1.Word2Vec
Word2Vec 是一种将词语表示为向量的技术,能够捕捉词语之间的语义关系。它由 Google 的 Tomas Mikolov 等人在 2013 年提出,广泛应用于自然语言处理任务中。其核心概念主要包括:
词嵌入(Word Embeddings)
词嵌入是将词语映射到一个固定大小的向量空间中,使得在语义上相似的词在向量空间中也相互接近。Word2Vec 通过神经网络模型生成词嵌入。
模型架构
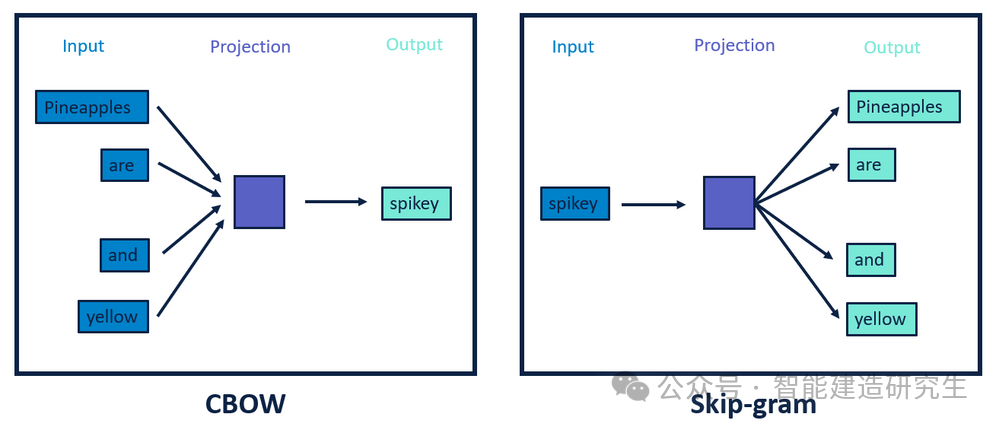
Word2Vec 主要有两种模型架构:
CBOW(Continuous Bag of Words):给定一个词的上下文,预测中心词。例如,给定上下文 ["The", "cat", "on", "the", "mat"],目标词是 "sat"。
Skip-gram:给定一个词,预测其上下文。例如,目标词是 "sat",上下文是 ["The", "cat", "on", "the", "mat"]。
工作原理
CBOW 模型
CBOW 模型通过上下文词预测中心词。其工作原理如下:
输入层接受上下文词的词向量,将这些词向量求平均,得到一个上下文表示。
隐藏层将上下文表示映射到一个新的空间。
输出层使用 softmax 函数预测中心词的概率分布,选择概率最大的词作为预测结果。
Skip-gram 模型
Skip-gram 模型通过中心词预测上下文词。其工作原理如下:
输入层接受中心词的词向量。
隐藏层将中心词词向量映射到一个新的空间。
输出层使用 softmax 函数预测上下文词的概率分布,选择概率最大的词作为预测结果。
训练过程
Word2Vec 的训练过程包括以下几个步骤:
语料库准备:收集并预处理大量文本数据,将其分词,并去除低频词和停用词。
模型初始化:初始化词向量矩阵和模型参数。
前向传播:将输入词通过神经网络进行前向传播,计算预测的上下文词或中心词。
损失计算:计算预测结果与实际标签之间的损失。
反向传播:通过反向传播算法更新词向量和模型参数。
迭代训练:重复上述过程,直至模型收敛。
2. Gensim

Gensim 是一个开源的 Python 库,用于从非结构化文本数据中提取语义信息,主要应用于自然语言处理(NLP)领域。它提供了高效的工具和算法来实现主题建模、文档相似性分析、词嵌入等任务。其核心功能主要包括:
Gensim 提供了多种强大的 NLP 功能,包括但不限于:
词嵌入(Word Embeddings):
支持 Word2Vec、FastText、Glove 等词嵌入模型。
可以从文本语料库中训练词向量,或加载预训练的词向量。
主题建模(Topic Modeling):
支持 Latent Dirichlet Allocation (LDA)、Latent Semantic Indexing (LSI)、Hierarchical Dirichlet Process (HDP) 等主题模型。
可以从文档集合中提取主题,分析文档的主题分布。
文档相似性分析(Document Similarity):
提供相似性检索工具,可以计算文档与文档、文档与查询之间的相似性。
文本预处理(Text Preprocessing):
包括分词、去停用词、词干提取、词频计算等功能。
3. Python实现
以下代码使用 Gensim 库中的 Word2Vec 模型对分词后的文本数据进行训练,并实现以下功能:
加载分词语料文件
word.txt。训练一个向量维度为200的skip-gram模型。
计算并打印两个单词"企业"和"公司"的相似度。
查找并打印与"科技"最相关的20个词。
通过词向量计算,寻找与"公司-产品+生产"关系最相关的词。
查找并打印在"企业 公司 是 合作伙伴"中最不合群的词。
将训练好的模型保存为
企业关系.model。
这段代码展示了如何使用 Word2Vec 模型进行文本数据的相似性计算和关系分析。
# 导入包
from gensim.models import word2vec
import logging
# 初始化日志
logging.basicConfig(format='%(asctime)s:%(levelname)s:%(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus("files/data/python32-data/word.txt") # 加载分词语料
# 训练skip-gram模型,使用vector_size参数替代size
model = word2vec.Word2Vec(sentences, vector_size=200) # 默认window=5
print("输出模型", model)
# 计算两个单词的相似度
try:
y1 = model.wv.similarity("企业", "公司")
except KeyError:
y1 = 0
print("【企业】和【公司】的相似度为:{}\n".format(y1))
# 计算某个词的相关词列表
y2 = model.wv.most_similar("科技", topn=20) # 20个最相关的
print("与【科技】最相关的词有:\n")
for word in y2:
print(word[0], word[1])
print("*********\n")
# 寻找对应关系
print("公司-产品", "生产")
y3 = model.wv.most_similar(positive=["公司", "产品"], negative=["生产"], topn=3)
for word in y3:
print(word[0], word[1])
print("*********\n")
# 寻找不合群的词
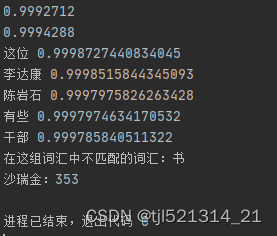
y4 = model.wv.doesnt_match("企业 公司 是 合作伙伴".split())
print("不合群的词:{}".format(y4))
print("***********\n")
# 保存模型
model.save("files/data/python32-data/企业关系.model")
输入数据:

