引言
AI技术的发展历程
人工智能(Artificial Intelligence,AI)作为一门研究模拟、延伸和扩展人类智能的技术,已发展多年。从20世纪中期以来,AI经历了几个主要的发展阶段,每个阶段都有其独特的研究重点和技术突破。
早期AI研究
早期的AI研究主要集中在逻辑推理和符号处理上。研究人员试图通过创建规则和逻辑系统来模拟人类的推理过程。虽然这一时期取得了一些进展,但由于计算能力和数据的限制,这些方法在处理复杂任务时表现不佳。
机器学习的兴起
进入20世纪80年代,随着计算能力的提升和数据量的增加,机器学习(Machine Learning)开始成为AI研究的主要方向。机器学习通过从数据中学习模式和规律,可以在没有明确编程的情况下完成任务。尤其是支持向量机(SVM)和决策树等方法的出现,推动了机器学习的发展。
深度学习的突破
2010年以后,深度学习(Deep Learning)技术的突破使AI研究进入了一个新的阶段。深度学习通过使用多层神经网络,可以在大规模数据上进行训练,极大地提高了模型的性能。深度学习在图像识别、语音识别、自然语言处理等领域取得了显著成果,成为当前AI技术的主流。
当前AI技术的主流应用领域
随着深度学习的广泛应用,AI技术在多个领域得到了实际应用:
- 图像处理:包括人脸识别、图像分类、物体检测等。
- 自然语言处理:包括机器翻译、情感分析、文本生成等。
- 自动驾驶:包括环境感知、路径规划、决策控制等。
- 医疗诊断:包括疾病预测、医学影像分析、个性化治疗等。
在这些应用领域中,Transformer架构作为一种新的深度学习模型,展现出了强大的性能和广泛的应用前景。接下来,我们将详细介绍深度学习的基础知识和Transformer架构的原理及应用。
深度学习基础
神经网络基础
神经元与激活函数
神经网络的基本组成单元是神经元(Neuron),每个神经元接收输入信号,进行加权求和后,通过激活函数(Activation Function)产生输出。常用的激活函数包括:
- Sigmoid函数:将输入映射到0到1之间,适用于输出概率值的情况。
- ReLU函数:当输入大于0时,输出等于输入;当输入小于0时,输出等于0。这种函数可以有效缓解梯度消失问题。
- Tanh函数:将输入映射到-1到1之间,适用于处理有正有负的数据。
神经元的输出可以作为下一层神经元的输入,通过层层传递和计算,神经网络能够学习复杂的模式和特征。
多层感知机与反向传播
多层感知机(Multi-Layer Perceptron,MLP)是最简单的神经网络模型,由输入层、隐藏层和输出层组成。每层中的神经元通过全连接的方式与下一层神经元相连。MLP的训练过程包括前向传播(Forward Propagation)和反向传播(Backpropagation)两个阶段。
- 前向传播:输入数据经过网络各层的计算,得到输出结果。
- 反向传播:通过计算输出结果与真实标签之间的误差,使用梯度下降算法更新网络的权重,以最小化误差。
通过多次迭代训练,MLP能够逐渐逼近最优解,实现对数据的有效学习和预测。
卷积神经网络(CNN)
基本概念与原理
卷积神经网络(Convolutional Neural Network,CNN)是一种专为处理图像数据设计的神经网络。CNN通过卷积操作(Convolution Operation)提取图像中的局部特征,并通过池化操作(Pooling Operation)降低数据维度,提高计算效率。CNN的基本结构包括卷积层、池化层和全连接层。
- 卷积层:使用多个卷积核(Filter)对输入图像进行卷积操作,提取特征图(Feature Map)。
- 池化层:对特征图进行降维操作,常用的池化方式有最大池化(Max Pooling)和平均池化(Average Pooling)。
- 全连接层:将提取的特征输入到全连接层,进行分类或回归任务。
在图像处理中的应用
