机器学习之常用优化器
1、SGD 优化器
在 PyTorch 中,设置 SGD 优化器很直接。可以设置的关键参数,如学习率(lr)、动量(momentum)、权重衰减(weight decay)等,以帮助改善训练过程中的收敛速度和最终模型的泛化能力。
1.1、示例代码
from torch.optim import SGD
# 假设 model 是您的模型实例
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=1e-6)
相关参数解释:
- lr (learning rate): 学习率控制着权重调整的幅度,即步长。如果学习率太高,训练可能会在最优解附近震荡或者完全偏离;如果学习率太低,训练过程可能会非常慢。
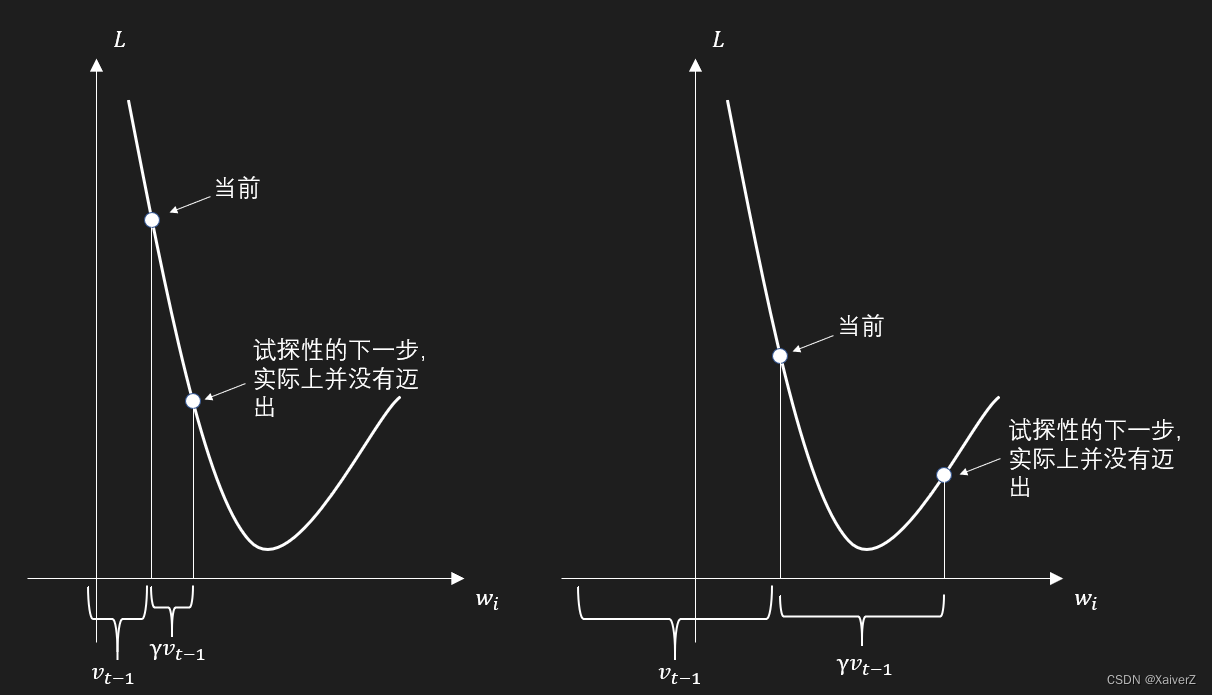
- momentum: 动量帮助优化器在相关方向上持续前进,从而加快收敛,并减少震荡。
- weight_decay: 权重衰减是一种正则化技术,可以防止模型过拟合。它通过在损失函数中添加一项与权重大小成比例的成本来工作。
在训练循环中使用 SGD 优化器进行参数更新:
# 训练模型的一个epoch
model.train() # 将模型设置为训练模式
for inputs, targets in train_loader: # 假设 train_loader 是您的数据加载器
optimizer.zero_grad() # 清除之前的梯度
outputs = model(inputs) # 获得模型的预测结果
loss = loss_function(outputs, targets) # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
1.2、 SGD 的优缺点
优点:
- 简单且易于实现。
- 在许多情况下效果很好,尤其是数据集很大时。
缺点:
- 对学习率和其他超参数比较敏感。
- 可能需要更多的epoch来收敛。
- 在高维空间中,SGD的收敛速度可能较慢,尤其是在参数空间存在很多不敏感的方向时。
在实际应用中,选择哪种优化器往往取决于具体的任务和模型。对于一些复杂的或非凸的优化问题,可能会考虑使用带有自适应学习率的优化器,如 Adam 或 RMSprop,它们能够在不同的训练阶段自动调整学习率,通常在实践中更容易获得好的性能。然而,SGD 由于其简单性和有效性,在许多问题上仍是一个非常有价值的选择。
2、 Adam 优化器
使用 Adam 优化器是深度学习训练中的一种常见选择,特别是当你需要一个鲁棒且自适应的优化策略时。Adam 优化器结合了 RMSprop 和 Momentum 两种优化算法的优点,通过计算梯度的一阶矩(均值)和二阶矩(未中心化的方差)来调整每个参数的学习率。这种方法使得它特别适用于处理非稳定目标函数和非常大的数据集或参数数量。
2.1、设置 Adam 优化器
在 PyTorch 中,设置 Adam 优化器可以通过以下方式:
from torch.optim import Adam
# 假设 model 是您的模型实例
# T_lr 是您定义的学习率变量
optimizer = Adam(model.parameters(), lr=T_lr)
相关参数解释如下:
- lr (learning rate): 学习率决定了参数更新的幅度。对于 Adam,通常会设置一个较小的值,如
1e-3或1e-4,因为 Adam 自身的调整机制已经非常有效。 - betas: 一个元组
(beta1, beta2),用于计算梯度及其平方的运行平均值;默认值通常是(0.9, 0.999)。 - eps: 用于数值稳定性的小常数,防止在计算中出现除以零的错误;默认值为
1e-8。 - weight_decay: 权重衰减系数,这在正则化和防止过拟合中非常有用;类似于 L2 正则化。
- amsgrad: 一个布尔值,表明是否使用 AMSGrad 变种的 Adam 算法,据说可以提高该算法的收敛性,防止过早停滞。
2.2、使用 Adam 优化器的训练流程
以下是一个标准的训练循环,展示了如何使用 Adam 进行参数更新:
# 训练模型
model.train() # 确保模型处于训练模式
for epoch in range(num_epochs): # num_epochs 是总的迭代周期数
for inputs, targets in train_loader: # 假设 train_loader 是您的数据加载器
