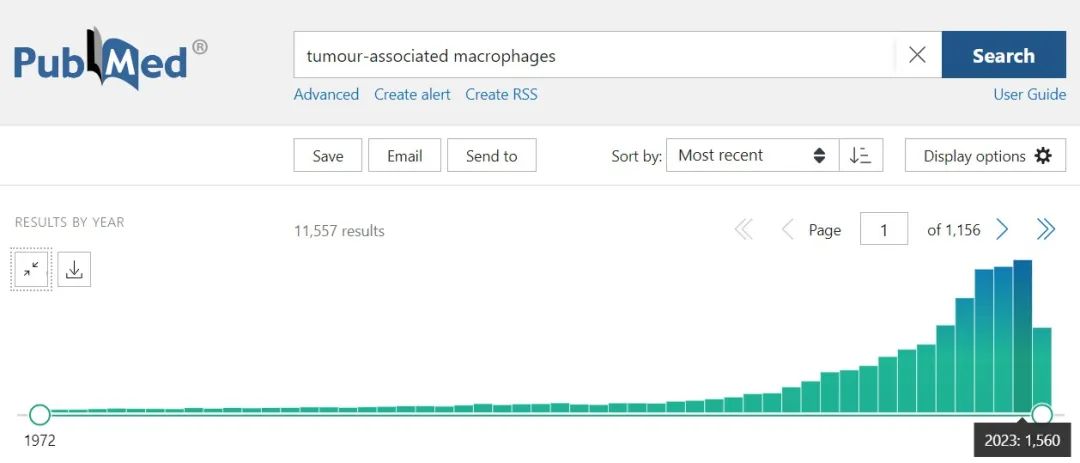
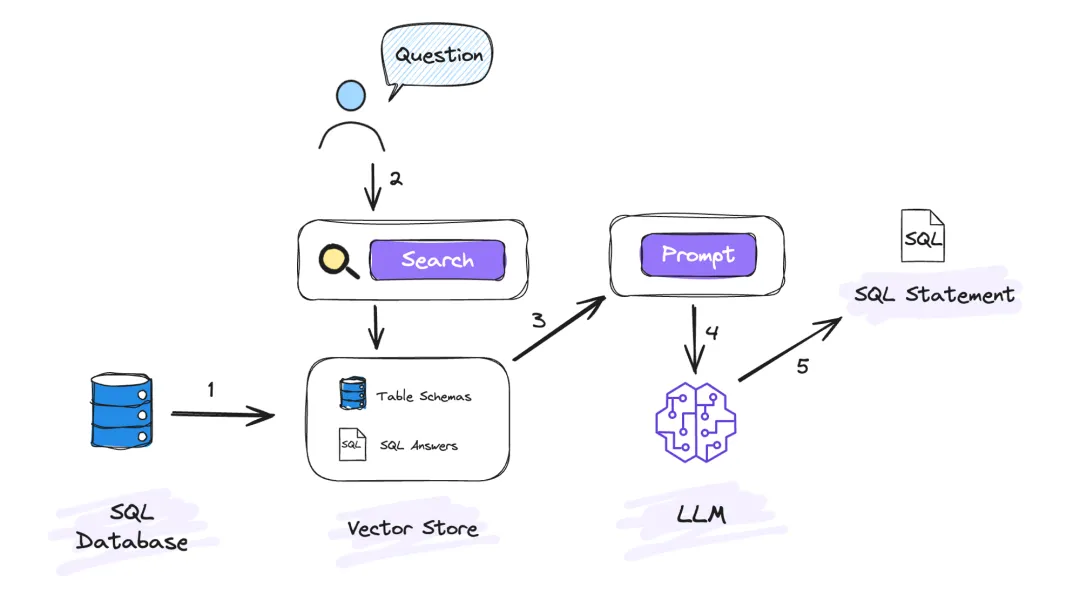
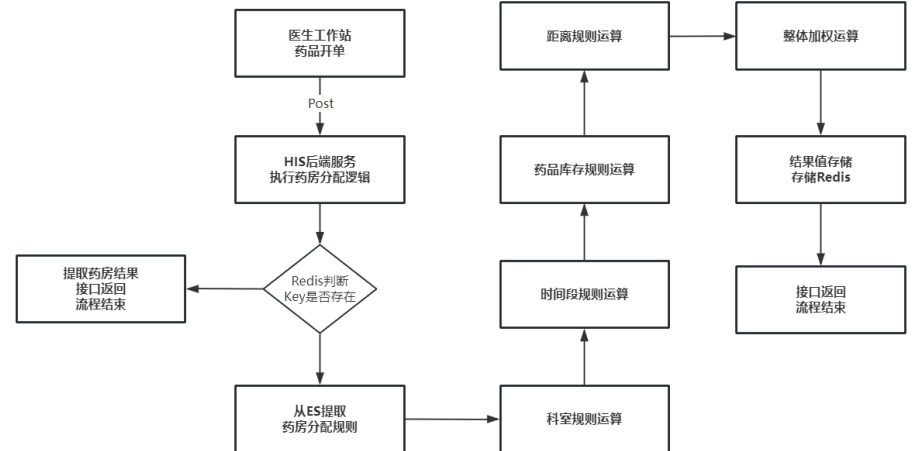
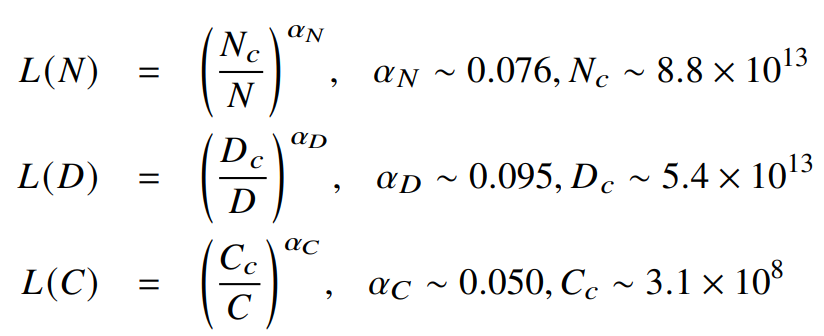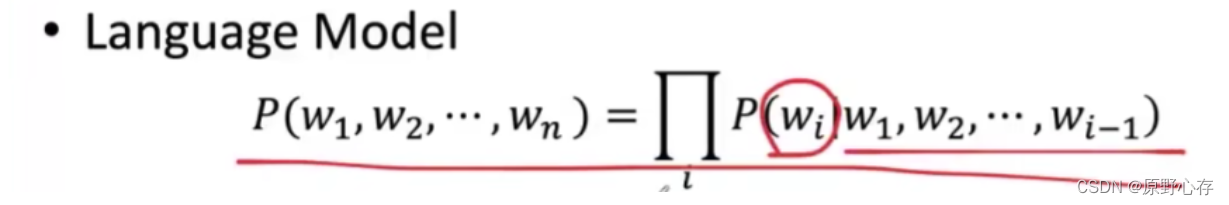过程图如下

📚 第一步:海量文本的无监督学习 得到基座大模型🎉
🔍 原料:首先,我们需要海量的文本数据,这些数据可以来自互联网上的各种语料库,包括书籍、新闻、科学论文、社交媒体帖子等等。这些文本将作为模型的“原料”,供模型学习。
🎯 目标:通过无监督学习,让模型能够基于上下文预测下一个token。这里用到了Transformer技术,它可以根据上下文预测被掩码的token。
💡 技术过程:无监督学习让模型在没有标签的数据上进行训练,通过比较正确答案和模型的预测结果,计算交叉熵损失,并使用优化算法更新模型的权重。随着见过的文本越来越多,模型生成的能力也会越来越好。
🔧 第二步:有监督微调➡️得到可以对话的大模型🎉
🔍 原料:虽然基座模型已经能够根据上下文生成文本,但它并不擅长对话。为了解决这个问题,我们需要使用人类撰写的高质量对话数据对基座模型进行有监督微调。
🎯 目标:通过微调,让模型更加适应对话任务,具备更好的对话能力。
💡 过程:微调的成本相对较低,因为需要的训练数据规模更小,训练时长更短。在这一阶段,模型从人类高质量的对话中学习如何回答问题,这个过程被称为监督微调(supervised fine tuning)。
思考:为啥是“微调”而不叫“中调”或者“大调”?因为相比于基座模型所用到的巨量数据,这个过程里的大部分有监督学习,其所用到的数据,都像是冰山之一角,九牛之一毛!