CNN在图像处理领域取得了显著成果,广泛应用于以下任务:
- 图像分类:将图像分为不同的类别,如手写数字识别(MNIST)和物体分类(ImageNet)。
- 物体检测:在图像中检测并标记物体,如YOLO和Faster R-CNN。
- 图像分割:将图像划分为不同的区域,如U-Net和Mask R-CNN。
随着CNN技术的发展,越来越多的变体模型被提出,不断提升图像处理的精度和效率。
Transformer架构
Transformer的起源与发展
从RNN到Transformer
在自然语言处理(Natural Language Processing,NLP)领域,传统的循环神经网络(Recurrent Neural Network,RNN)由于其序列处理能力,曾被广泛应用于文本生成和机器翻译任务。然而,RNN存在训练时间长、梯度消失和长依赖问题(Long Dependency Problem)。为了克服这些问题,研究人员提出了注意力机制(Attention Mechanism),并在此基础上发展出Transformer架构。
Transformer的基本原理
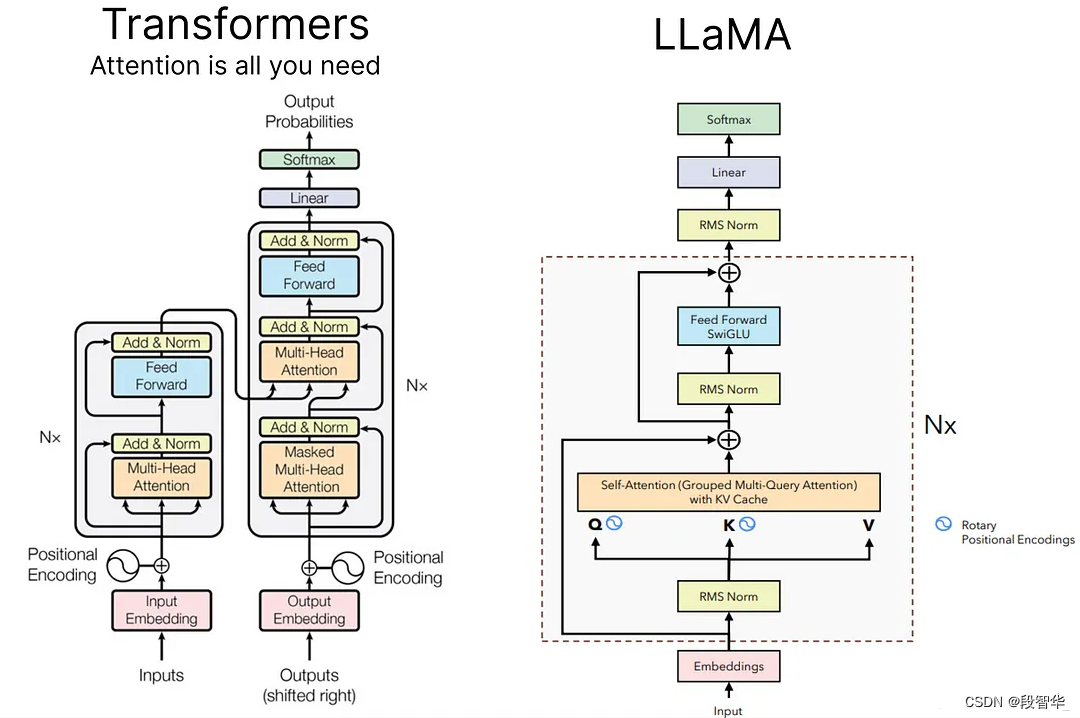
Transformer是一种基于注意力机制的深度学习模型,完全摒弃了RNN结构。Transformer通过自注意力机制(Self-Attention Mechanism)实现对序列数据的并行处理,极大提高了训练效率和模型性能。其核心思想是通过计算序列中每个位置与其他位置之间的相关性,动态调整特征表示,从而捕捉全局信息。
Transformer的结构
自注意力机制
自注意力机制是Transformer的核心组件,通过计算输入序列中每个元素与其他元素之间的注意力权重,动态调整特征表示。具体来说,自注意力机制包括以下步骤:
- 计算查询(Query)、键(Key)和值(Value):输入序列通过三个不同的线性变换层,生成查询、键和值矩阵。
- 计算注意力权重:通过计算查询与键的点积,得到注意力权重矩阵。
- 加权求和:将注意力权重与值矩阵相乘,得到加权后的特征表示。
通过自注意力机制,Transformer能够捕捉输入序列中不同位置之间的依赖关系,实现对全局信息的有效建模。
编码器与解码器
Transformer的整体架构由编码器(Encoder)和解码器(Decoder)组成,每个编码器和解码器都包含多个层叠的子层。
- 编码器:由多层堆叠的自注意力层和前馈神经网络层组成。编码器接收输入序列,通过自注意力机制和前馈神经网络,逐层提取特征表示。
- 解码器:与编码器类似,解码器也由多层堆叠的自注意力层和前馈神经网络层组成。解码器通过接收编码器的输出和目标序列的偏移输入,实现对目标序列的生成。
编码器和解码器的多层堆叠结构,使Transformer具备了强大的表示能力和泛化能力。
最新的Transformer变体
BERT与自然语言处理
BERT的工作原理
BERT(Bidirectional Encoder Representations from Transformers)是由Google提出的一种预训练语言模型,通过在大规模语料上进行双向训练,捕捉上下文信息。BERT的主要特点包括:
- 双向训练:同时考虑输入序列中每个词语的左右上下文信息,获取更为全面的特征表示。
- 遮蔽语言模型:通过遮蔽部分词语,训练模型预测被遮蔽的词语,从而学习词语之间的关系。
在实际应用中的优势
BERT在多个NLP任务中表现出色,如文本分类、命名实体识别、阅读理解等。通过对BERT进行微调(Fine-Tuning),可以在具体任务中取得较好的效果。此外,BERT的预训练模型可以作为其他模型的基础,进一步提升NLP模型的性能。
GPT-3与生成模型
GPT-3的架构与能力
