前言
本章我们将学习学习认识一下磁盘的的物理结构,理解磁盘分区分块,如何对区块进行管理。学习认识 inode 和软硬连接。。。
目录
1. 文件系统
- 前面我们学到的所有的东西,全部都是在内存中。但是并不是所有的文件都被打开了。
- 大量的文件,就在磁盘上,静静的躺着,这批文件非常多,杂,乱。
- 所以,认识磁盘上的文件管理,是非常有必要的。。
1.1 磁盘的物理结构:
磁盘是我们电脑上的唯一的一个机械设备。目前,我们笔记本上,可能已经不用磁盘了而是 SSD(固态硬盘)。磁盘更加的便宜,公司的服务器大部分都是磁盘式的服务器,SSD的耐用性不如磁盘。

存储数据原理:
磁盘存储数据的原理是基于磁性材料和磁场相互作用的物理过程。在硬盘和磁带等磁介质上,数据以磁场的形式进行存储和读取。
改变N/S极,就是改变了0/1
1.2 IO的基本单位:
- 对于操作系统而言,一次IO的基本单位通常是块(block),通常情况下,一个块的大小等于一个扇区的大小。扇区是磁盘存储的最小单位,一般为512字节或者4KB
- 磁盘访问的基本单位是扇区,不代表磁盘将来就必须以扇区为单位访问。我们可以以多个扇区为单位去访问。
- 虽然磁盘的基本单位是扇区(512字节),但是操作系统和磁盘进行IO的基本单位是:4kB(8 *512字节–Block大小----磁盘:块设备)
为什么通常是4KB呢?
IO基本单位一般选择4KB的原因有几个方面的考虑:
- 存储介质特性:传统硬盘(磁盘)的扇区大小通常是512字节,而一个4KB的块恰好包含了8个扇区。以4KB作为IO基本单位可以更好地匹配硬盘的物理组织结构,减少读取和写入时的寻道开销,提高存储设备的读写效率。
- 缓存效果:较大的块大小有助于提高IO操作的缓存效果。当系统进行IO操作时,会将整个块加载到内存缓存中。较大的块大小可以最大程度地利用内存的缓存能力,减少频繁的磁盘访问,从而提高整体的读写性能。
- 文件系统的块大小:许多文件系统以4KB作为默认的块大小,选择与文件系统块大小一致的IO单位可以更好地与文件系统进行协作。这样可以避免额外的转换和管理开销,提高数据读写的效率。
内存也要以申请4KB的空间来接收。
1.3 文件系统结构:
上述我们讲到,将磁盘看作是一个大的数组,将大数组分块,只要将每一块管理好,那么整个磁盘也就管理到位了.

假设分区有100GB,我们分了20个小组,接下来再分组,分了五个组,所以最后要想把磁盘管好,就要把块组管好,也就是最后把1GB管好(所以,最小的1GB,就是我i们研究的对象)
- Boot Block与开机有关
- 一般计算机在刚开始启动的时候,首先加电自检,然后找主板上的一个设备Base 10 System,它是硬件,里面大概有五百多字节的存储空间,里面就存储了磁盘设备,当它启动之后一定要去找计算机里面,操作系统在什么地方,所以它启动之后一定要读取一个分区里面的Boot Block,这个当中就表明了一个机器的开机信息,包括分区表,同时还告诉我们操作系统中软件在什么地方。
- 所以硬件层面上,系统启动时,读取这一小块数据就可以直接找到操作系统,然后加载操作系统,俗称:开机。
- Linux在磁盘上存储文件的时候,将内容和属性是分开存储的
- 文件的属性是稳定的
- 文件的内容在不断增多
1.4 认识inode:
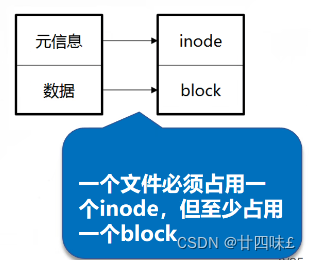
Linux中文件的属性信息(如权限、所有者、大小等)是通过inode来存储和管理的
- 每个文件都有一个唯一的inode号码,用于标识该文件
- inode是文件系统中的一个数据结构,它包含了文件的元数据信息。
- 包括文件的权限、时间戳、大小等
- 当然也有一些文件没有inode