optimizer.zero_grad() # 清空之前的梯度
outputs = model(inputs) # 计算模型输出
loss = loss_function(outputs, targets) # 计算损失函数
loss.backward() # 反向传播,计算当前梯度
optimizer.step() # 根据梯度更新网络参数
print(f"Epoch {epoch+1}, Loss: {loss.item()}") # 打印损失
2.3、Adam 优化器的优缺点
优点:
- 自适应学习率使得参数调整更加灵活和高效。
- 非常适合处理大数据集和高维空间。
- 较少的调整学习率的需求。
缺点:
- 相对于简单的 SGD,计算资源消耗更大。
- 在某些情况下,如非常深的网络或复杂的架构中,可能不如 SGD 配合学习率衰减策略稳定。
Adam 由于其自适应性强、实现简单且通常性能优良,成为许多深度学习应用的默认选择。确保根据您的具体任务需求调整优化器的参数,以便最大化模型的性能和效率。对于不同的任务和模型结构,可能需要进行一些试验和错误调整,以找到最佳的超参数设置。
3. AdamW 优化器
AdamW 是一种改进的 Adam 优化算法,它对 Adam 的权重衰减组件进行了修改,使得权重衰减不再是添加到梯度上而是直接对参数进行更新。这种方法与 L2 正则化的原理更为接近,通常可以带来更好的训练稳定性和泛化性能。
3.1、示例
在 PyTorch 中,AdamW 的使用与 Adam 非常相似,但它通常被认为是一种更适合带权重衰减的场景的优化器,特别是在深度学习中。这是因为它可以更有效地控制模型的过拟合。optim.AdamW 是一个优化器,它结合了 Adam 优化器和权重衰减(L2 正则化)。它有助于防止模型过拟合,并在训练过程中提高模型的泛化能力。
model.parameters(): 这是模型参数的迭代器,AdamW将使用这些参数来计算梯度并更新权重。
from torch.optim import AdamW
# 假设 model 是您的模型实例
# T_lr 是定义的学习率
# weight_decay 是权重衰减系数,常用于正则化
optimizer = AdamW(model.parameters(), lr=T_lr, weight_decay=0.01)
相关参数解释如下:
- lr (learning rate):控制优化器步长的大小,即每次参数更新的幅度。
- weight_decay:权重衰减(L2正则化)系数,用于正则化和避免过拟合。在
AdamW中,这个参数是直接在权重更新时应用的,而不是作为梯度的一部分。这个值越高,正则化的效果越强,可以帮助减少模型的复杂度,从而减少过拟合。
3.2、训练过程
使用 AdamW 优化器的训练过程与其他优化器类似,但由于其处理权重衰减的方式,它可能在需要正则化以提高模型泛化能力的任务中表现得更好。
# 训练模型
model.train() # 确保模型处于训练模式
for epoch in range(num_epochs): # num_epochs 是总的迭代周期数
for inputs, targets in train_loader: # 假设 train_loader 是您的数据加载器
optimizer.zero_grad() # 清空之前的梯度
outputs = model(inputs) # 计算模型输出
loss = loss_function(outputs, targets) # 计算损失函数
loss.backward() # 反向传播,计算当前梯度
optimizer.step() # 根据梯度更新网络参数
print(f"Epoch {epoch+1}, Loss: {loss.item()}") # 打印损失
3.3、AdamW 优化器的优点
- 更有效的正则化:由于其更新权重衰减的方式,
AdamW可以更有效地进行正则化,避免深度学习模型中常见的过拟合问题。 - 改善泛化:与传统的
Adam相比,AdamW在多个基准测试中显示出更好的泛化能力。 - 易于集成:
AdamW可以轻松替换Adam优化器,无需改动其他代码,提供了一种简单的提升模型性能的方式。
AdamW 适用于几乎所有使用 Adam 的场景,特别推荐在易于过拟合的大模型和复杂任务中使用。由于其改进的权重衰减机制,它特别适合需要正则化的应用,如在小数据集上训练的深度网络。在选择优化器时,如果你已经计划使用 Adam 并关注模型的泛化,不妨试试 AdamW。