerator = Accelerator(log_with="tensorboard", project_dir="ckpts")
accelerator.init_trackers("runs")
trainloader, validloader = prepare_dataloader()
model, optimizer = prepare_model_and_optimizer()
model, optimizer, trainloader, validloader = accelerator.prepare(model, optimizer, trainloader, validloader)
train(model, optimizer, trainloader, validloader, accelerator, resume=None)
if __name__ == "__main__":
main()
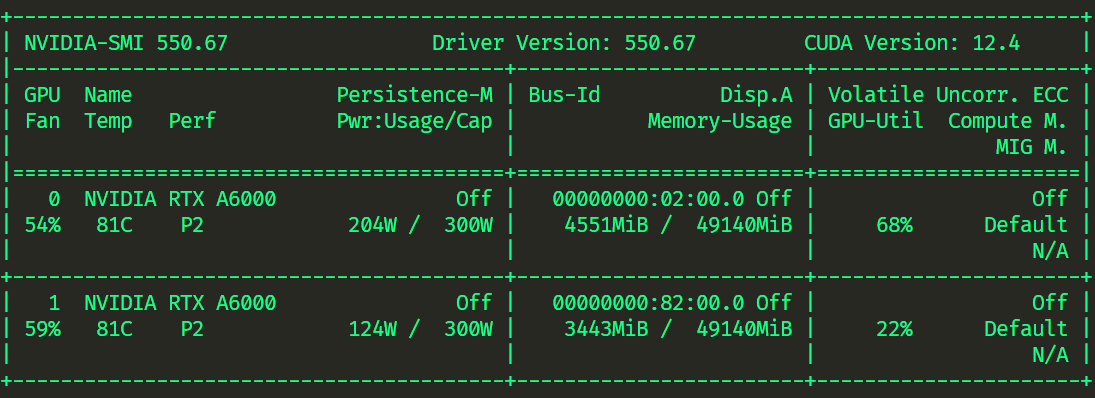
原先显存
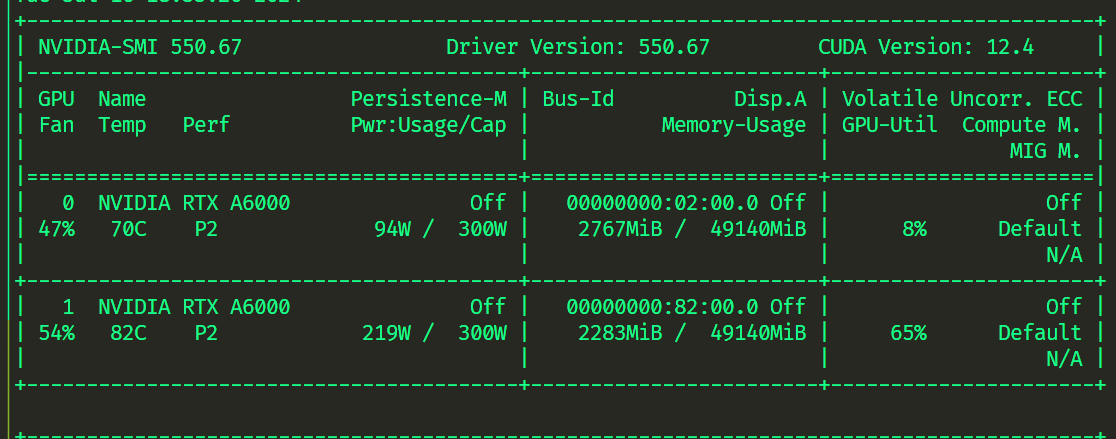
DDP 运行
accelerate launch ddp_accelerate.py
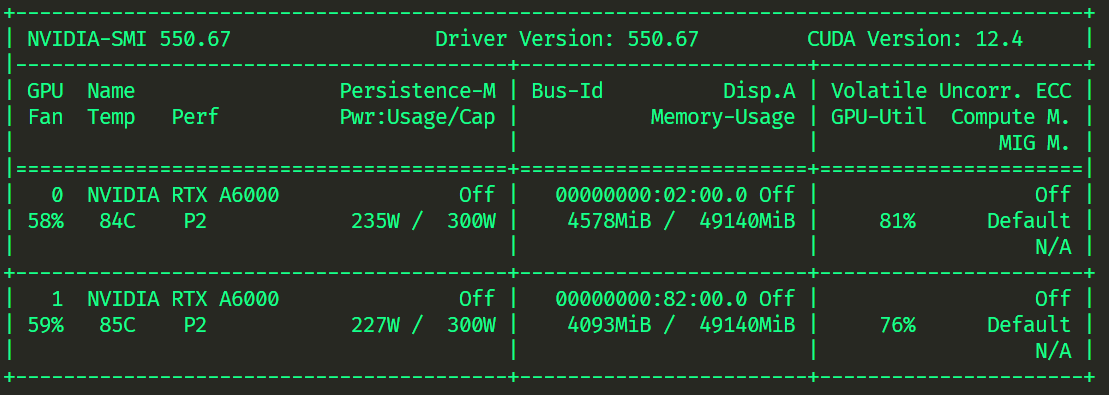
Deepspeed 运行
pip install deepspeed
方式一-zero2
accelerate config

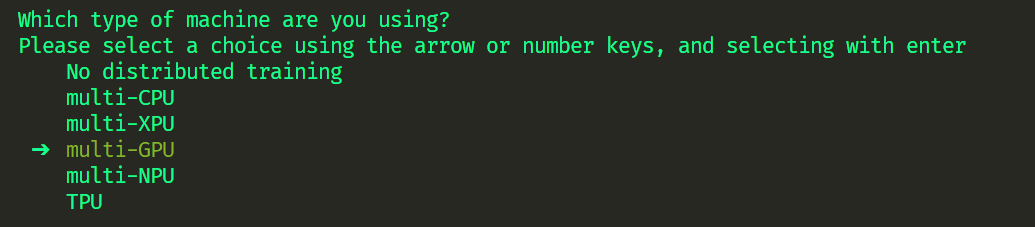


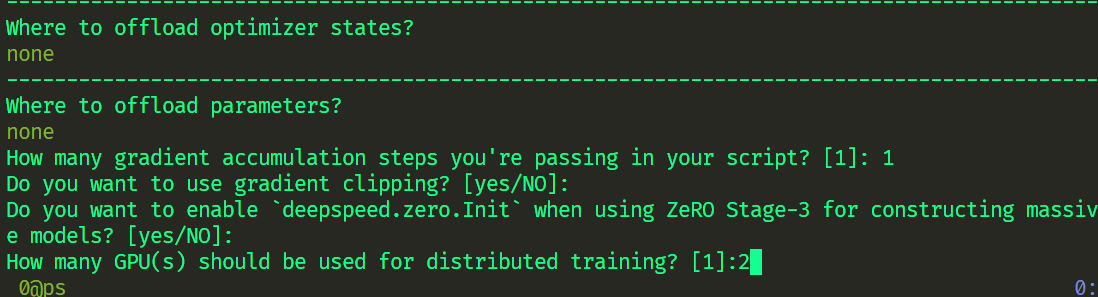
~/.cache/huggingface/accelerate/default_config.yaml
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
gradient_accumulation_steps: 1
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: false
zero_stage: 2
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
- 运行
accelerate launch --config_file default_config.yaml ddp_accelerate.py
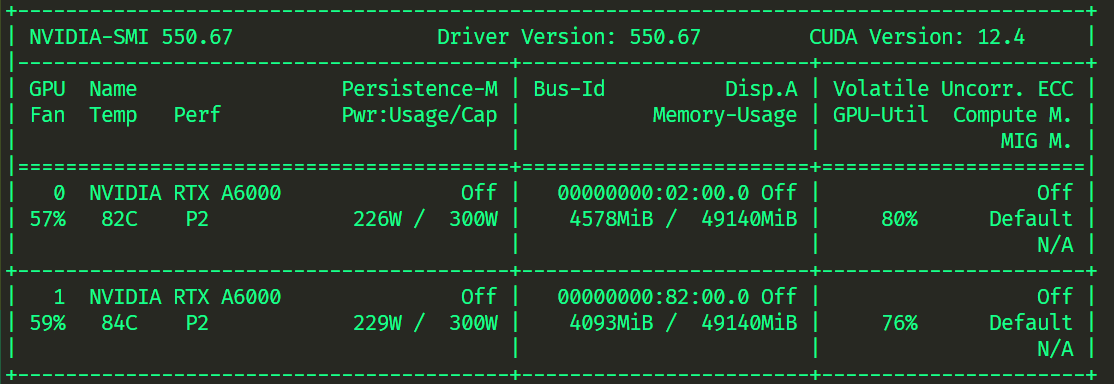
方式二 -zero2
https://huggingface.co/docs/accelerate/usage_guides/deepspeed#deepspeed-config-file
- default_config.yaml
