🚀一、爬虫需求及其目标网站
目标网站:
https://www.3bqg.cc/book/12257/
需求:爬取小说章节名称及其对应的小说内容,并保存到本地,要求以章节名作为文件名。
🔥二、所需的第三方库及简介
requests
简介:requests模块
官方文档:https://requests.readthedocs.io/projects/cn/zh-cn/latest/
requests 是 Python 编程语言中一个常用的第三方库,它可以帮助我们向 HTTP 服务器发送各种类型的请求,并处理响应。
- 向 Web 服务器发送 GET、POST 等请求方法;
- 在请求中添加自定义标头(headers)、URL 参数、请求体等;
- 自动处理 cookies;
- 返回响应内容,并对其进行解码;
- 处理重定向和跳转等操作;
- 检查响应状态码以及请求所消耗的时间等信息。
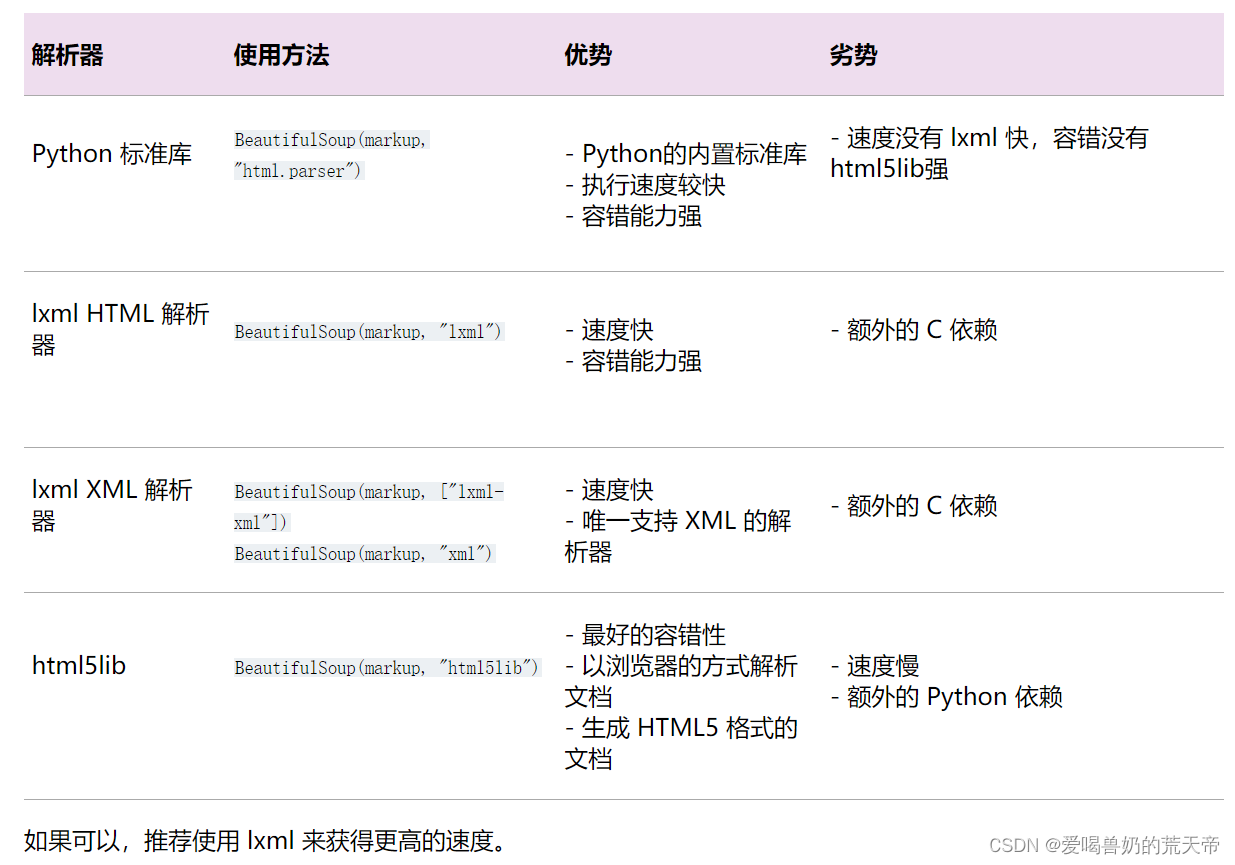
BeautifulSoup
简介:Beautiful Soup(bs4)
Beautiful Soup 是一个 可以从 HTML 或 XML 文件中提取数据的 Python 库。它能用你喜欢的解析器和习惯的方式实现 文档树的导航、查找、和修改。
❤️三、爬虫案例实战
打开网站