超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,
未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的
时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个
文件系统结构就被破坏了**GDT(Group Descriptor Table):**管理分区内的一个组,有多少inode,起始的inode编号,有多少个inode被使用,有多少block被使用,还剩多少,总的group大小是多少…
Block Bitmap: 标识每个块是否已经被使用了。用比特位的方法,来表示对应的块block是否被占用。用比特位的位置,来表示哪个数据块
inode Bitmap: 用比特位的位置来代表是第几个inode,每个bit表示一个inode是否空闲可用
**inode table:**以128字节为单位,存放文件的属性,如:文件大小、所有者,最近修改时间等
一个分区内,一个inode是具有唯一性的。 一般而言,一个文件,一个inodeData blocks: 以块为单位,进行文件内容的保存!
问题1: 文件名,算文件的属性吗?
答:算的,但是,Inode里面,并不保存文件名!
Linux下,底层实际都是通过inode 编号标识文件的,没有文件概念,
问题2: Linux下一切皆文件,那么目录是文件吗?
答:目录也是文件! 目录的内容是文件名和inode的映射关系,是存储在目录的数据块(data Block)中的
1.5 查看文件的inode:
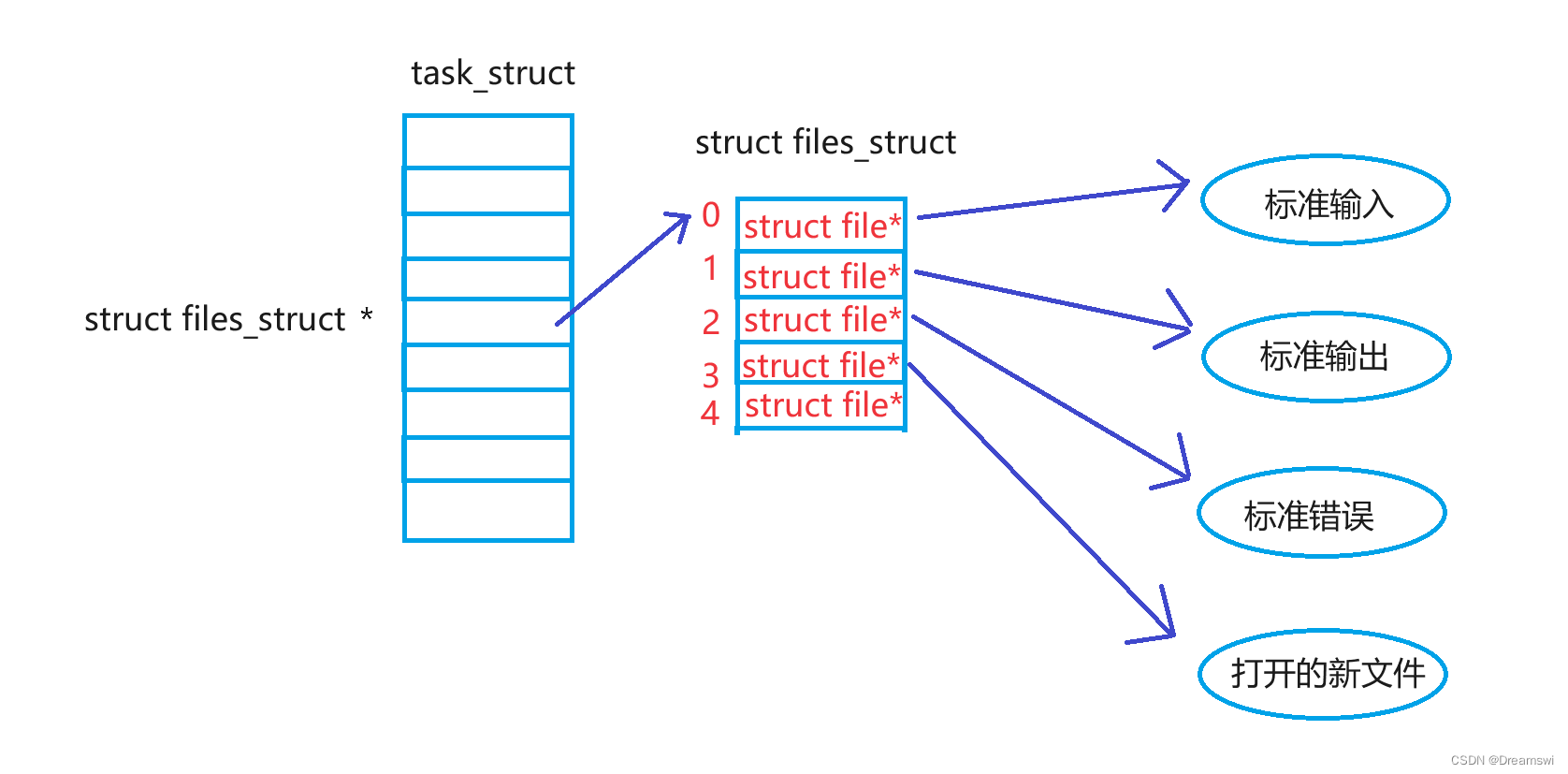
- 使用ls -l的时候看到的除了看到文件名,还看到了文件元数据