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
# gradient_accumulation_steps: 1
# offload_optimizer_device: none
# offload_param_device: none
# zero3_init_flag: false
# zero_stage: 2
deepspeed_config_file: zero_stage2_config.json
zero3_init_flag: false
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
# mixed_precision: bf16 #注释掉
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
- zero_stage2_config.json
{
"bf16": {
"enabled": true
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": "auto",
"contiguous_gradients": true
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
- 运行
accelerate launch --config_file default_config.yaml ddp_accelerate.py
- mixed_precision: bf16 需要注释掉,否则报错
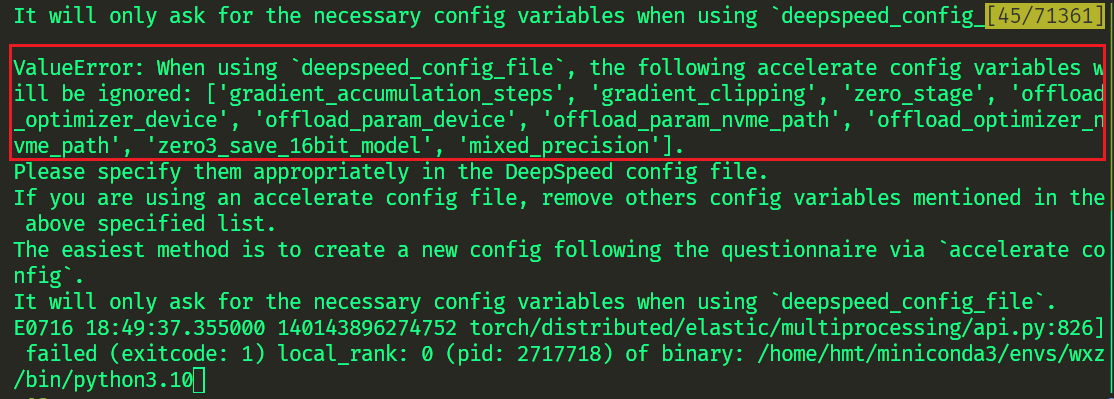
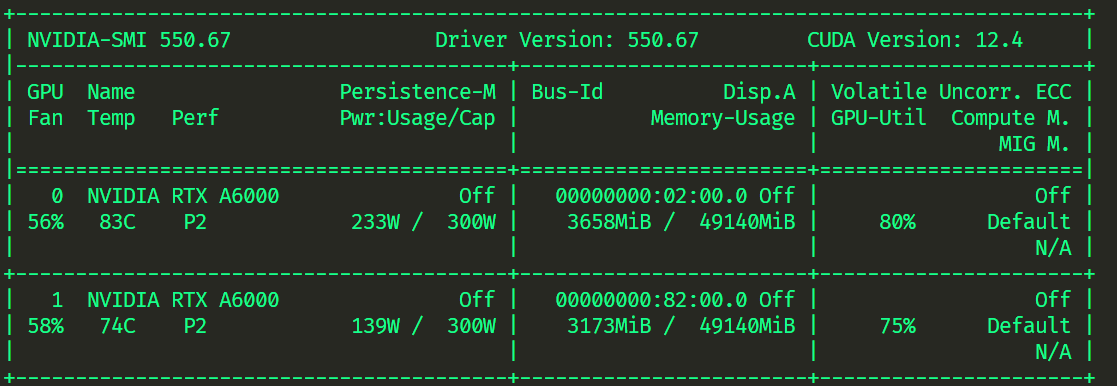
方式一 -zero3
- zero3
- default_config.yaml
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
gradient_accumulation_steps: 1
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: false
zero_stage: 3
zero3_save_16bit_model: true
# deepspeed_config_file: zero_stage2_config.json
# zero3_init_flag: false
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
- 运行
accelerate launch --config_file default_config.yaml ddp_accelerate.py
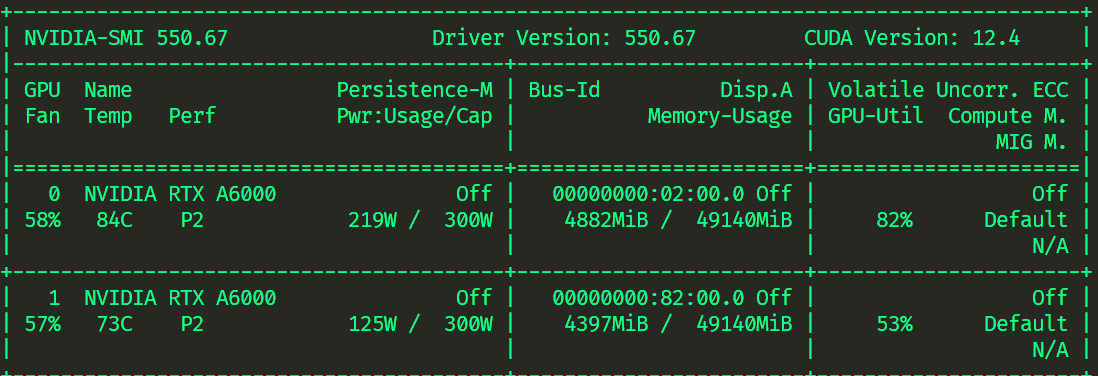
- 不加