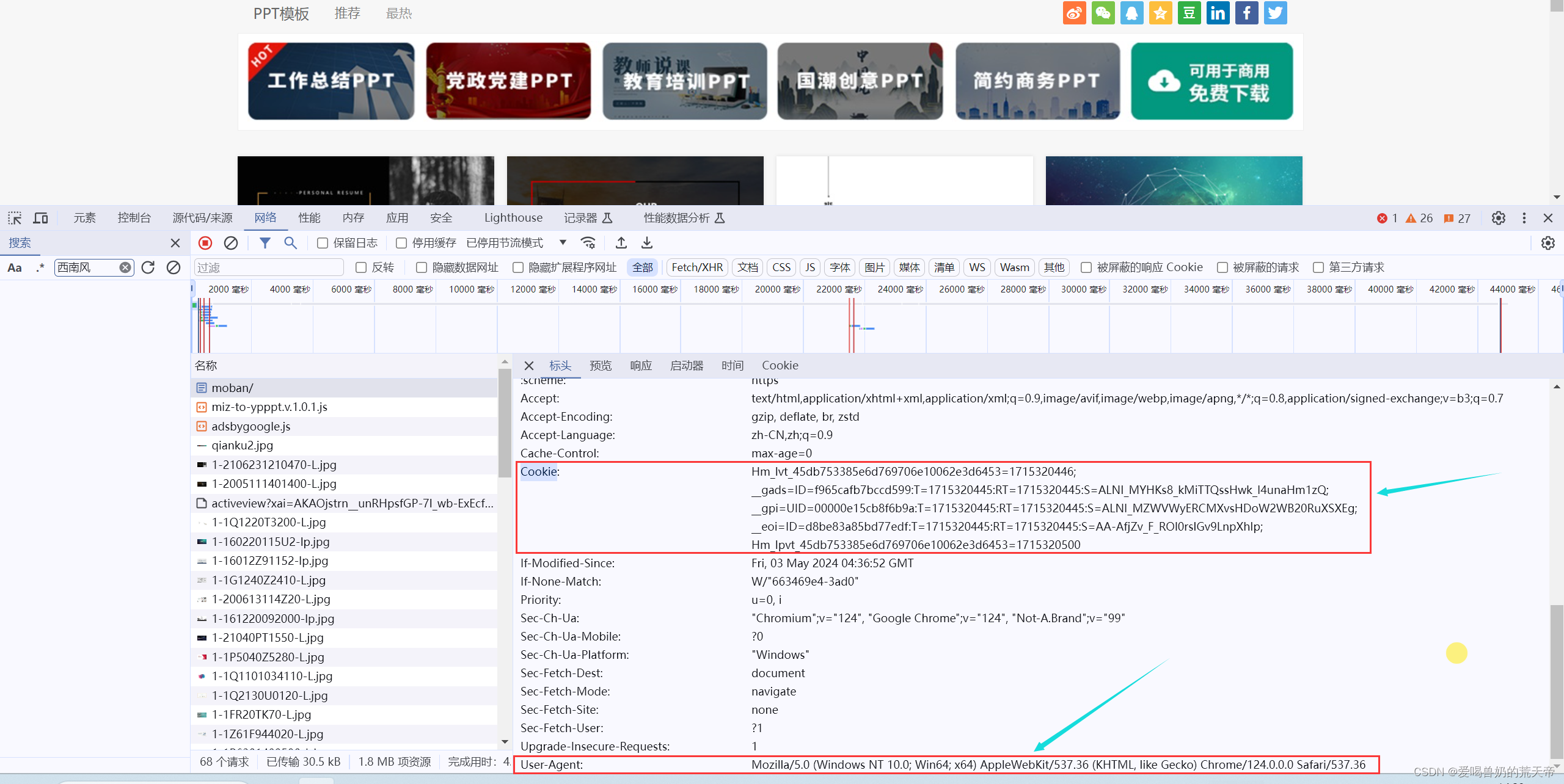
F12进入开发者模式,点击网络,刷新页面后点击搜索框,输入章节名称,就可以找到所需要的数据位于哪个数据包。