- 当我们创建一个文件,操作系统做了什么
- 找到自己的目录,找到目录的inode,然后找到目录的Date Block。
- 这里有文件名和inode的映射关系,文件名在该目录下的唯一性,根据文件名做查找,找到了inode编号。
- 根据inode编号找到block group,然后只要把该文件对应的inode Bitmap由1置0。
- 将这个文件对应的Block Bitmap数据块由1置0,此时就完成了文件删除
- 请问删除一个文件,OS做了什么?
- Linux并没有真正的清除数据:
- 删除的时候,只是将标记该文件对应的属性和数据块的相关位图结构由1置0,就完成了删除。
- 最后在文件所处的目录当中,把该文件对应的inode映射关系去掉,此时这个文件就被删除了
- ls的工作过程?
- ls找到目录对应的inode编号,根据inode编号找到inode。
- inode里面有属性,属性里面有数据块和inode的映射关系。
- 找到数据块,只把数据块中文件名列出来就完了。
2. 软硬链接
在我们Linux刚开始学习的时候,我们有一个链接数是没有讲的:

2. 1 硬链接
系统真正找到磁盘上文件的并不是文件名,而是inode。 其实在linux中可以让多个文件名对应于同一个 inode
在Linux系统中,多个文件名可以指向相同的数据块,这些文件名被称为文件的硬链接。
硬链接是文件系统中的链接,它们具有相同的inode号,并且它们引用相同的文件内容。
每当创建一个硬链接时,文件的硬链接计数增加1。相反,当删除一个硬链接时,硬链接计数减少1。只有在硬链接计数为0时,文件才被真正删除,释放相关的存储空间。
因此,文件的硬链接个数表示有多少个文件名指向同一份数据。当硬链接计数为1时,说明该文件没有其他硬链接,即它是唯一指向该数据的文件
1.目录和文件的硬链接数
当我们创建目录或文件时,我们看到的是:目录默认的硬链接数是2,而文件默认的硬链接数是1。
目录至少有两个硬链接,一个是它自己的记录(“.”),另一个是指向该目录的父目录的记录(“. .”)
设计的目的是为了在文件系统中建立层次结构,并保证文件系统的完整性
默认情况下,文件在创建时只会有一个硬链接,即它的原始文件名
2.硬链接的好处
硬链接没有独立的Inode–>硬链接不是一个独立的文件,不是真正的创建新文件
创建硬链接,究竟做了什么呢? 就是在指定的目录下,建立了文件名和指定Inode的映射关系—仅此而已
3.硬链接的使用场景
硬链接的主要使用场景,路径间切换,比如:进行文件路径切换上,cd .和cd…,更好的进行文件层次结构。。
创建硬链接的命令:
ln 源文件 目标文件
% #创建硬链接
2. 2 软链接
软连接就相当于Linux下的快捷方式(ln: link的简称)
1 .软链接的使用场景
-可用来 链接可执行程序、库文件(动静态库),这样就不用我们很冗余的去找这些库。
创建软链接的命令:
ln -s 源文件 目标文件
% #创建软链接

发现软连接的inode和原来的inode不同,而硬连接的inode则是与原来相同
2. 3 软硬连接的区别:
软连接:
- 软连接是一个独立文件,有自己独立的inode和inode编号。
- Linux下的快捷方式!
- 既然是一个独立文件,inode是独立的,软连接的文件内容是什么呢??
- 保存的是指向的文件的所在路径!!
在系统级别保存的,我们开是看不到的。
硬连接:
- 硬链接不是一个独立文件,他和目标文件使用的是同一个inode!
- 硬链接本质上,相当于在当前目录下重新建立了文件名和inode之间的映射关系。
- 硬链接不是一个独立的文件,它是与原始文件共享相同的inode和数据块。
- 硬链接与原始文件在文件系统中指向同一个数据块,它们是同一个文件的多个文件名。
- 如果修改了原始文件的内容或属性,所有与之相关联的硬链接文件都会反映这些更改
尾声
看到这里,相信大家对这个Linux 有了解了。
如果你感觉这篇博客对你有帮助,不要忘了一键三连哦




























![鸿蒙 arkts 实现手机号中间四位隐藏, 可以使用 substring [ 简单适用新手 ]](https://i-blog.csdnimg.cn/direct/d2298ce63d2748e8b3ace1d71f937dbc.png)