zero3_save_16bit_model: true训练正常,保存模型会报错

- 加
zero3_save_16bit_model: true训练正常,保存模型正常,评估会报错
# 评估部分要使用 with torch.no_grad():,而不是with torch.inference_mode():
def evaluate(model, validloader, accelerator: Accelerator):
model.eval()
acc_num = 0
with torch.no_grad():
for batch in validloader:
output = model(**batch)
pred = torch.argmax(output.logits, dim=-1)
pred, refs = accelerator.gather_for_metrics((pred, batch["labels"]))
acc_num += (pred.long() == refs.long()).float().sum()
return acc_num / len(validloader.dataset)
方式二 -zero3
- default_config.yaml
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
# gradient_accumulation_steps: 1
# offload_optimizer_device: none
# offload_param_device: none
# zero3_init_flag: false
# zero_stage: 3
# zero3_save_16bit_model: true
deepspeed_config_file: zero_stage3_config.json
zero3_init_flag: false
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
# mixed_precision: bf16 # 使用accelerate config 记得注释AMP
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
- zero_stage3_config.json
{
"bf16": {
"enabled": true
},
"zero_optimization": {
"stage": 3,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": "auto",
"contiguous_gradients": true,
"stage3_gather_16bit_weights_on_model_save": true # 保存模型
