接口防刷机制
接口被刷指的是同一接口被频繁调用,可能是由于以下原因导致:
- 恶意攻击:攻击者利用自动化脚本或工具对接口进行大量请求,以消耗系统资源、拖慢系统响应速度或达到其他恶意目的。
- 误操作或程序错误:某些情况下,程序错误或误操作可能导致接口被重复调用,例如循环调用或者定时任务配置错误。
Redis 实现接口防刷
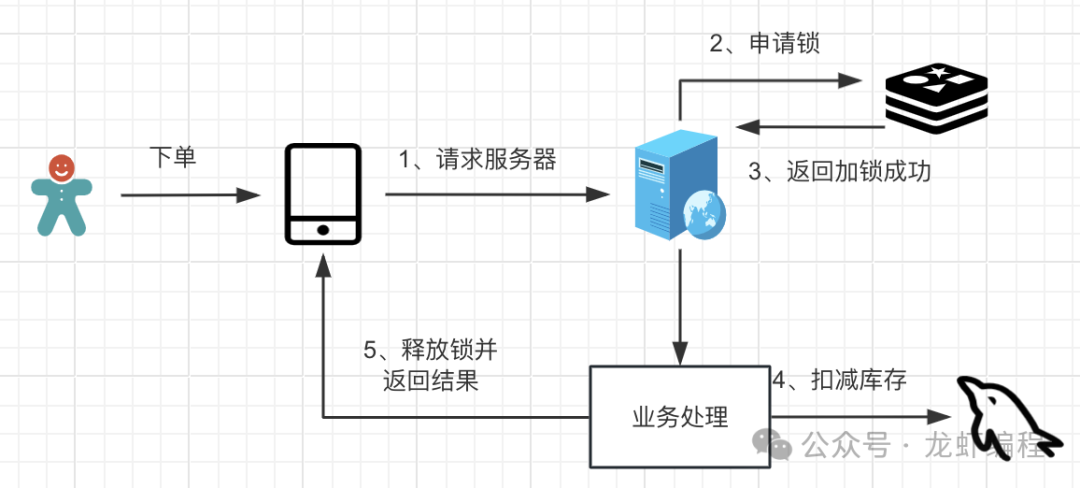
Redis是高性能的键值存储系统,常用于缓存和分布式锁等场景。利用Redis可以有效地实现接口防刷功能:
- 计数器:利用Redis的计数器功能,每次接口被调用时增加计数器的值,设定一个时间窗口内的最大调用次数,超过该次数则拒绝请求。
- 分布式锁:利用Redis的分布式锁功能,确保同一时间只有一个请求能够增加计数器的值,防止并发问题导致计数器失效。
拦截器实现接口防刷
在Spring Boot中,可以通过编写拦截器来实现接口防刷的功能:
- 编写拦截器:创建一个实现HandlerInterceptor接口的拦截器类,重写preHandle方法,在该方法中进行接口调用次数的检查,如果超过阈值则拦截请求。
- 配置拦截器:在Spring Boot的配置类中通过addInterceptor方法将拦截器注册到拦截器链中,配置拦截器的拦截路径和排除路径。
分布式ID生成策略
构建分布式系统时,如何对数据进行唯一标识也是一个至关重要的设计。不仅要符合B-tree数据结构以维持查询性能,还要考虑唯一标识的连续性会不会影响系统安全性。在分库分表的情况下,还要避免唯一标识重复且高效等等需要考虑的点。
1、UUID
UUID(Universally Unique Identifier)是基于当前时间、计数器和硬件标识(通常为无线网卡的MAC地址)等数据计算生成的。UUID完全可以满足分布式唯一标识,但是在实际应用过程中一般不采用,有几个原因:(如果UUID作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。)
- 存储成本高:UUID太长,16字节128位,以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成的UUID算法会暴露MAC地址,曾经梅丽莎病毒的制造者就是根据UUID寻找的。
- 不符合MySQL主键要求:MySQL官方有明确的建议,主键要尽量越短越好,因为太长对MySQL索引不利。
2、数据库自增ID
利用MySQL自增的ID,可以达到数据唯一标识。但是分库分表后不能保证整体的ID唯一。为了避免这种情况,有以下两种方式可以解决该问题。
全局主键表
创建全局主键表维护唯一标识,作为ID的输出源可以保证整体ID的唯一。
ID自增步长设置
通过设置MySQL不同实例的主键自增步长为不同值,让分布在不同实例的表数据ID做到不重复,从而保证整体的唯一。但是这种方式的扩展性会是一个非常大的问题。
3、号段模式
号段模式是当下分布式ID生成器的主流实现方式之一。其原理如下:
- 号段模式每次从数据库取出一个号段范围,加载到服务内存中。避免每次生成ID都去访问数据库。
- 当号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,新的号段范围是(max_id ,max_id +step]。
- 由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新。
这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。但同样也会存在一些缺点,比如:服务器重启,单点故障会造成ID不连续。
4、Redis INCR
作为共享内存,可以通过Redis的INCR命令来生成全局唯一ID。Redis也有对应的缺点:ID 生成的持久化问题,如果Redis宕机了怎么进行恢复是开发人员需要考虑的。
5、雪花算法
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将64bit位分割成了多个部分,每个部分都有具体的不同含义,在Java中64Bit位的整数是Long类型,所以在Java中Snowflake算法生成的ID就是long来存储的。具体如下:

雪花算法强依赖机器时钟,如果机器上时钟回拨,会导致重复。通常通过记录最后使用时间处理该问题。
6、美团(Leaf)
美团点评分布式ID生成系统。支持号段模式和snowflake算法模式,可以切换使用。
开源项目链接:https://github.com/Meituan-Dianping/Leaf
Leaf详细介绍:https://tech.meituan.com/2017/04/21/mt-leaf.html
7、百度(UidGenerator)
UidGenerator是基于Snowflake算法的。克服了雪花算法的并发限制,单个实例的QPS能超过6000000。需要的环境:JDK8+,MySQL(用于分配WorkerId)。
源码地址:https://github.com/baidu/uid-generator
中文文档地址:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
8、滴滴(TinyID)
Tinyid是滴滴基于美团(Leaf)的号段模式基础上升级而来,不仅支持了数据库多主节点模式,还提供了tinyid-client客户端的接入方式,使用起来更加方便。
开源项目链接:https://github.com/didi/tinyid
总结比较
| 优点 | 缺点 | |
|---|---|---|
| UUID | 代码实现简单、没有网络开销,性能好 | 占用空间大、无序 |
| 数据库自增ID | 利用数据库系统的功能实现,成本小、ID自增有序 | 并发性能受Mysql限制、强依赖DB,当DB异常时整个系统不可用,致命 |
| Redis INCR | 性能优于数据库、ID有序 | 解决单点问题带来的数据一致性等问题使得复杂度提高 |
| 雪花算法 | 不依赖数据库等第三方系统,性能也是非高、可以根据自身业务特性分配bit位,非常灵活 | 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。 |
| 号段模式 | 数据库的压力小 | 单点故障ID不连续 |
| Leaf、Uidgenerator、TinyID | 高性能、高可用、接入简单 | 依赖第三方组件如ZooKeeper、Mysql |