GPT-3(Generative Pre-trained Transformer 3)是OpenAI提出的一种大规模生成模型,通过在海量文本数据上进行无监督训练,具备了强大的生成能力。GPT-3的主要特点包括:
- 大规模参数:拥有1750亿个参数,是目前最大的语言模型之一。
- 零样本学习:无需额外训练数据,GPT-3可以通过提示(Prompt)生成高质量文本。
在文本生成中的表现
GPT-3在文本生成任务中表现出色,能够生成连贯、富有创意的文本内容。其应用范围包括文章撰写、对话系统、代码生成等。GPT-3的生成能力展示了Transformer在文本生成领域的巨大潜力。
Transformer在各领域的应用
自然语言处理
机器翻译
Transformer在机器翻译任务中取得了显著成果,通过编码器-解码器结构,实现了高质量的翻译效果。著名的Transformer翻译模型包括Google的Transformer和Facebook的Fairseq。
文本摘要
Transformer在文本摘要任务中也表现出色,通过对长文本的全局建模,生成简洁、准确的摘要内容。常用的文本摘要模型包括BERTSUM和PEGASUS。
计算机视觉
图像分类与分割
Transformer在图像分类和分割任务中同样表现出色。ViT(Vision Transformer)是一种将Transformer应用于图像分类的模型,通过将图像划分为固定大小的块,输入到Transformer中进行处理,实现高精度的图像分类。SET(Segmentation Transformer)则将Transformer应用于图像分割任务,通过全局注意力机制,提升分割精度。
视觉问答
视觉问答(Visual Question Answering,VQA)任务需要模型同时理解图像和文本信息,生成正确的回答。Transformer通过跨模态注意力机制,实现对图像和文本的融合表示,在VQA任务中取得了优异的表现。
跨模态学习
文本与图像的融合
Transformer在跨模态学习任务中展示了强大的能力,通过同时处理文本和图像数据,实现对多模态信息的融合表示。典型的跨模态模型包括CLIP(Contrastive Language-Image Pretraining),通过对比学习,实现了图像和文本之间的语义匹配。
多模态模型的应用
多模态模型在实际应用中具有广泛前景,如自动驾驶中的感知系统,通过融合视觉和雷达数据,实现对环境的全面感知。此外,多模态模型在医疗诊断、智能安防等领域也展现了巨大的潜力。
深度学习的最新趋势与挑战
模型压缩与加速
知识蒸馏与剪枝
随着深度学习模型的规模不断扩大,模型压缩与加速技术成为研究热点。知识蒸馏(Knowledge Distillation)通过训练一个小模型(学生模型)模仿大模型(教师模型)的行为,实现模型的压缩。剪枝(Pruning)技术通过移除神经网络中的冗余参数,减少模型的计算量和存储需求。
高效推理技术
高效推理技术包括量化(Quantization)和低秩分解(Low-rank Decomposition)等方法,通过降低模型计算的精度或分解计算矩阵,提升模型的推理速度。这些技术在实际应用中具有重要意义,尤其在移动设备和嵌入式系统中。
公平性与可解释性
模型偏见与公平性问题
深度学习模型在训练过程中可能会学习到数据中的偏见,导致模型在特定群体上的表现不公。为了解决这一问题,研究人员提出了一系列公平性算法,如去偏见训练(Debiasing Training)和公平性评估指标(Fairness Metrics)。
可解释AI技术
随着AI技术在各领域的广泛应用,模型的可解释性(Explainability)成为一个重要研究方向。可解释AI技术通过可视化、特征重要性分析等方法,帮助用户理解模型的决策过程,提高模型的透明度和信任度。
AI伦理与安全
AI在社会中的影响