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
- 运行
accelerate launch --config_file default_config.yaml ddp_accelerate.py
ddp_trainer.py
# %% [markdown]
# # 文本分类实例
# %% [markdown]
# ## Step1 导入相关包
# %%
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments, BertTokenizer, BertForSequenceClassification
from datasets import load_dataset
# %% [markdown]
# ## Step2 加载数据集
# %%
dataset = load_dataset("csv", data_files="./ChnSentiCorp_htl_all.csv", split="train")
dataset = dataset.filter(lambda x: x["review"] is not None)
dataset
# %% [markdown]
# ## Step3 划分数据集
# %%
datasets = dataset.train_test_split(test_size=0.1, seed=42)
datasets
# %% [markdown]
# ## Step4 数据集预处理
# %%
import torch
tokenizer = BertTokenizer.from_pretrained("/gemini/code/model")
def process_function(examples):
tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True)
tokenized_examples["labels"] = examples["label"]
return tokenized_examples
tokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
tokenized_datasets
# %% [markdown]
# ## Step5 创建模型
# %%
model = BertForSequenceClassification.from_pretrained("/gemini/code/model")
# %%
model.config
# %% [markdown]
# ## Step6 创建评估函数
# %%
import evaluate
acc_metric = evaluate.load("./metric_accuracy.py")
f1_metirc = evaluate.load("./metric_f1.py")