点击标头,获取请求网址以及请求方法。请求网址就是我们爬虫所需要的目标网址了,请求可以看到等会儿我们需要用get方法发送请求。

爬虫函数框架
# 导入模块
import requests
from bs4 import BeautifulSoup
import os
import re
# 获取网页源码
def get_html():
pass
# 解析数据
def parse_html():
pass
# 保存数据
def save_data():
pass
# 主函数
def main():
pass
第一步:获取网页源码
获取请求头信息User-Agent,HTTP请求头的一部分,用于标识发送HTTP请求的用户代理(User Agent)。它通常包含了软件应用程序或用户使用的操作系统、浏览器、版本号等信息,让服务器能够识别客户端的类型。
- Mozilla/5.0 表示该软件是Mozilla兼容的,版本号为5.0。
- (Windows NT 10.0; Win64; x64) 表示操作系统是Windows 10的64位版本。
- AppleWebKit/537.36 表示浏览器使用的渲染引擎版本。
- (KHTML, like Gecko) 是针对KHTML(KHTML是Konqueror的渲染引擎)的补充信息,表示浏览器的内核类似于Gecko。
- Chrome/91.0.4472.124 表示浏览器和其版本号。
- Safari/537.36 表示浏览器基于Safari的版本号。
User-Agent的信息有助于网站提供适当的内容或功能给不同类型的客户端,也可以用于统计分析和安全审计等目的。
# 请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 获取网页源码
def get_html(url):
res = requests.get(url, headers=headers)
print(res.text)
# 主函数
def main():
url = 'https://www.3bqg.cc/book/12257/'
get_html(url)
main()

第二步:数据解析
接下来我们就可以利用bs4进行数据筛选,提取。
在获取到网页源码后就可以不需要打印了,可以直接将网页源码作为返回值给返回出来,在parse_html函数中进行数据解析,提取。
# 导入模块
# 获取网页源码
def get_html(url):
res = requests.get(url, headers=headers)
return res.text
# 解析数据
def parse_html(html):
soup = BeautifulSoup(html, 'lxml') # 实例化

可以看到,所有的章节都在dd标签里面,而所有的dd标签又在div标签里面,所以我们可以直接通过id或者class属性对div标签进行精准定位,在通过div标签找到所有包含了章节名的dd标签。
# 解析数据
def parse_html(html):
soup = BeautifulSoup(html, 'lxml')
# 解析目录及其小说详情页
tag_div = soup.find('div', class_='listmain')
tag_dd = tag_div.find_all('dd')
for tag in tag_dd:
print(tag)

打印出来之后可以看到,章节名就在dd标签里面的a标签里面,只需要通过循环dd标签,在dd标签里面一个个找a标签就可以了,然后通过string属性直接获取a标签里面的文本内容。
# 导入模块
import requests
from bs4 import BeautifulSoup
import os
import re
# 请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 获取网页源码
def get_html(url):
res = requests.get(url, headers=headers)
return res.text
# 解析数据
def parse_html(html):
soup = BeautifulSoup(html, 'lxml')
# 解析目录及其小说详情页
tag_div = soup.find('div', class_='listmain')
tag_dd = tag_div.find_all('dd')
for tag in tag_dd:
tag_a = tag.find('a')
title = tag_a.string
print(title)
# 保存数据
def save_data():
pass
# 主函数
def main():
url = 'https://www.3bqg.cc/book/12257/'
html = get_html(url)
parse_html(html)
main()

注意:在获取章节名称是有一个 <<—展开全部章节—>> 是需要去掉的,我们可以直接在循环的时候加一个判断,如果获取到的文本内容等于 <<—展开全部章节—>>就直接跳过本次循环。
另外要注意的一点就是有些章节名上会有一些特殊符号,比如 ?、*、:、"、\、/、| 等等,这些特殊符号都是无法作为文件名的,所以这里最好提前处理一下,比如用正则表达式将这些特殊字符给替换掉。