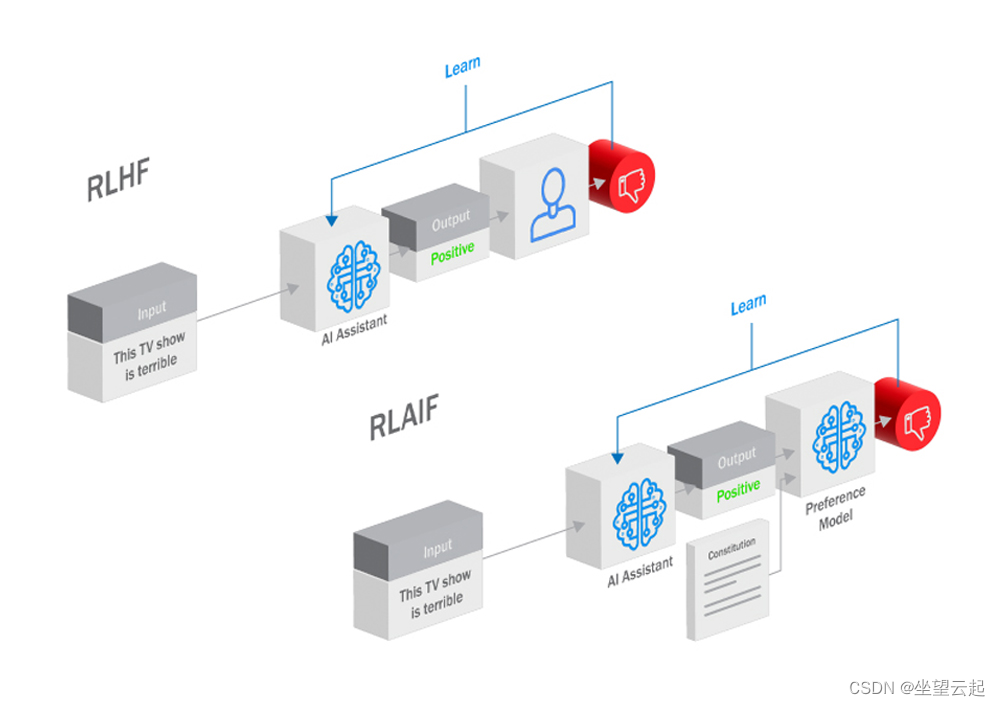
🏆 第三步:奖励模型的训练➡️得到可以评价回答的模型🎉
🔍 原料:为了让模型的回答更加优质且符合人类道德与价值观,我们需要让模型一次性给出多个回答结果,并由人工对这些回答结果进行打分和排序。
🎯 目标:基于这些以评分作为标签的训练数据,训练出一个能对回答进行评分预测的奖励模型。
💡 过程:奖励模型能够对模型的回答进行评分,从而引导模型生成更符合人类期望的回答。这个过程也常被称为对齐(alignment)。
🎈 第四步:强化学习训练➡️得到更符合人类价值观的优秀模型🎉
🔍 原料:使用第二步得到的模型和第三步的奖励模型进行强化学习训练。
🎯 目标:让模型的回答不断被奖励模型评价,并通过优化策略获取更高的评分,从而改进自身的结构。
💡 过程:强化学习训练利用奖励模型的评分作为反馈信号,引导模型生成更高质量的回答。同时,C端用户的点赞或倒赞也为模型的升级提供了宝贵的评价数据
接下来我们用LLM来讲解。第一步:通过无监督学习得到基座大模型

第二步:通过监督学习得到微调后的基座大模型

第三步:通过人工评价和有监督学习得到评价模型

第四步:通过强化学习不断提升模型回复质量