# %%
def eval_metric(eval_predict):
predictions, labels = eval_predict
predictions = predictions.argmax(axis=-1)
acc = acc_metric.compute(predictions=predictions, references=labels)
f1 = f1_metirc.compute(predictions=predictions, references=labels)
acc.update(f1)
return acc
# %% [markdown]
# ## Step7 创建TrainingArguments
# %%
train_args = TrainingArguments(output_dir="./ckpts", # 输出文件夹
per_device_train_batch_size=32, # 训练时的batch_size
per_device_eval_batch_size=128, # 验证时的batch_size
logging_steps=10, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
bf16=True,
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="f1", # 设定评估指标
load_best_model_at_end=True) # 训练完成后加载最优模型
# %% [markdown]
# ## Step8 创建Trainer
# %%
from transformers import DataCollatorWithPadding
trainer = Trainer(model=model,
args=train_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
compute_metrics=eval_metric)
# %% [markdown]
# ## Step9 模型训练
# %%
trainer.train()
zero2
accelerate launch --config_file default_config.yaml ddp_trainer.py
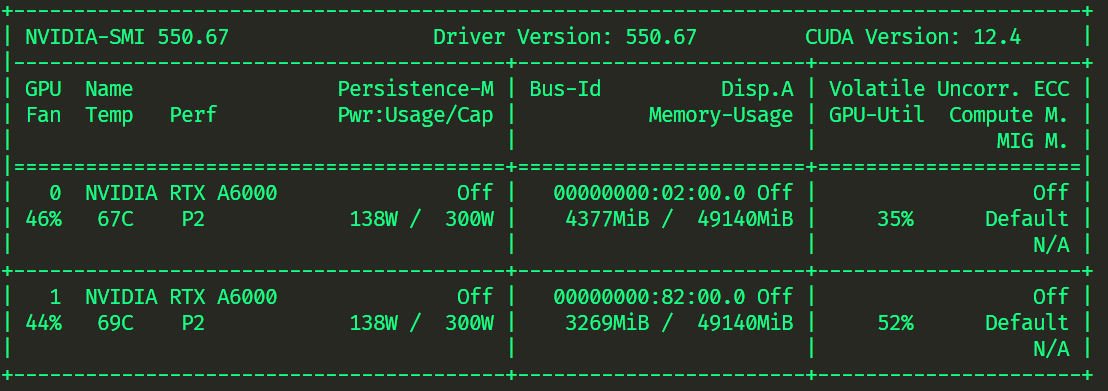
zero3
accelerate launch --config_file default_config.yaml ddp_trainer.py
注意事项
accelerate deepspeed 部分的 config里面的参数(方式一)要和hf trainer中的参数保持一致,否则会报错

- 使用 deepspeed config 文件(方式二)问题同上