# 解析数据
def parse_html(html):
soup = BeautifulSoup(html, 'lxml')
# 解析目录及其小说详情页
tag_div = soup.find('div', class_='listmain')
tag_dd = tag_div.find_all('dd')
for tag in tag_dd:
tag_a = tag.find('a')
title = tag_a.string
if title == '<<---展开全部章节--->>':
continue
title = re.sub(r'[?*:"\/|]', '', title) # 用正则表达式替换特殊字符
print(title)

章节名称获取下来之后,接下来就是章节对应的文章内容,仔细观察后可以发现,a标签里面的href属性里面的值就是小说内容的链接的一部分,所以我们想要获取小说内容链接就只需要获取a标签里面的href属性值,在进行拼接一下就可以获取完整链接。
# 解析数据
def parse_html(html):
soup = BeautifulSoup(html, 'lxml')
# 解析目录及其小说详情页
tag_div = soup.find('div', class_='listmain')
tag_dd = tag_div.find_all('dd')
for tag in tag_dd:
tag_a = tag.find('a')
title = tag_a.string
if title == '<<---展开全部章节--->>':
continue
href = 'https://www.3bqg.cc' + tag_a.get('href')
print(title, href)

最后就只需要对面一个链接发送一个请求,获取源码,提取小说文本内容就可以了。

href = 'https://www.3bqg.cc' + tag_a.get('href')
html = get_html(href)
soup1 = BeautifulSoup(html, 'lxml')
tag_div1 = soup1.find('div', id='chaptercontent')
print(tag_div1)

这里获取文本内容不可以直接通过br标签获取,因为这里有些br标签里面是空的,直接通过string属性去获取文本内容会导致报错。这里可以通过stripped_strings, stripped_strings是一个生成器,用于获取去除了首尾空白字符的所有子孙节点的文本内容。将他强转成列表,在通过join方法连接即可得到小说文本内容。
href = 'https://www.3bqg.cc' + tag_a.get('href')
html = get_html(href)
soup1 = BeautifulSoup(html, 'lxml')
tag_div1 = soup1.find('div', id='chaptercontent')
data = list(tag_div1.stripped_strings)
concent = '\n '.join(data)
print(concent)

第三步:数据保存
利用Python的os模块中的mkdir来创建文件夹,注意,在创建文件夹之前一定要判断文件夹是否存在,如果存在就无法创建。
# 保存数据
def save_data(title, concent):
path = '末日乐园'
if not os.path.exists(path):
os.mkdir(path)
with open(f'{path}/{title}.txt', 'w', encoding='utf-8') as f:
f.write(concent)
print(f'{title}章节爬取成功--------------------------------------')

🌈四、爬虫完整代码
# 导入模块
import requests
from bs4 import BeautifulSoup
import os
import re
# 请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 获取网页源码
def get_html(url):
res = requests.get(url, headers=headers)
return res.text
# 保存数据
def save_data(title, concent):
path = '末日乐园'
if not os.path.exists(path):
os.mkdir(path)
with open(f'{path}/{title}.txt', 'w', encoding='utf-8') as f:
f.write(concent)
print(f'{title}章节爬取成功--------------------------------------')
# 解析数据
def parse_html(html):
soup = BeautifulSoup(html, 'lxml')
# 解析目录及其小说详情页
tag_div = soup.find('div', class_='listmain')
tag_dd = tag_div.find_all('dd')
for tag in tag_dd:
tag_a = tag.find('a')
title = tag_a.string
if title == '<<---展开全部章节--->>':
continue
title = re.sub(r'[?*:"\/|]', '', title)
href = 'https://www.3bqg.cc' + tag_a.get('href')
html = get_html(href)
soup1 = BeautifulSoup(html, 'lxml')
tag_div1 = soup1.find('div', id='chaptercontent')
data = list(tag_div1.stripped_strings)
concent = '\n '.join(data)
save_data(title, concent)
# 主函数
def main():
url = 'https://www.3bqg.cc/book/12257/'
html = get_html(url)
parse_html(html)
main()