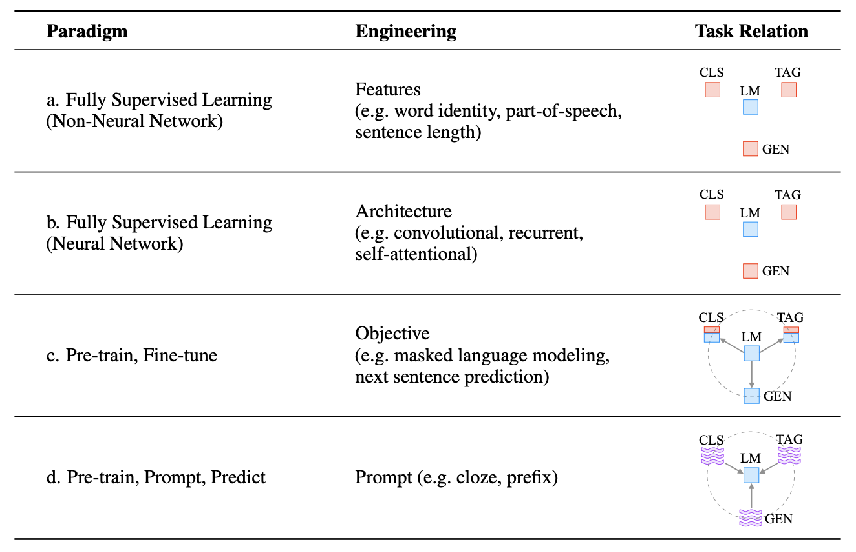
在LLM(Language Model)中,Transformer是一种用来处理自然语言任务的模型架构。下面是Transformer模型中的调用过程和步骤的简要介绍:
数据预处理:将原始文本转换为模型可以理解的数字形式。这通常包括分词、编码和填充等操作。
嵌入层(Embedding Layer):将输入的词索引转换为稠密的词向量。Transformer中,嵌入层有两个子层:位置编码和嵌入层。
编码器(Encoder):Transformer由多个编码器堆叠而成。每个编码器由两个子层组成:自注意力层(Self-Attention Layer)和前馈神经网络层(Feed-Forward Neural Network Layer)。
自注意力层:通过计算输入序列中单词之间的相互关系,为每个单词生成一个上下文相关的表示。自注意力层的输入是词嵌入和位置编码,输出是经过自注意力计算的编码。
前馈神经网络层:通过对自注意力层的输出进行一系列线性和非线性变换,得到最终的编码输出。
解码器(Decoder):与编码器类似,解码器也是多个堆叠的层,每个层由三个子层组成:自注意力层、编码器-解码器注意力层(Encoder-Decoder Attention Layer)和前馈神经网络层。
编码器-解码器注意力层:在解码器中,这一层用于获取编码器输出的信息,以帮助生成下一个单词的预测。
线性和softmax层:通过线性变换和softmax激活函数,将最终的解码器输出转换为预测的词序列。
下面是少量代码示例,展示如何在PyTorch中使用Transformer模型:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Transformer
class TransformerModel(nn.Module):
def __init__(self, vocab_size, embed_dim, num_heads, num_layers):
super(TransformerModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.transformer = nn.Transformer(d_model=embed_dim, nhead=num_heads, num_encoder_layers=num_layers)
def forward(self, src):
src_embed = self.embedding(src)
output = self.transformer(src_embed)
return output
在LLM (Language Model) 中的Transformer模型中,通过以下步骤进行调用:
- 导入必要的库和模块:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
- 加载预训练模型和分词器:
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
在这个例子中,我们使用了gpt2预训练模型和对应的分词器。
- 处理输入文本:
input_text = "输入你想要生成的文本"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
使用分词器的encode方法将输入文本编码为模型可接受的输入张量。
- 生成文本:
outputs = model.generate(input_ids, max_length=100, num_return_sequences=5)
使用模型的generate方法生成文本。input_ids是输入张量,max_length指定生成文本的最大长度,num_return_sequences指定生成的文本序列数量。
- 解码生成的文本:
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
使用分词器的decode方法将模型生成的输出张量解码为文本,并打印生成的文本。
在LLM中,有几个关键的概念需要理解:
- Logits:在生成文本时,模型会计算每个词的概率分布,这些概率分布被称为logits。模型生成的文本会基于这些logits进行采样。
- Tokenizer:分词器将输入的连续文本序列拆分为模型能够理解的词元(tokens)。它还提供了把模型的输出转化回文本的方法。
- Model:模型是一个神经网络,它经过预训练学习了大量的文本数据,并能够生成和理解文本。
Prompt是指在生成文本时提供给模型的初始提示。例如,给模型的输入文本是:“Once upon a time”,那么模型可能会继续生成:“there was a beautiful princess”. Prompt可以被用来引导模型生成特定的风格或内容的文本。
下面是一个完整的示例:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
input_text = "Once upon a time"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
outputs = model.generate(input_ids, max_length=100, num_return_sequences=5)
for output in outputs:
generated_text = tokenizer.decode(output, skip_special_tokens=True)
print(generated_text)
这个示例将生成以"Once upon a time"为初始提示的文本序列,并打印出5个生成的文本序列。






















![[word] word 怎样批量把英文单词的首字母全部改成大写 #笔记#其他#学习方法](https://img-blog.csdnimg.cn/img_convert/9559336c24faba667b567449851cdce9.jpeg)

![[word] word定时自动保存功能的作用是什么 #知识分享#学习方法#媒体](https://img-blog.csdnimg.cn/img_convert/2834e946cc20418af917dbcd567bf8ab.jpeg)
![[word] word中图片衬于文字下方无法显示 #媒体#微信](https://img-blog.csdnimg.cn/img_convert/2a52d33098adfb341ea9bcefc563da21.png)