AI技术在社会中的应用越来越广泛,对人类生活产生了深远影响。然而,AI在应用过程中也带来了诸多伦理和安全问题,如隐私保护、数据安全、自动化失业等。这些问题需要引起广泛关注和讨论,以确保AI技术的可持续发展。
AI伦理的前沿问题
AI伦理的前沿问题包括算法透明度、责任归属、价值观冲突等。研究人员和政策制定者需要共同努力,制定合理的伦理规范和法律法规,确保AI技术的公平、安全和可控。
实践中的Transformer:案例分析
商业应用
推荐系统
Transformer在推荐系统中得到了广泛应用,通过对用户行为数据的全局建模,生成个性化的推荐结果。典型的推荐系统模型包括SASRec和BERT4Rec。
智能客服
智能客服系统通过Transformer实现了高效的对话管理和问题解答。基于Transformer的对话模型如DialoGPT和Meena,可以生成自然、连贯的对话内容,提高用户体验。
科研探索
新药研发
Transformer在新药研发中展现了巨大的潜力,通过对化学分子结构的建模,预测药物的有效性和安全性。DeepChem和ChemBERTa是常用的药物发现模型。
天文数据分析
天文数据分析需要处理大量的观测数据和复杂的模型计算。Transformer通过对天文数据的高效建模和分析,帮助科学家发现新的天体和物理现象。AstroAI和SkyNet是天文数据分析的代表性模型。
结论与未来展望
总结与回顾
Transformer作为一种基于注意力机制的深度学习模型,展现了强大的表示能力和应用潜力。在自然语言处理、计算机视觉、跨模态学习等领域,Transformer取得了显著成果,推动了AI技术的发展。
未来发展方向
未来,Transformer的发展方向包括模型的可扩展性与通用性、与其他技术的融合等。研究人员将继续探索Transformer在更多领域的应用,提升模型的性能和效率。此外,随着AI技术的不断进步,Transformer将在社会和经济中发挥更加重要的作用。
附录
参考文献
- Vaswani, A., et al. (2017). Attention is All You Need. Advances in Neural Information Processing Systems.
- Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
- Brown, T., et al. (2020). Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165.
- Dosovitskiy, A., et al. (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv preprint arXiv:2010.11929.
学习资源
推荐书籍与课程
- Deep Learning by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
- Natural Language Processing with PyTorch by Delip Rao and Brian McMahan
- Coursera: Deep Learning Specialization by Andrew Ng
- Udacity: Natural Language Processing Nanodegree
开源项目与代码库
这篇文章详细介绍了深度学习与Transformer架构的最新进展,涵盖了理论基础、实际应用、最新变体、未来发展等多个方面。希望这篇文章能够对你有所帮助。如果有任何不对之处,请随时告知。
































![二叉搜索树的实现[C++]](https://i-blog.csdnimg.cn/direct/698b703c2b5247cd9324e7cc92b5da8b.gif#pic_center)