输出结果:
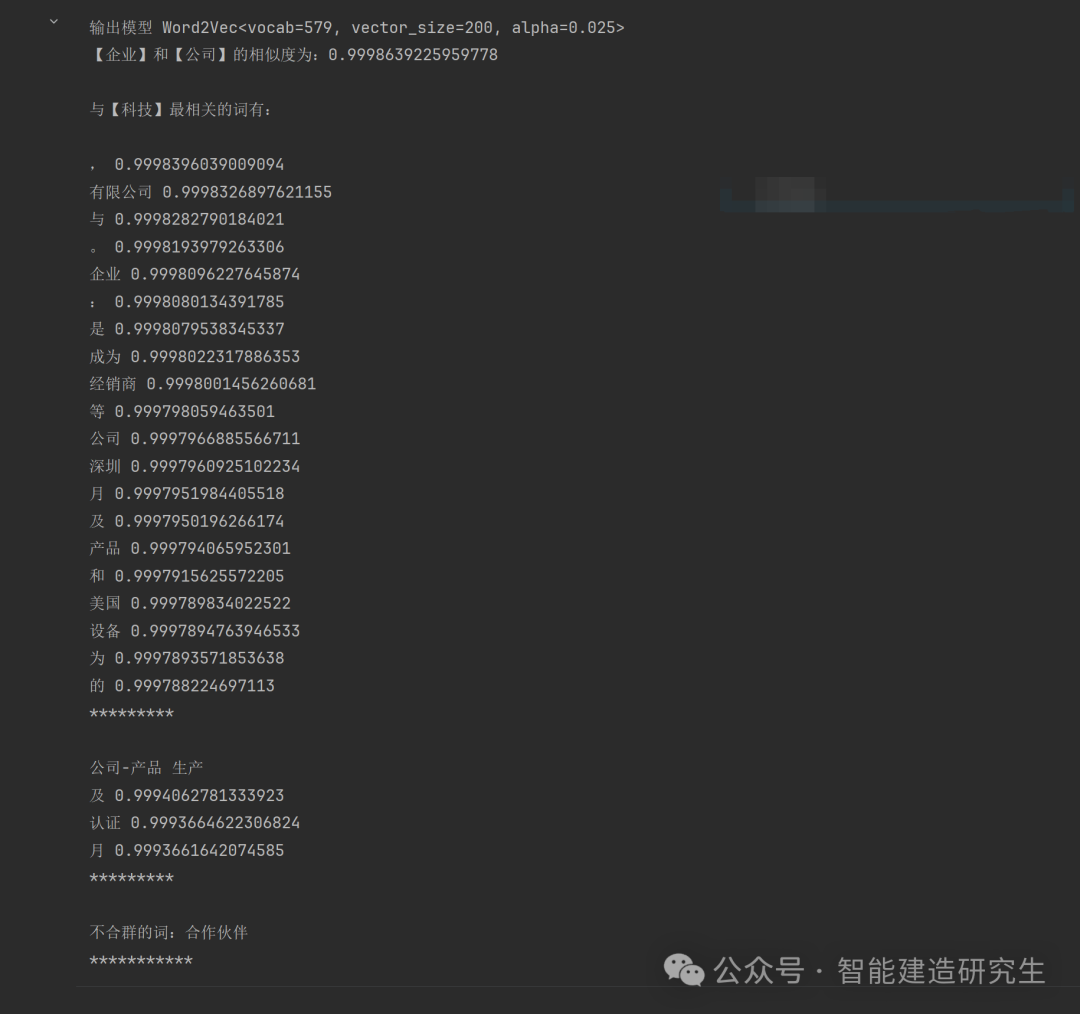
通过 Gensim 的 Word2Vec 模型对给定文本数据进行了训练,生成了词向量,并通过计算词语相似度、相关词、对应关系、不合群的词等方法对词向量进行了分析和应用。
以上内容总结自网络,如有帮助欢迎转发,我们下次再见!

























![赛蓝企业管理系统GetExcellTemperature接口SQL注入漏洞复现 [附POC]](https://i-blog.csdnimg.cn/direct/77781be74d434297ad6ab02d1619dc1c.png)














