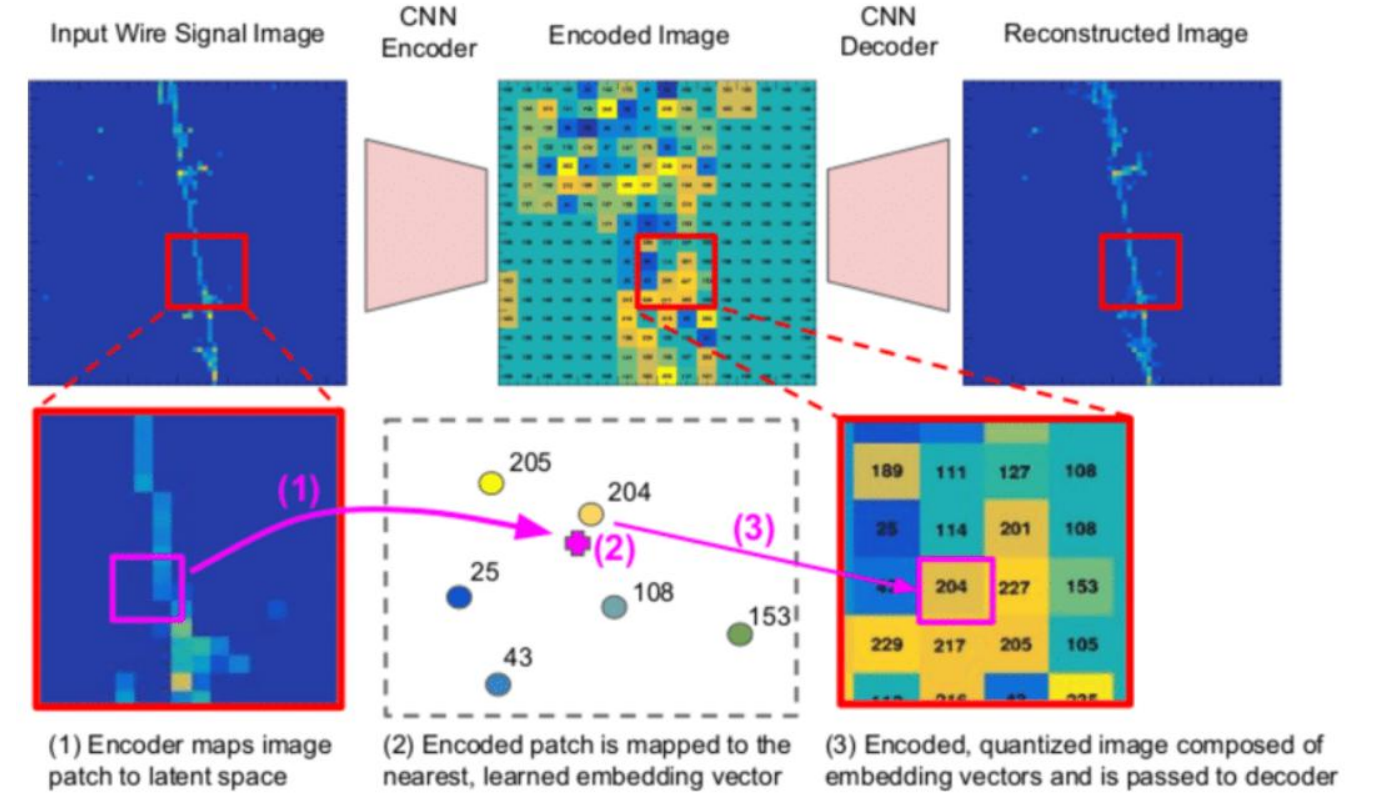
知识图谱和向量库的结合可以实现更强大的知识检索和增强生成(Retrieval-Augmented Generation,RAG)。知识图谱用于捕捉结构化的语义关系,而向量库用于高效的相似性搜索。结合这两者可以构建一个强大的系统,用于知识问答和生成任务。
一、知识图谱和向量库的结合
1. 知识图谱的优点
- 结构化的语义关系
- 易于扩展和查询
- 适合存储和检索复杂的关系
2. 向量库的优点
- 高效的相似性搜索
- 能处理非结构化数据
- 适合存储和检索高维向量
3. 结合的方式
- 知识图谱存储结构化数据:如实体和关系。
- 向量库存储实体或文档的向量表示:如实体的描述或相关文档的向量表示。
- 查询时结合使用:先用向量库进行相似性搜索,再用知识图谱进行语义过滤和关系查询。
二、实现 RAG(Retrieval-Augmented Generation)
RAG 是一种结合检索和生成的技术,用于增强生成模型的回答能力。以下是如何实现 RAG 的步骤:
- 数据准备:构建知识图谱和向量库。
- 检索阶段:从向量库中检索相似的文档或实体。
- 生成阶段:利用检索结果生成回答。
三、示例实现
假设我们有一个知识图谱和一个向量库,知识图谱存储实体和关系,向量库存储实体描述的向量表示。
1. 数据准备
from py2neo import Graph, Node, Relationship
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 连接到 Neo4j 数据库
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password"))
# 清空现有图谱
graph.delete_all()
# 创建实体节点
entities = [
{"name": "Python", "description": "A high-level programming language."},
{"name": "Java", "description": "A high-level, class-based, object-oriented programming language."},
{"name": "Neo4j", "description": "A graph database management system."},
{"name": "TensorFlow", "description": "An end-to-end open source platform for machine learning."}
]
nodes = []
for entity in entities:
node = Node("Entity", name=entity["name"], description=entity["description"])
nodes.append(node)
graph.create(node)
# 构建向量库
descriptions = [entity["description"] for entity in entities]
vectorizer = TfidfVectorizer().fit_transform(descriptions)
vectors = vectorizer.toarray()
# 存储向量和实体映射
entity_to_vector = {entity["name"]: vector for entity, vector in zip(entities, vectors)}
vector_to_entity = {tuple(vector): entity["name"] for entity, vector in zip(entities, vectors)}
2. 检索阶段
def retrieve_similar_entities(query, top_k=3):
query_vector = vectorizer.transform([query]).toarray()
similarities = cosine_similarity(query_vector, vectors).flatten()
top_indices = np.argsort(similarities)[-top_k:][::-1]
return [vector_to_entity[tuple(vectors[i])] for i in top_indices]
# 示例查询
query = "object-oriented programming language"
similar_entities = retrieve_similar_entities(query)
print(f"Similar entities: {similar_entities}")
3. 生成阶段
结合检索结果生成回答,这里我们简单地返回检索到的实体描述。
def generate_answer(query):
similar_entities = retrieve_similar_entities(query)
descriptions = [graph.nodes.match("Entity", name=name).first()["description"] for name in similar_entities]
answer = " ".join(descriptions)
return answer
# 示例查询
query = "object-oriented programming language"
answer = generate_answer(query)
print(f"Answer: {answer}")
四、总结
通过结合知识图谱和向量库,可以实现强大的知识检索和生成系统(RAG)。知识图谱捕捉结构化的语义关系,向量库提供高效的相似性搜索。结合这两者,可以构建一个更智能、更高效的知识库系统,用于问答和生成任务。